HI6007 Statistics & Research Methods: Data Analysis and Interpretation
VerifiedAdded on 2023/03/30
|11
|824
|481
Homework Assignment
AI Summary
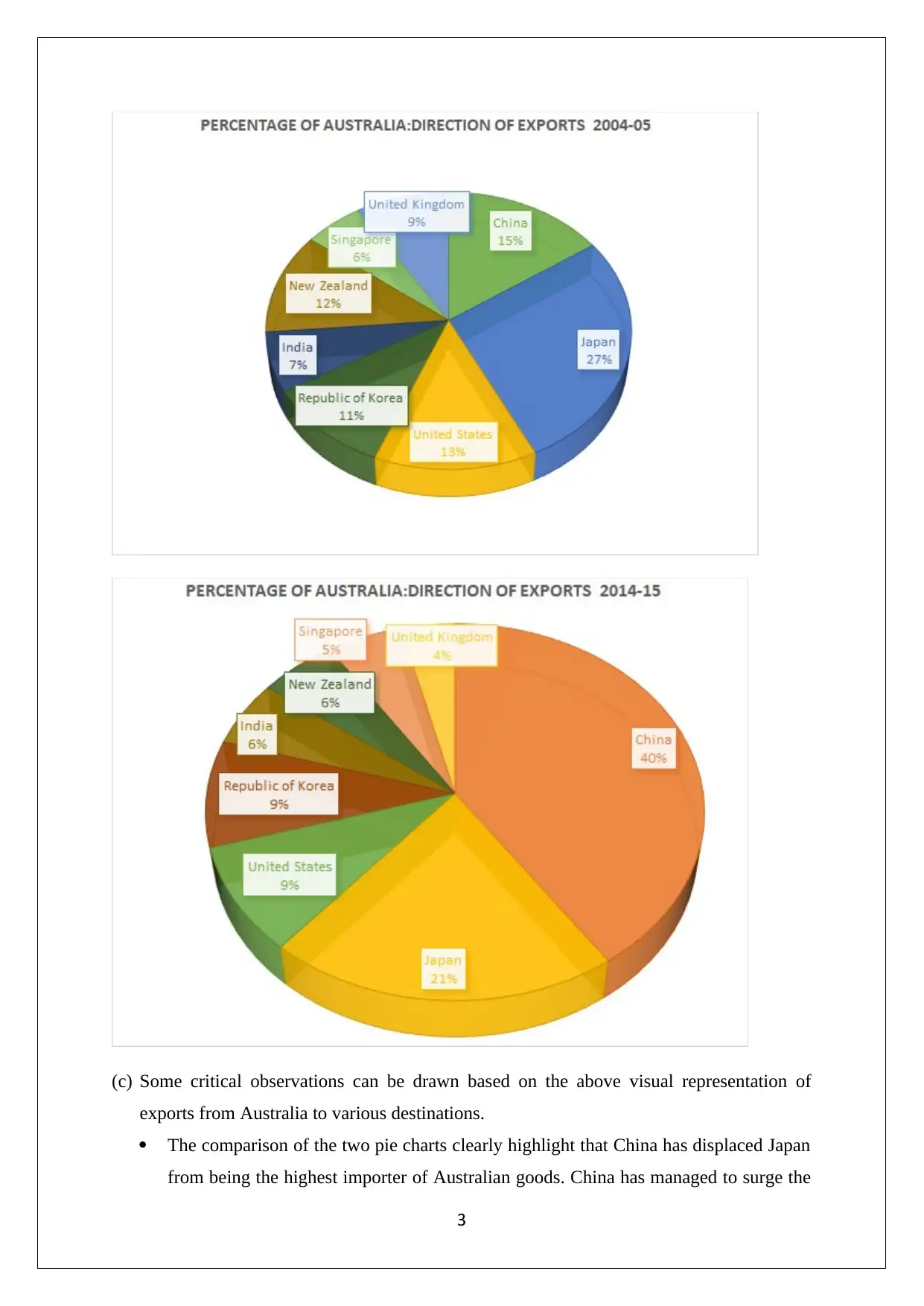
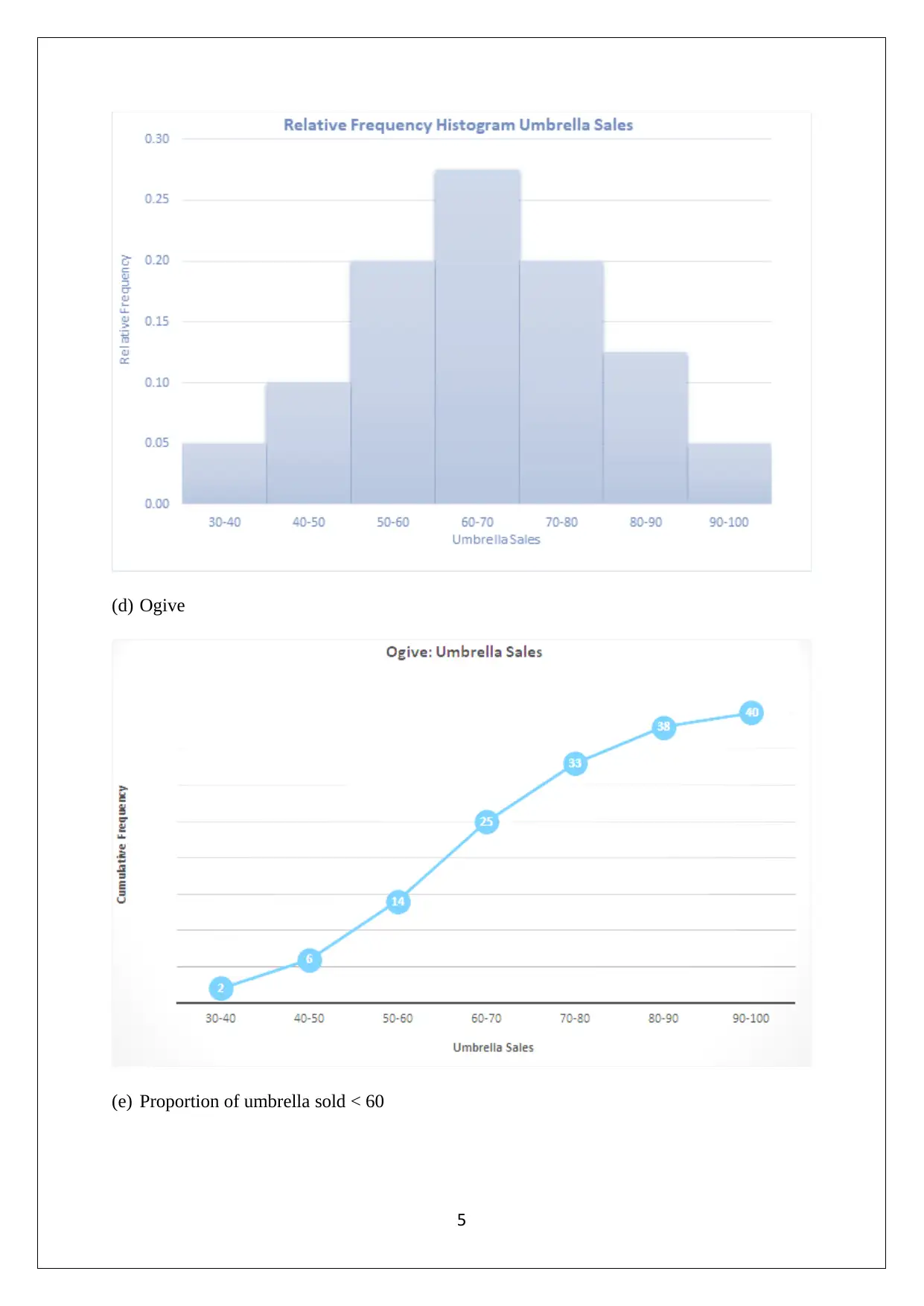
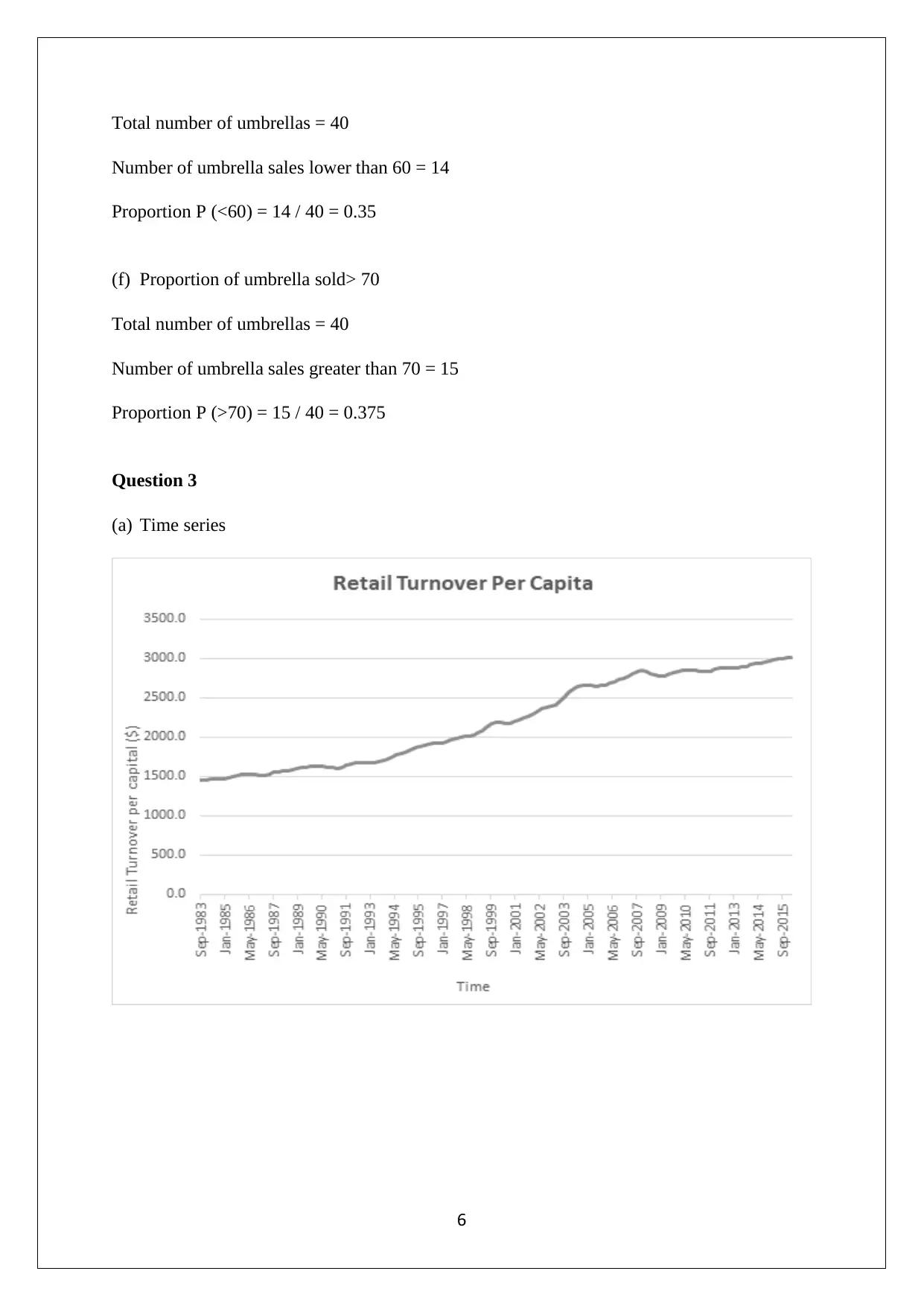
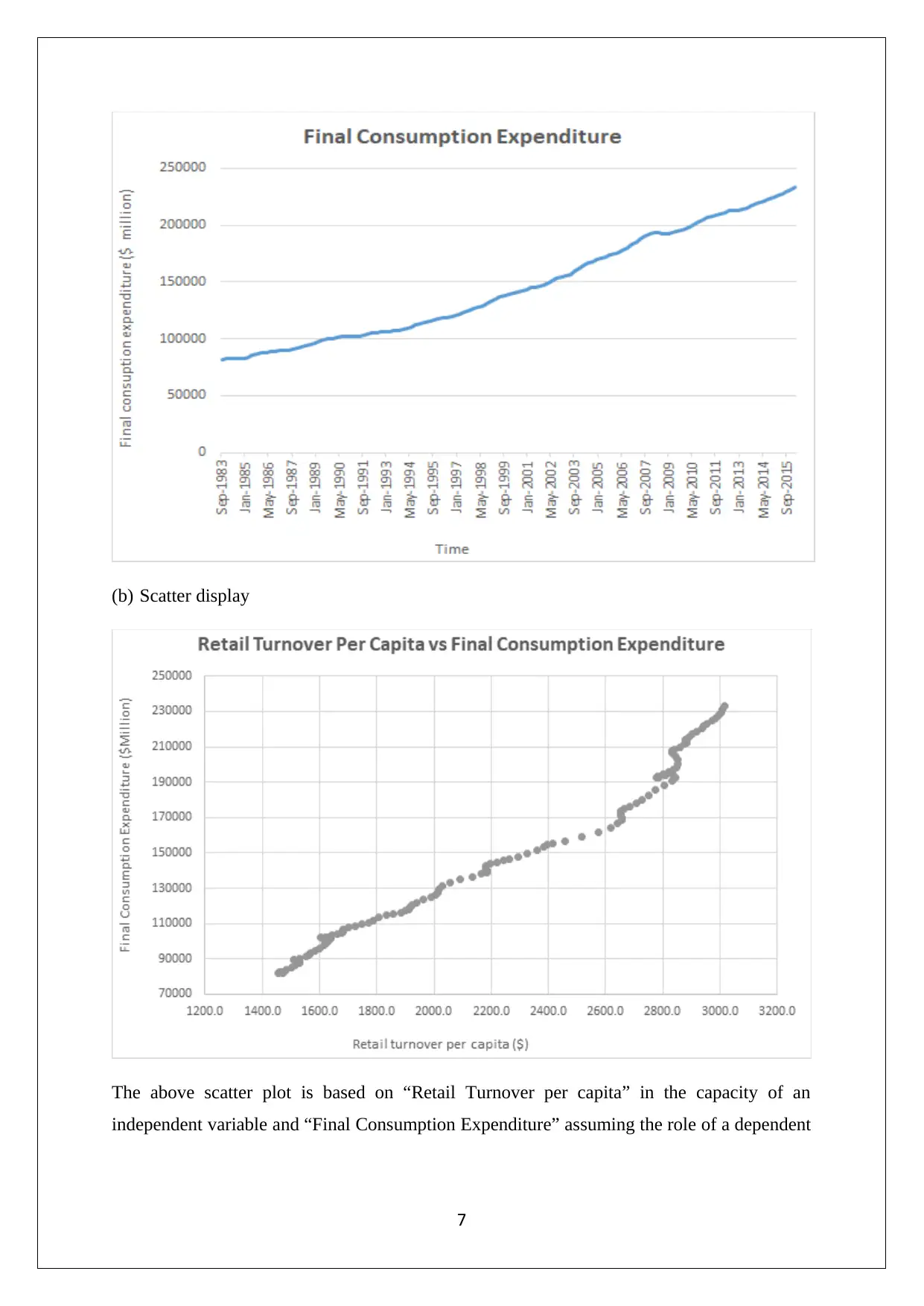
This assignment focuses on statistical analysis and interpretation of data, covering topics such as data visualization, frequency distribution, correlation, and regression analysis. It begins with an analysis of Australia's export data to various countries, using bar charts and pie charts to highlight trends and shifts in trade partnerships, particularly the rise of China as a major importer. The assignment then delves into frequency distributions and histograms related to umbrella sales, followed by a time series and scatter plot analysis of retail turnover per capita and final consumption expenditure. Descriptive statistics, correlation coefficients, regression models, and hypothesis testing are applied to the economic data, with interpretations of the results. The regression model's intercept, slope, coefficient of determination, and standard error are discussed in detail, providing a comprehensive understanding of the relationship between the variables. The assignment concludes with hypothesis testing to determine the significance of the slope coefficient.






1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.