Analyzing Health Development Data in East Asia & Pacific Region
VerifiedAdded on 2020/06/04
|19
|2668
|116
Project
AI Summary
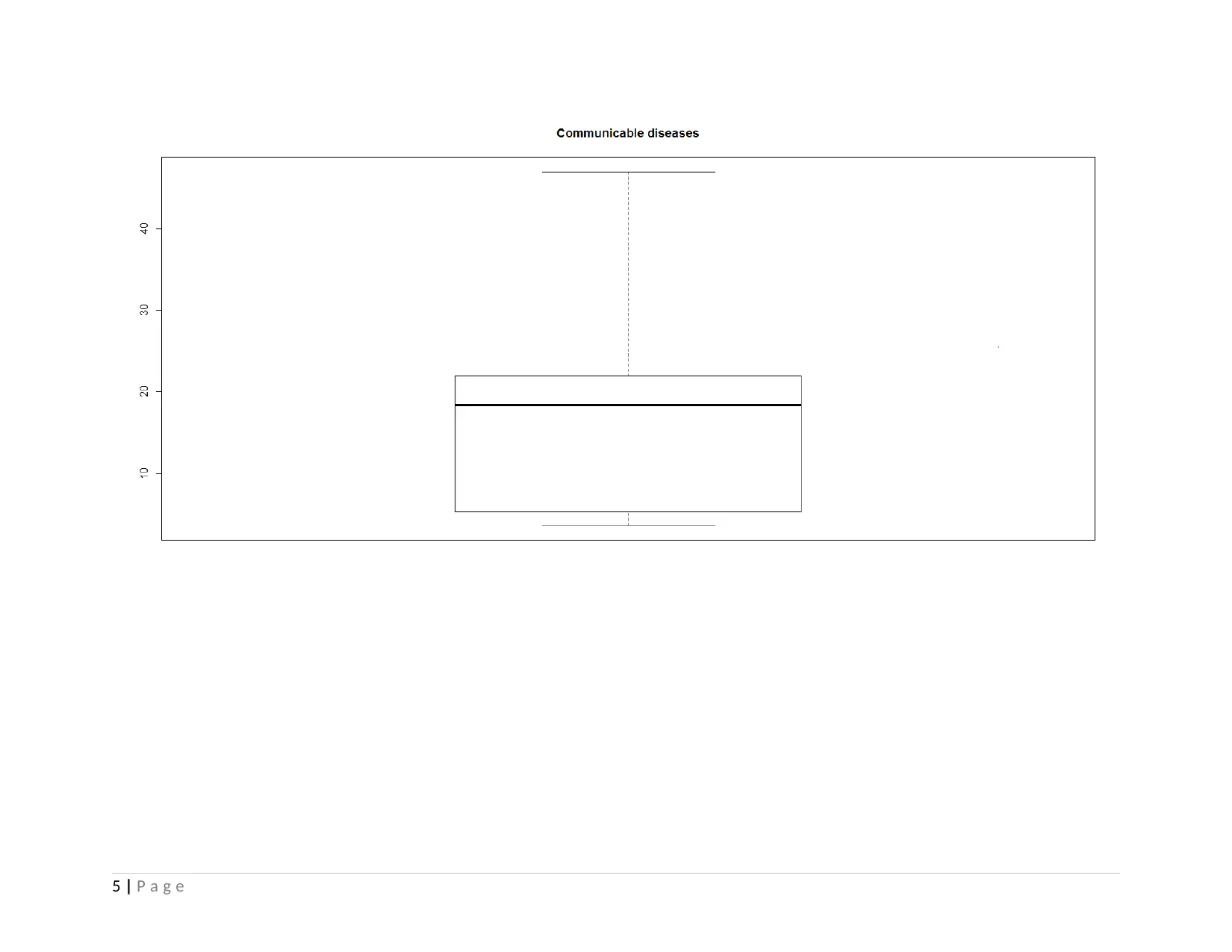
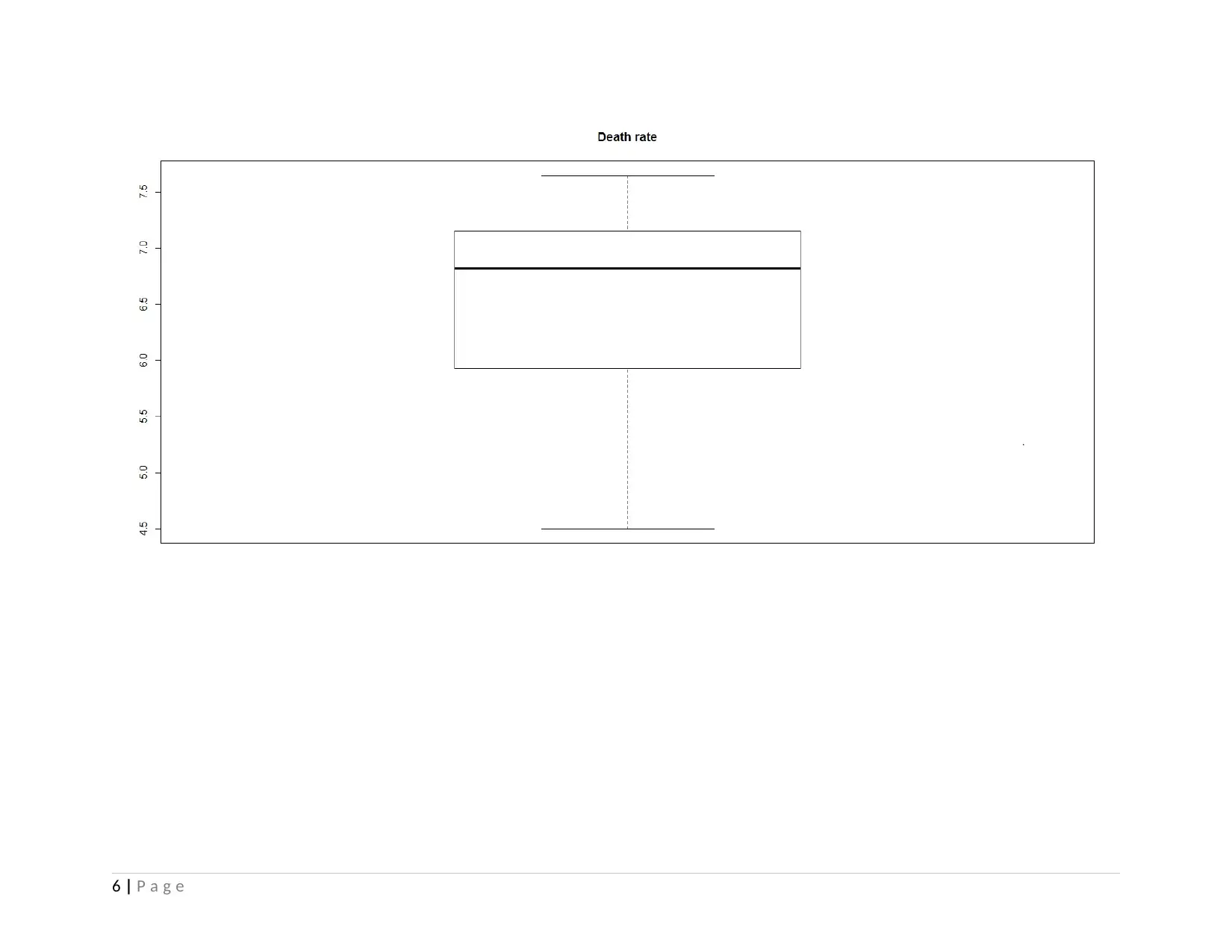
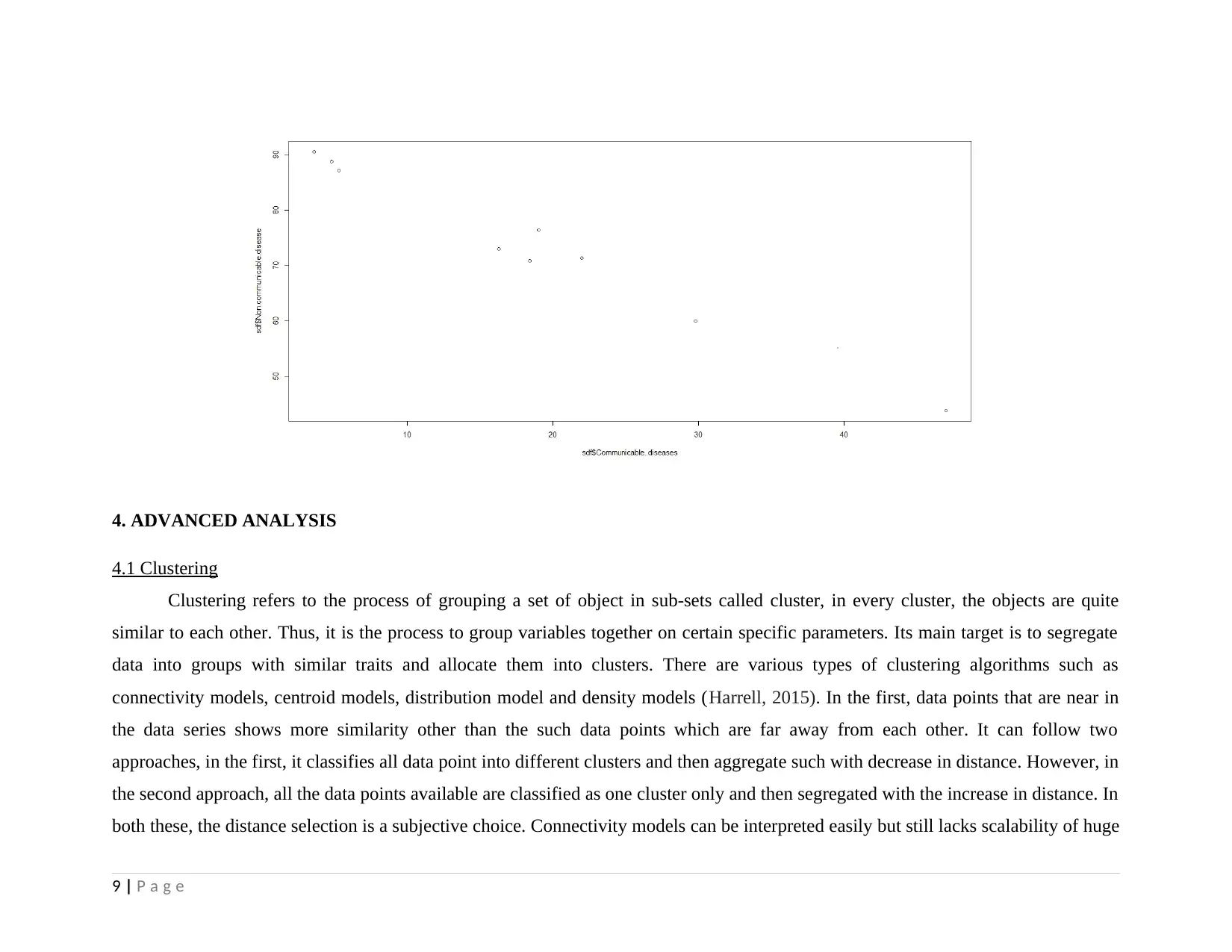
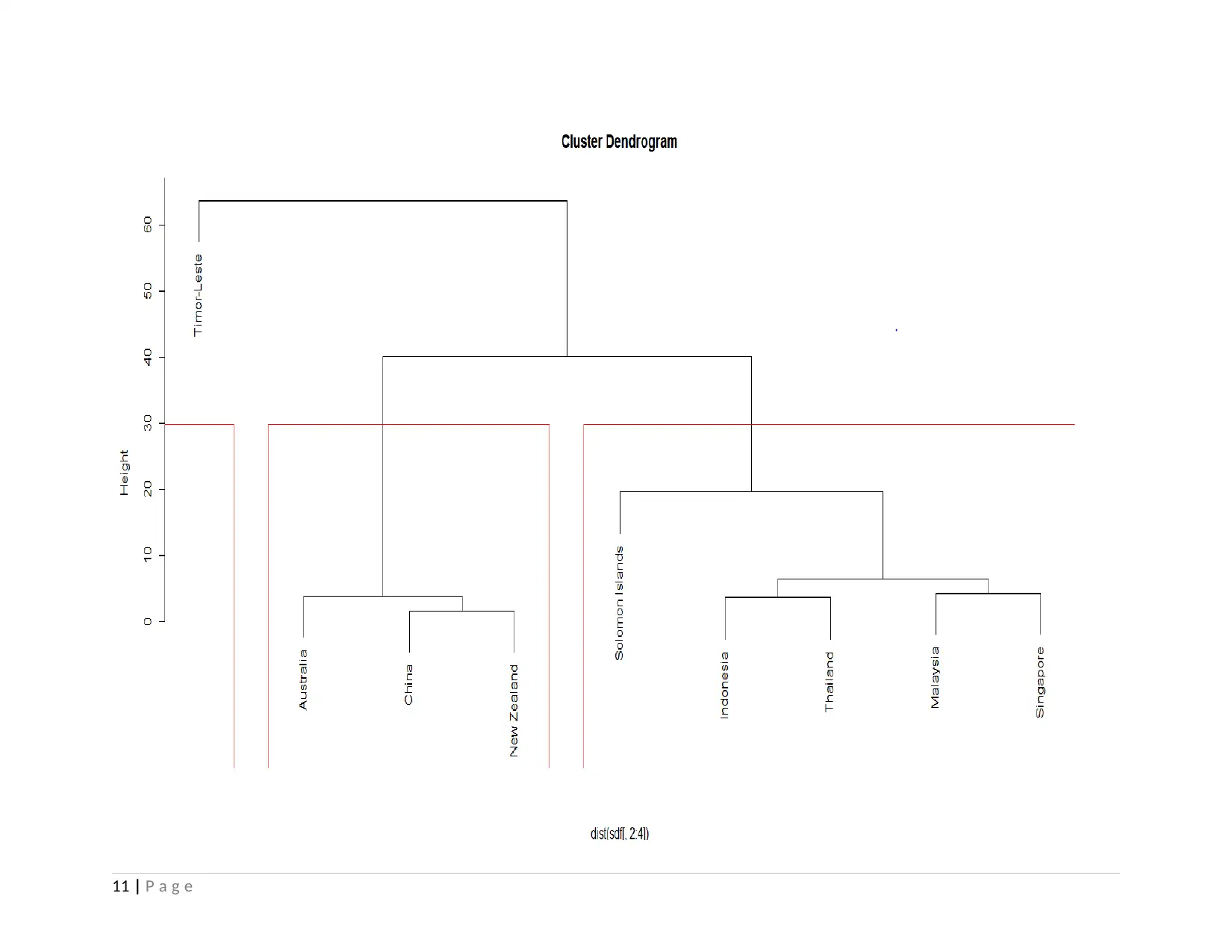
This project analyzes health and population statistics from the World Bank for countries in East Asia and the Pacific from 2001 to 2015. The project examines datasets including birth rates, death rates, immunization, and other health indicators across ten countries: Australia, China, Indonesia, Malaysia, New Zealand, Palau, Singapore, Solomon Islands, Thailand, and Timor-Leste. The analysis begins with exploratory data analysis (EDA), employing summary statistics, and graphical representations to understand the data's characteristics. Bivariate analysis is performed using correlation and covariance to determine relationships between variables like death rates and communicable/non-communicable diseases. Advanced analysis techniques, including clustering and linear regression, are then applied to identify patterns and quantify relationships. Clustering groups countries with similar health profiles, while linear regression assesses the impact of communicable and non-communicable diseases on death rates. The study concludes that death rates are not significantly affected by communicable and non-communicable diseases and suggests that healthcare strategies can be tailored for countries that share similar characteristics. The student faced challenges in data organization and R code execution, which were overcome using Excel and further study.








1 out of 19
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.