USC: Health & Population Statistics Data Analysis East Asia & Pacific
VerifiedAdded on 2023/06/11
|20
|3160
|304
Report
AI Summary
This report presents a data analysis of health and population statistics in East Asia and the Pacific region from 2001 to 2015, using data from the World Bank. The analysis includes one-variable, two-variable, and advanced statistical methods such as k-means clustering and linear regression to investigate trends in immunization rates, birth rates, and school enrollment. The report finds variations in immunization and birth rates across countries, identifies clusters based on these factors, and explores the relationship between birth rates and immunization, as well as birth rates and school enrollment. The findings offer insights for governments and planners aiming to improve health outcomes in the region.

Data analysis report of the health and population statistics of East Asian and Pacific countries
Name of the Student
Name of the Student
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Table of Contents
1 Introduction..................................................................................................................................1
1.1 Authorisation and Purpose...............................................................................................1
Limitations...................................................................................................................................1
Scope............................................................................................................................................1
Methodology...............................................................................................................................1
2 Data Setup....................................................................................................................................1
3 Exploratory Data Analysis.............................................................................................................2
3.1 One Variable Analysis................................................................................................................2
3.1.1 One Variable Analysis – 1.......................................................................................................2
3.1.2 One Variable Analysis – 2.......................................................................................................3
3.1.3 One Variable Analysis – 3.......................................................................................................6
3.2 Two-variable analysis.................................................................................................................7
3.2.1 Two-variable analysis 1...........................................................................................................7
3.2.2 Two-variable analysis 2...........................................................................................................8
4 Advanced analysis.......................................................................................................................10
4.1 Clustering.................................................................................................................................10
4.1.1 Brief explanation of k-means and clustering........................................................................10
4.1.2 Clustering Analysis................................................................................................................11
4.2 Linear regression......................................................................................................................12
4.2.1 Brief definition of linear regression......................................................................................12
4.2.2 Linear Regression 1...............................................................................................................13
4.2.3 Linear Regression 2...............................................................................................................14
5 Conclusion...................................................................................................................................16
6 Reflection....................................................................................................................................16
Reference.......................................................................................................................................17
Page | ii
1 Introduction..................................................................................................................................1
1.1 Authorisation and Purpose...............................................................................................1
Limitations...................................................................................................................................1
Scope............................................................................................................................................1
Methodology...............................................................................................................................1
2 Data Setup....................................................................................................................................1
3 Exploratory Data Analysis.............................................................................................................2
3.1 One Variable Analysis................................................................................................................2
3.1.1 One Variable Analysis – 1.......................................................................................................2
3.1.2 One Variable Analysis – 2.......................................................................................................3
3.1.3 One Variable Analysis – 3.......................................................................................................6
3.2 Two-variable analysis.................................................................................................................7
3.2.1 Two-variable analysis 1...........................................................................................................7
3.2.2 Two-variable analysis 2...........................................................................................................8
4 Advanced analysis.......................................................................................................................10
4.1 Clustering.................................................................................................................................10
4.1.1 Brief explanation of k-means and clustering........................................................................10
4.1.2 Clustering Analysis................................................................................................................11
4.2 Linear regression......................................................................................................................12
4.2.1 Brief definition of linear regression......................................................................................12
4.2.2 Linear Regression 1...............................................................................................................13
4.2.3 Linear Regression 2...............................................................................................................14
5 Conclusion...................................................................................................................................16
6 Reflection....................................................................................................................................16
Reference.......................................................................................................................................17
Page | ii

1 Introduction
1.1 Authorisation and Purpose
The purpose of the present study is to analyse the health of East Asia and Pacific region with
reference to the period of 2001 to 2015. The data has been collected for World Bank. The
analysis of the data has implications for governments and planners. Improvements in the health
of the region can be initiated through the present study.
Limitations
The information provided for the present investigation pertains to the region of East Asia and
Pacific. The data has been taken from World Bank. In addition, the time period chosen for the
study is from 2001 to 2015.
The analysis is limited to the region of East Asia and Pacific only.
Scope
The data for the present study is replete with information related to the health of the region.
There are 26 attributes in the study with countries of East Asia and Pacific region. In addition,
the study present information on the attributes for the period of 2001 to 2015. However, the
data derived from the world bank has lots of missing data.
The analysis of the data is done through statistical analysis and interpretation of graphs. In the
first stage the data has been studied through three one-variable analyses. In the second stage
two-variable analysis is used. Next we analyse the information through k-means clustering.
Finally, relation between two attributes is studied through linear regression.
Methodology
For the analysis of the health of the East Asia and Pacific region quantitative information for the
period of 2001 to 2015 is studied. The information for the study has been gathered from World
Bank.
2 Data Setup
Before the analysis of the data can take place the data file needs to be loaded into the “R”
program. When the first line of Code is run a pop-up window opens. The user is requested to
input the location of the data file. Moreover, when the file is loaded into the “R” program the
first row is taken as the header. In addition, it was found that there are many missing values in
the “CSV” file, these are denoted as missing is the first line of code.
The second stage of the data analysis provides information to “R program” to load library files.
Library files are necessary to carry out different statistical tests and also to produce charts and
graphs.
1.1 Authorisation and Purpose
The purpose of the present study is to analyse the health of East Asia and Pacific region with
reference to the period of 2001 to 2015. The data has been collected for World Bank. The
analysis of the data has implications for governments and planners. Improvements in the health
of the region can be initiated through the present study.
Limitations
The information provided for the present investigation pertains to the region of East Asia and
Pacific. The data has been taken from World Bank. In addition, the time period chosen for the
study is from 2001 to 2015.
The analysis is limited to the region of East Asia and Pacific only.
Scope
The data for the present study is replete with information related to the health of the region.
There are 26 attributes in the study with countries of East Asia and Pacific region. In addition,
the study present information on the attributes for the period of 2001 to 2015. However, the
data derived from the world bank has lots of missing data.
The analysis of the data is done through statistical analysis and interpretation of graphs. In the
first stage the data has been studied through three one-variable analyses. In the second stage
two-variable analysis is used. Next we analyse the information through k-means clustering.
Finally, relation between two attributes is studied through linear regression.
Methodology
For the analysis of the health of the East Asia and Pacific region quantitative information for the
period of 2001 to 2015 is studied. The information for the study has been gathered from World
Bank.
2 Data Setup
Before the analysis of the data can take place the data file needs to be loaded into the “R”
program. When the first line of Code is run a pop-up window opens. The user is requested to
input the location of the data file. Moreover, when the file is loaded into the “R” program the
first row is taken as the header. In addition, it was found that there are many missing values in
the “CSV” file, these are denoted as missing is the first line of code.
The second stage of the data analysis provides information to “R program” to load library files.
Library files are necessary to carry out different statistical tests and also to produce charts and
graphs.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

3 Exploratory Data Analysis
3.1 One Variable Analysis
3.1.1 One Variable Analysis – 1
The percentage of one-year children immunized at children birth in 2014 is investigated as a
one-variable study. From the study it is found that the average % of one year children
immunized in the region is 89.88 with standard deviation of 9.83%. The minimum and
maximum % of children immunized are 70 and 90% respectively. From the boxplot it can be
seen that the immunization of countries in the region is left skewed.
Page | 2
jpeg("Plot1.jpeg")
fill <- "green"
line <- "blue"
Plot1<- ggplot(Data1, aes(x = factor(0), y = SH.IMM.IBCG)) + geom_boxplot(fill = fill, colour
= line, alpha = 0.7)
Plot1<- Plot1+ scale_x_discrete(name = "Immunization, BCG (% of one-year-old children)")
+ scale_y_continuous(name = "Count")
Plot1<- Plot1+ ggtitle("Distribution of Immunization, BCG (% of one-year-old children) in
2014")+ theme_bw()
describe(Data1$SH.IMM.IBCG)
Plot1
print(Plot1)
dev.off()
Data <- read.csv(file.choose(), header = TRUE, sep = "," , na.strings = "..")
# Loading required library files
library(data.table)
library(reshape2)
library(psych)
library(factoextra)
library(ggplot2)
library(lattice)
library(dplyr)
3.1 One Variable Analysis
3.1.1 One Variable Analysis – 1
The percentage of one-year children immunized at children birth in 2014 is investigated as a
one-variable study. From the study it is found that the average % of one year children
immunized in the region is 89.88 with standard deviation of 9.83%. The minimum and
maximum % of children immunized are 70 and 90% respectively. From the boxplot it can be
seen that the immunization of countries in the region is left skewed.
Page | 2
jpeg("Plot1.jpeg")
fill <- "green"
line <- "blue"
Plot1<- ggplot(Data1, aes(x = factor(0), y = SH.IMM.IBCG)) + geom_boxplot(fill = fill, colour
= line, alpha = 0.7)
Plot1<- Plot1+ scale_x_discrete(name = "Immunization, BCG (% of one-year-old children)")
+ scale_y_continuous(name = "Count")
Plot1<- Plot1+ ggtitle("Distribution of Immunization, BCG (% of one-year-old children) in
2014")+ theme_bw()
describe(Data1$SH.IMM.IBCG)
Plot1
print(Plot1)
dev.off()
Data <- read.csv(file.choose(), header = TRUE, sep = "," , na.strings = "..")
# Loading required library files
library(data.table)
library(reshape2)
library(psych)
library(factoextra)
library(ggplot2)
library(lattice)
library(dplyr)
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
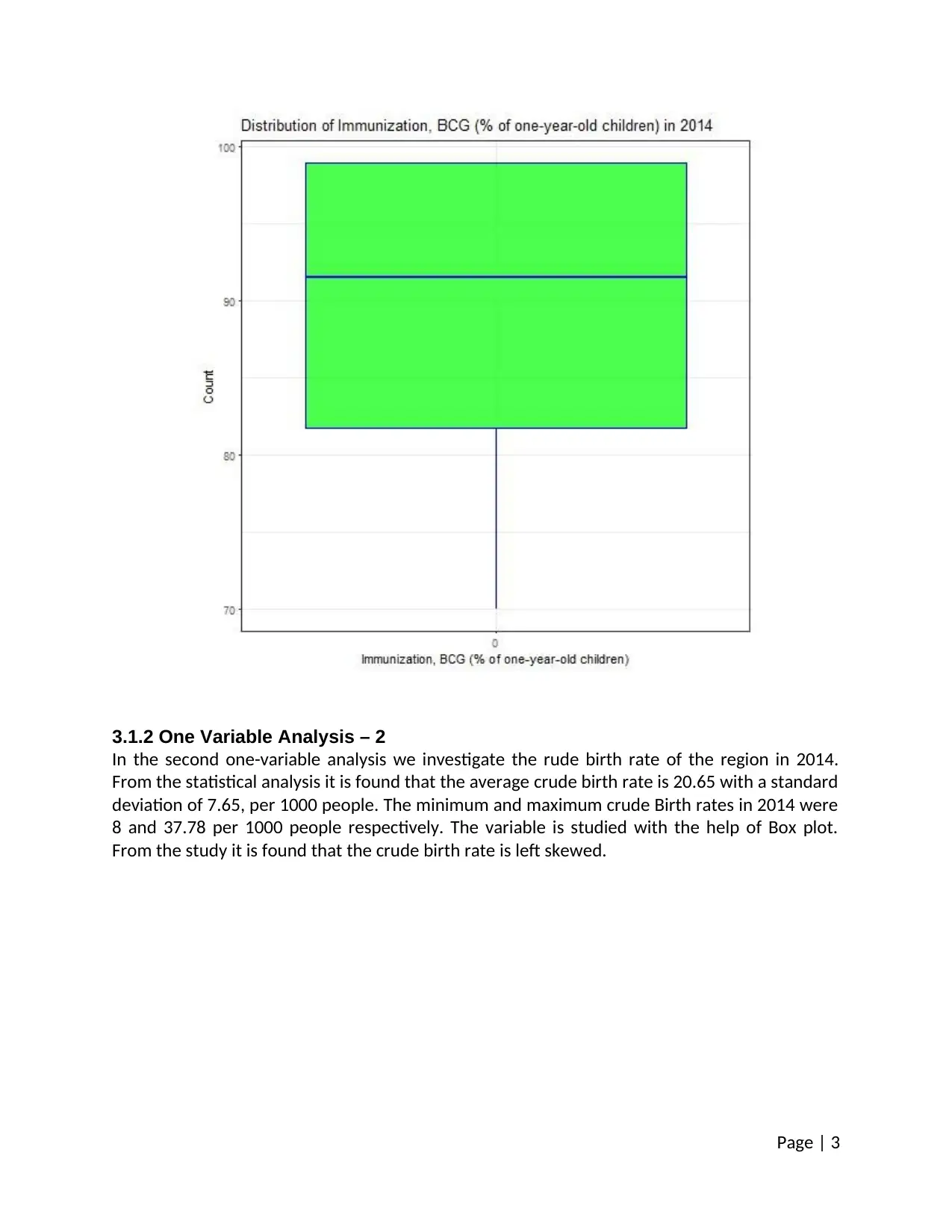
3.1.2 One Variable Analysis – 2
In the second one-variable analysis we investigate the rude birth rate of the region in 2014.
From the statistical analysis it is found that the average crude birth rate is 20.65 with a standard
deviation of 7.65, per 1000 people. The minimum and maximum crude Birth rates in 2014 were
8 and 37.78 per 1000 people respectively. The variable is studied with the help of Box plot.
From the study it is found that the crude birth rate is left skewed.
Page | 3
In the second one-variable analysis we investigate the rude birth rate of the region in 2014.
From the statistical analysis it is found that the average crude birth rate is 20.65 with a standard
deviation of 7.65, per 1000 people. The minimum and maximum crude Birth rates in 2014 were
8 and 37.78 per 1000 people respectively. The variable is studied with the help of Box plot.
From the study it is found that the crude birth rate is left skewed.
Page | 3

Page | 4
jpeg("Plot2.jpeg")
fill <- "green"
line <- "blue"
Plot2 <- ggplot(Data1, aes(x = factor(0), y = SP.DYN.CBRT.IN)) + geom_boxplot(fill = fill,
colour = line, alpha = 0.7)
Plot2 <- Plot2 + scale_x_discrete(name = "Crude Birth Rate (per 1000 people)") +
scale_y_continuous(name = "Count")
Plot2 <- Plot2 + ggtitle("Distribution of Crude Birth Rate in the Region in 2014")+
theme_bw()
describe(Data1$SP.DYN.CBRT.IN)
Plot2
print(Plot2)
dev.off()
jpeg("Plot2.jpeg")
fill <- "green"
line <- "blue"
Plot2 <- ggplot(Data1, aes(x = factor(0), y = SP.DYN.CBRT.IN)) + geom_boxplot(fill = fill,
colour = line, alpha = 0.7)
Plot2 <- Plot2 + scale_x_discrete(name = "Crude Birth Rate (per 1000 people)") +
scale_y_continuous(name = "Count")
Plot2 <- Plot2 + ggtitle("Distribution of Crude Birth Rate in the Region in 2014")+
theme_bw()
describe(Data1$SP.DYN.CBRT.IN)
Plot2
print(Plot2)
dev.off()
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Page | 5
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

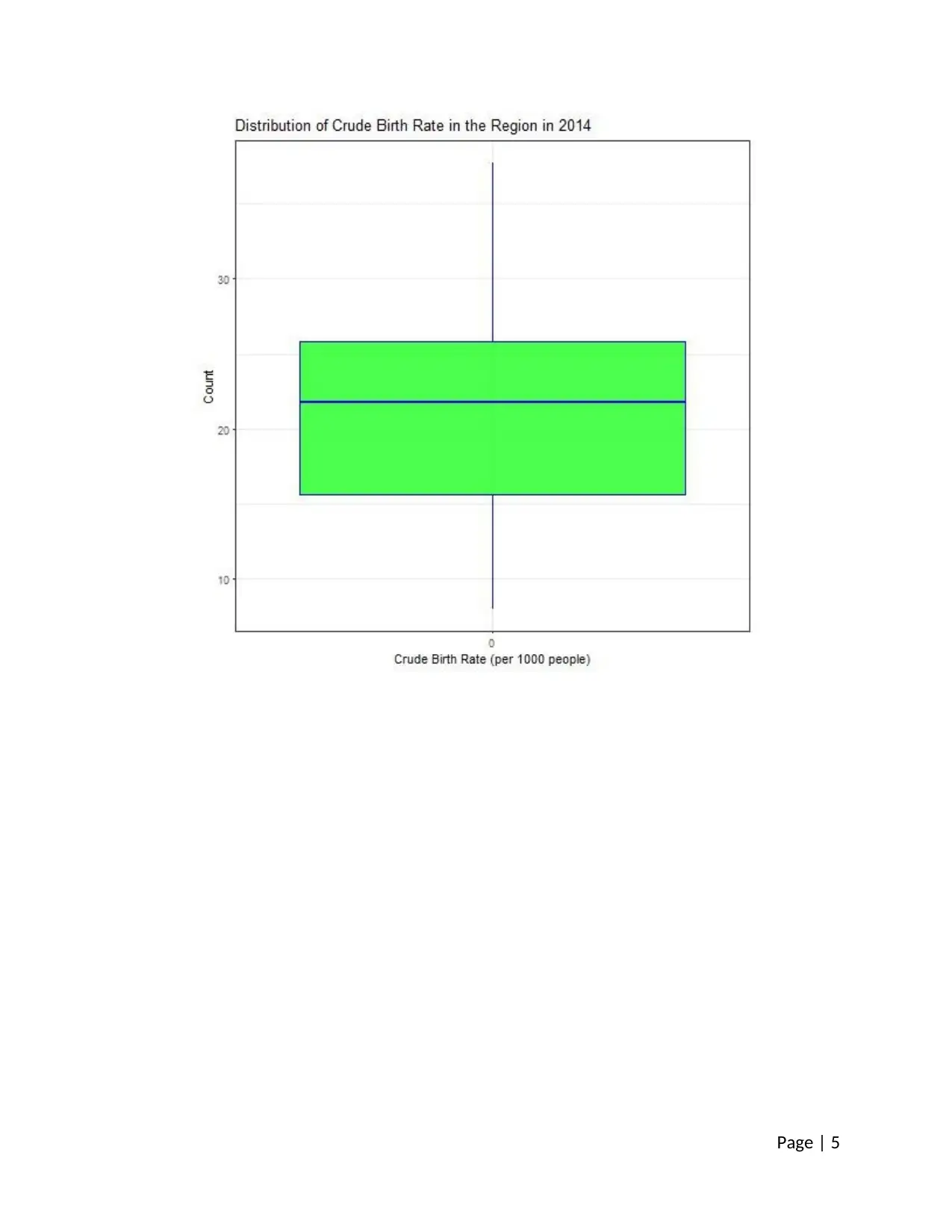
3.1.3 One Variable Analysis – 3
Histogram is a useful depiction of a one-variable. The rate of immunization is studies using
histogram. From the plotted histogram it can be seen that most of the countries of the region
have a very high level of immunization against BCG.
Page | 6
jpeg("Plot3.jpeg")
Plot3 <- ggplot(Data1, aes(x = SH.IMM.IBCG))+ geom_histogram(binwidth = 2,col="blue",
fill="green")
Plot3 <- Plot3 + scale_x_continuous("Immunization, BCG (% of one-year-old children)") +
scale_y_continuous("Count")+theme_bw()
Plot3 <- Plot3 + ggtitle("Distribution of Immunization, BCG (% of one-year-old children) in 2014")
Plot3
print(Plot3)
dev.off()
Histogram is a useful depiction of a one-variable. The rate of immunization is studies using
histogram. From the plotted histogram it can be seen that most of the countries of the region
have a very high level of immunization against BCG.
Page | 6
jpeg("Plot3.jpeg")
Plot3 <- ggplot(Data1, aes(x = SH.IMM.IBCG))+ geom_histogram(binwidth = 2,col="blue",
fill="green")
Plot3 <- Plot3 + scale_x_continuous("Immunization, BCG (% of one-year-old children)") +
scale_y_continuous("Count")+theme_bw()
Plot3 <- Plot3 + ggtitle("Distribution of Immunization, BCG (% of one-year-old children) in 2014")
Plot3
print(Plot3)
dev.off()
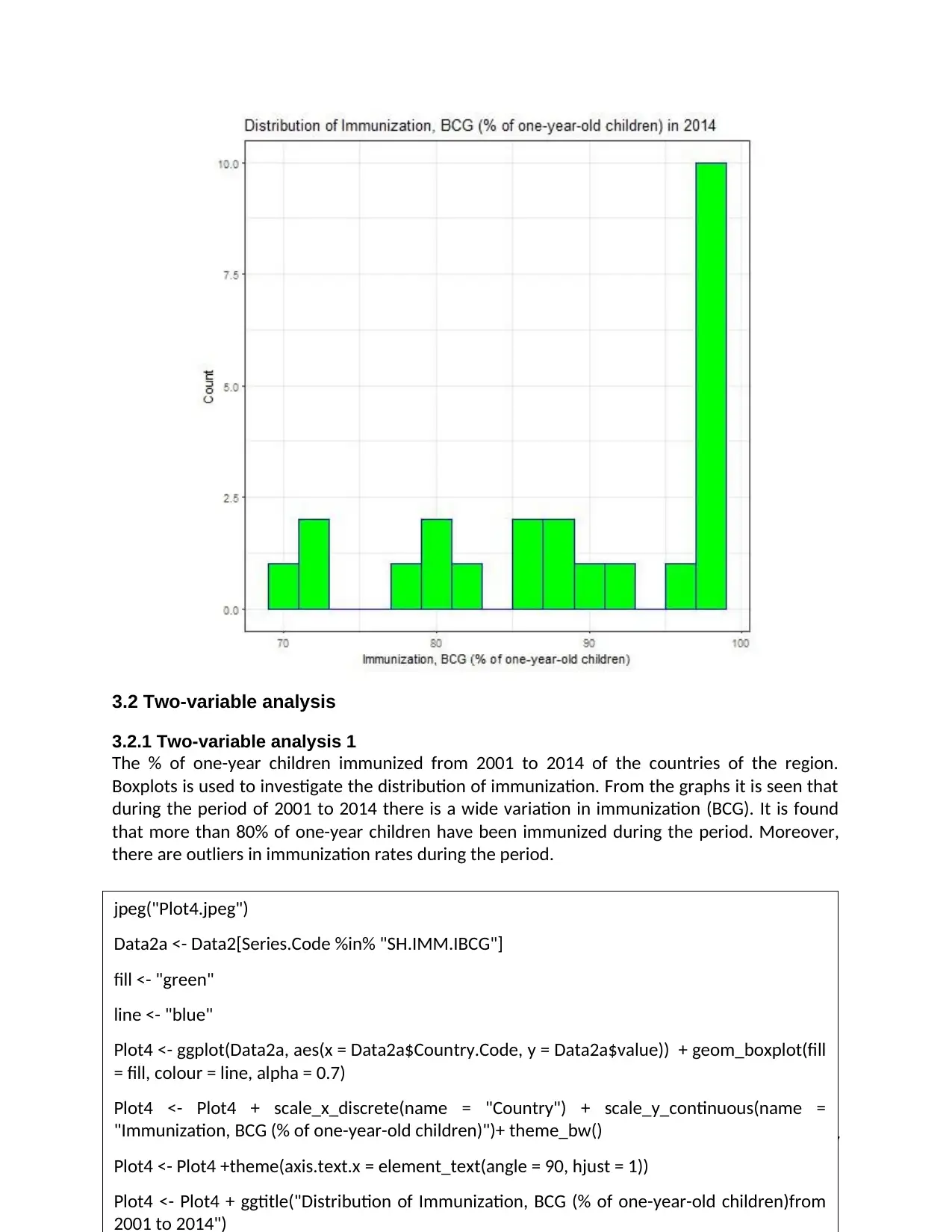
3.2 Two-variable analysis
3.2.1 Two-variable analysis 1
The % of one-year children immunized from 2001 to 2014 of the countries of the region.
Boxplots is used to investigate the distribution of immunization. From the graphs it is seen that
during the period of 2001 to 2014 there is a wide variation in immunization (BCG). It is found
that more than 80% of one-year children have been immunized during the period. Moreover,
there are outliers in immunization rates during the period.
Page | 7
jpeg("Plot4.jpeg")
Data2a <- Data2[Series.Code %in% "SH.IMM.IBCG"]
fill <- "green"
line <- "blue"
Plot4 <- ggplot(Data2a, aes(x = Data2a$Country.Code, y = Data2a$value)) + geom_boxplot(fill
= fill, colour = line, alpha = 0.7)
Plot4 <- Plot4 + scale_x_discrete(name = "Country") + scale_y_continuous(name =
"Immunization, BCG (% of one-year-old children)")+ theme_bw()
Plot4 <- Plot4 +theme(axis.text.x = element_text(angle = 90, hjust = 1))
Plot4 <- Plot4 + ggtitle("Distribution of Immunization, BCG (% of one-year-old children)from
2001 to 2014")
3.2.1 Two-variable analysis 1
The % of one-year children immunized from 2001 to 2014 of the countries of the region.
Boxplots is used to investigate the distribution of immunization. From the graphs it is seen that
during the period of 2001 to 2014 there is a wide variation in immunization (BCG). It is found
that more than 80% of one-year children have been immunized during the period. Moreover,
there are outliers in immunization rates during the period.
Page | 7
jpeg("Plot4.jpeg")
Data2a <- Data2[Series.Code %in% "SH.IMM.IBCG"]
fill <- "green"
line <- "blue"
Plot4 <- ggplot(Data2a, aes(x = Data2a$Country.Code, y = Data2a$value)) + geom_boxplot(fill
= fill, colour = line, alpha = 0.7)
Plot4 <- Plot4 + scale_x_discrete(name = "Country") + scale_y_continuous(name =
"Immunization, BCG (% of one-year-old children)")+ theme_bw()
Plot4 <- Plot4 +theme(axis.text.x = element_text(angle = 90, hjust = 1))
Plot4 <- Plot4 + ggtitle("Distribution of Immunization, BCG (% of one-year-old children)from
2001 to 2014")
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Page | 8
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
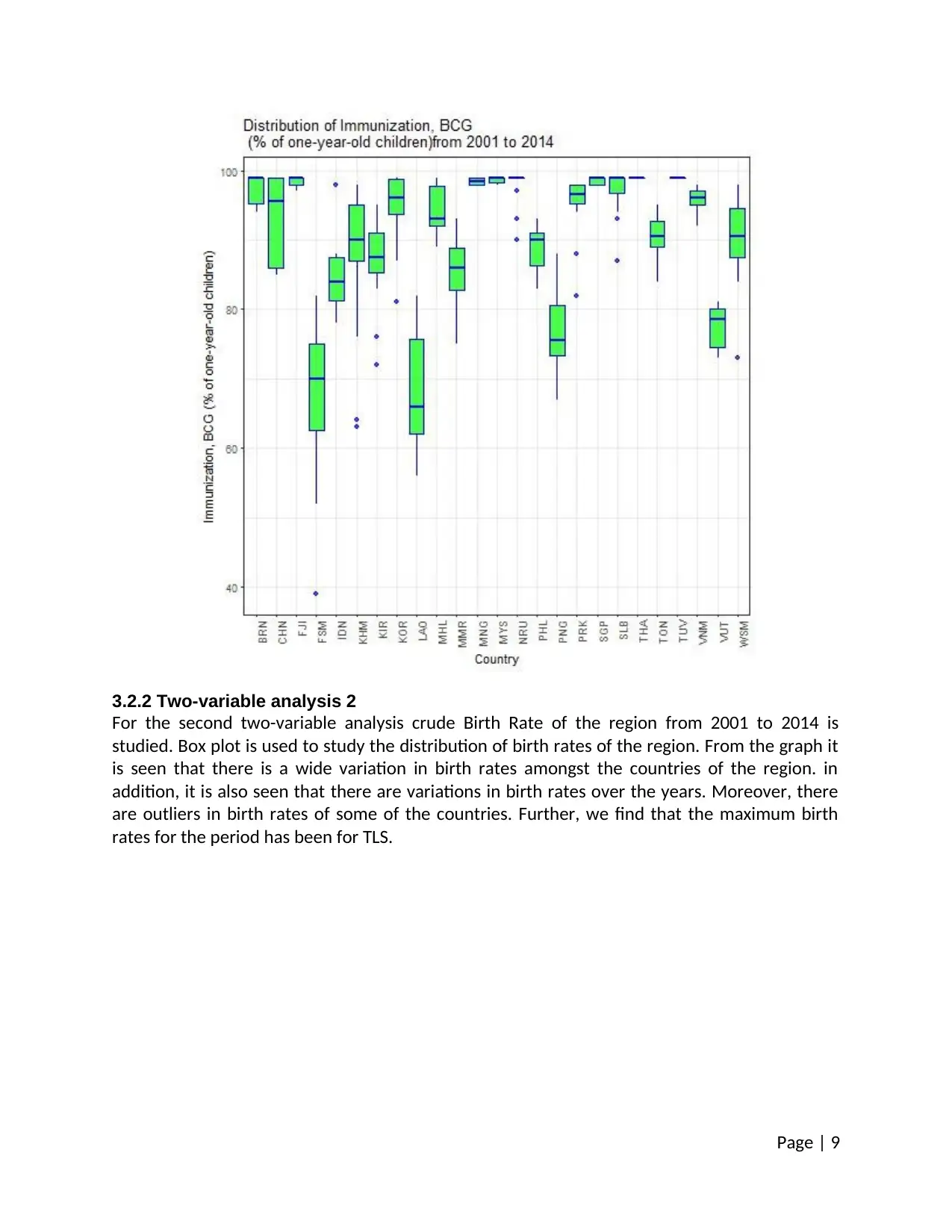
3.2.2 Two-variable analysis 2
For the second two-variable analysis crude Birth Rate of the region from 2001 to 2014 is
studied. Box plot is used to study the distribution of birth rates of the region. From the graph it
is seen that there is a wide variation in birth rates amongst the countries of the region. in
addition, it is also seen that there are variations in birth rates over the years. Moreover, there
are outliers in birth rates of some of the countries. Further, we find that the maximum birth
rates for the period has been for TLS.
Page | 9
For the second two-variable analysis crude Birth Rate of the region from 2001 to 2014 is
studied. Box plot is used to study the distribution of birth rates of the region. From the graph it
is seen that there is a wide variation in birth rates amongst the countries of the region. in
addition, it is also seen that there are variations in birth rates over the years. Moreover, there
are outliers in birth rates of some of the countries. Further, we find that the maximum birth
rates for the period has been for TLS.
Page | 9

Page | 10
jpeg("Plot5.jpeg")
Data2b <- Data2[Series.Code %in% "SP.DYN.CBRT.IN"]
fill <- "green"
line <- "blue"
Plot5 <- ggplot(Data2b, aes(x = Data2b$Country.Code, y = Data2b$value)) + geom_boxplot(fill =
fill, colour = line, alpha = 0.7)
Plot5 <- Plot5 + scale_x_discrete(name = "Country") + scale_y_continuous(name = "Crude Birth
Rate (per 1000 people)")+ theme_bw()
Plot5 <- Plot5 +theme(axis.text.x = element_text(angle = 90, hjust = 1)) + ggtitle("Distribution of
Crude Birth Rate from 2001 to 2014")
Plot5
print(Plot5)
dev.off()
jpeg("Plot5.jpeg")
Data2b <- Data2[Series.Code %in% "SP.DYN.CBRT.IN"]
fill <- "green"
line <- "blue"
Plot5 <- ggplot(Data2b, aes(x = Data2b$Country.Code, y = Data2b$value)) + geom_boxplot(fill =
fill, colour = line, alpha = 0.7)
Plot5 <- Plot5 + scale_x_discrete(name = "Country") + scale_y_continuous(name = "Crude Birth
Rate (per 1000 people)")+ theme_bw()
Plot5 <- Plot5 +theme(axis.text.x = element_text(angle = 90, hjust = 1)) + ggtitle("Distribution of
Crude Birth Rate from 2001 to 2014")
Plot5
print(Plot5)
dev.off()
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 20
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.