Statistics Summary Report: Analysis of Healthcare Access in SBS 2000
VerifiedAdded on 2022/11/29
|9
|1655
|219
Report
AI Summary
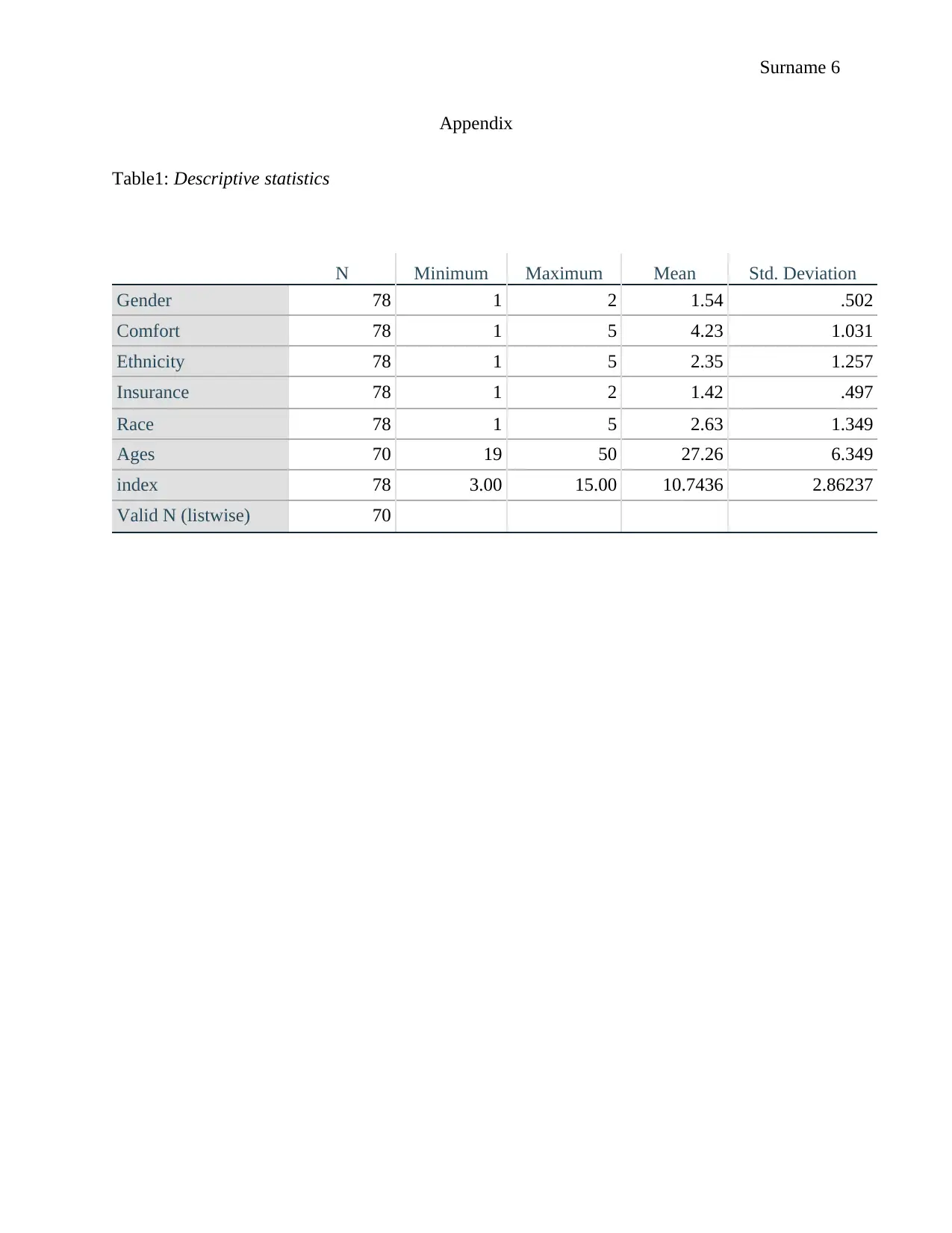
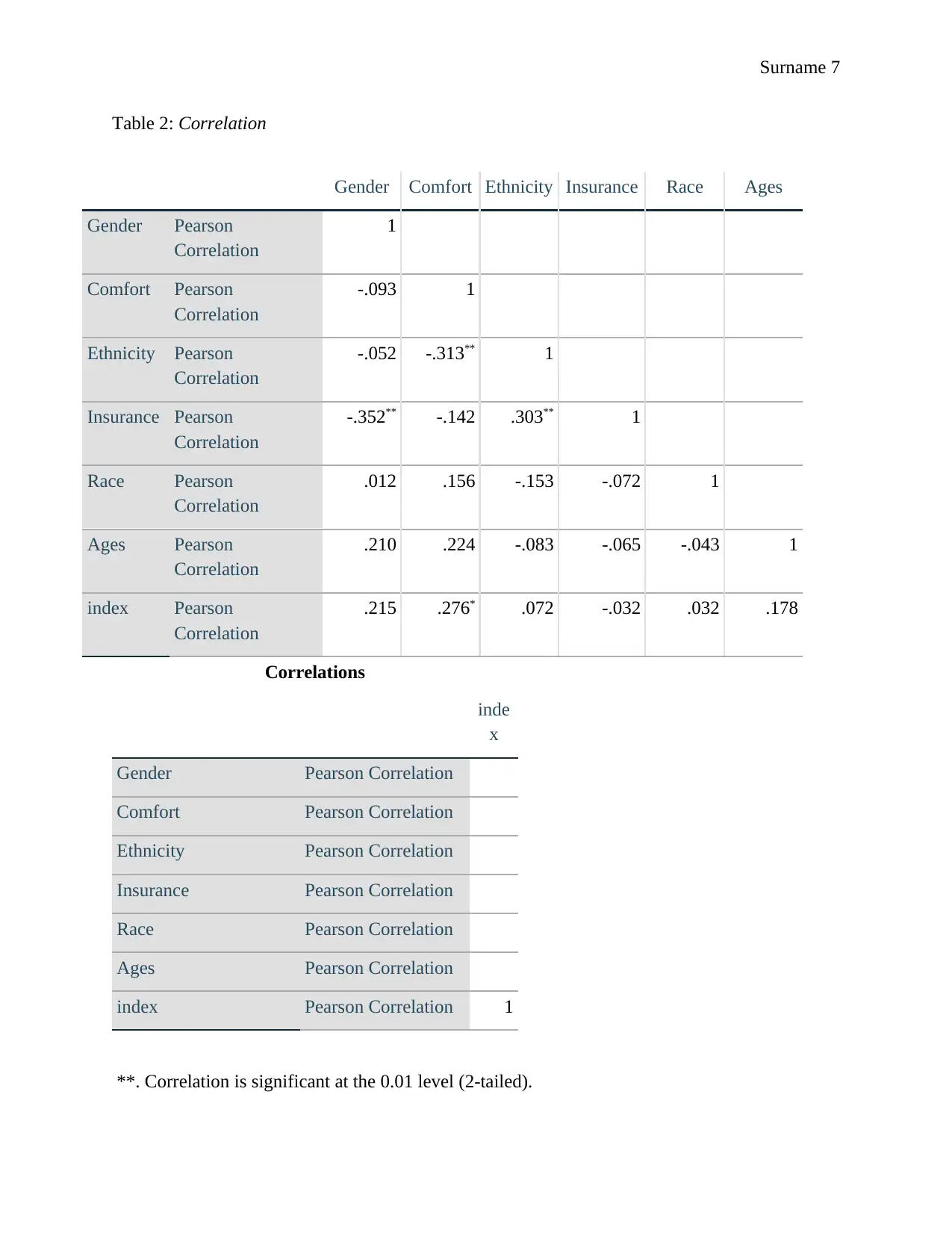
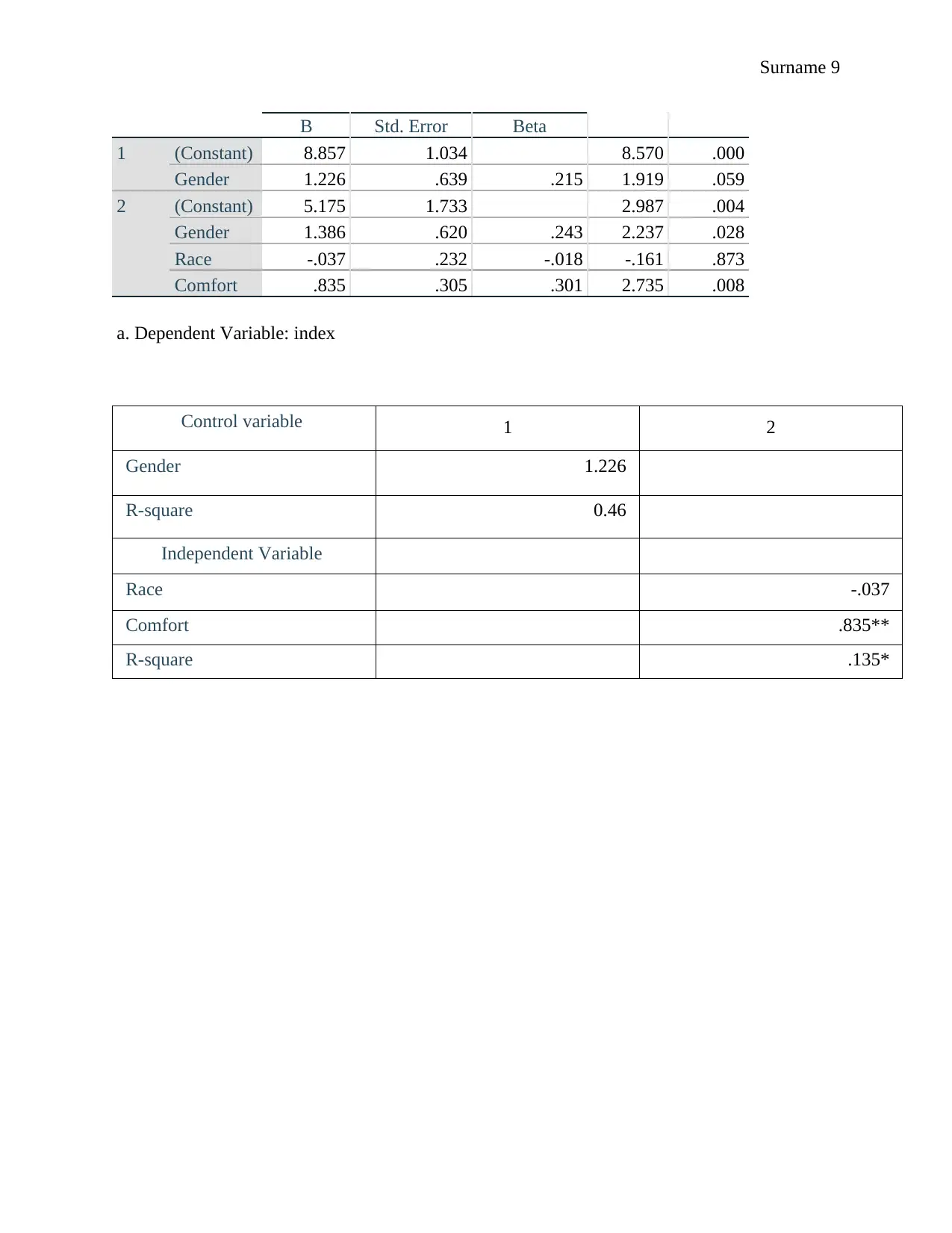
This report presents a statistical analysis of healthcare access, incorporating descriptive statistics, correlation analysis, and regression modeling. The study utilizes data on gender, comfort, ethnicity, insurance, race, age, and an index of access, employing Pearson's correlation coefficient to assess relationships between variables. Linear regression models were developed to explore the impact of gender, race, and comfort on the index. Findings reveal that approximately 46% of the variation in the index is attributable to these variables. The report tests hypotheses regarding the impact of gender, race, and comfort on the index, concluding that gender and comfort have significant effects, while race does not. The analysis includes detailed tables of descriptive statistics, correlation matrices, and regression coefficients. The student used the information in the assignment brief, which included the dependent and independent variables and the questions used to measure them. The student also provided the coding for the variables.






1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.