HI6007 Statistics: Analysis of Startup Costs and Sales Regression
VerifiedAdded on 2020/04/07
|13
|2114
|229
Homework Assignment
AI Summary
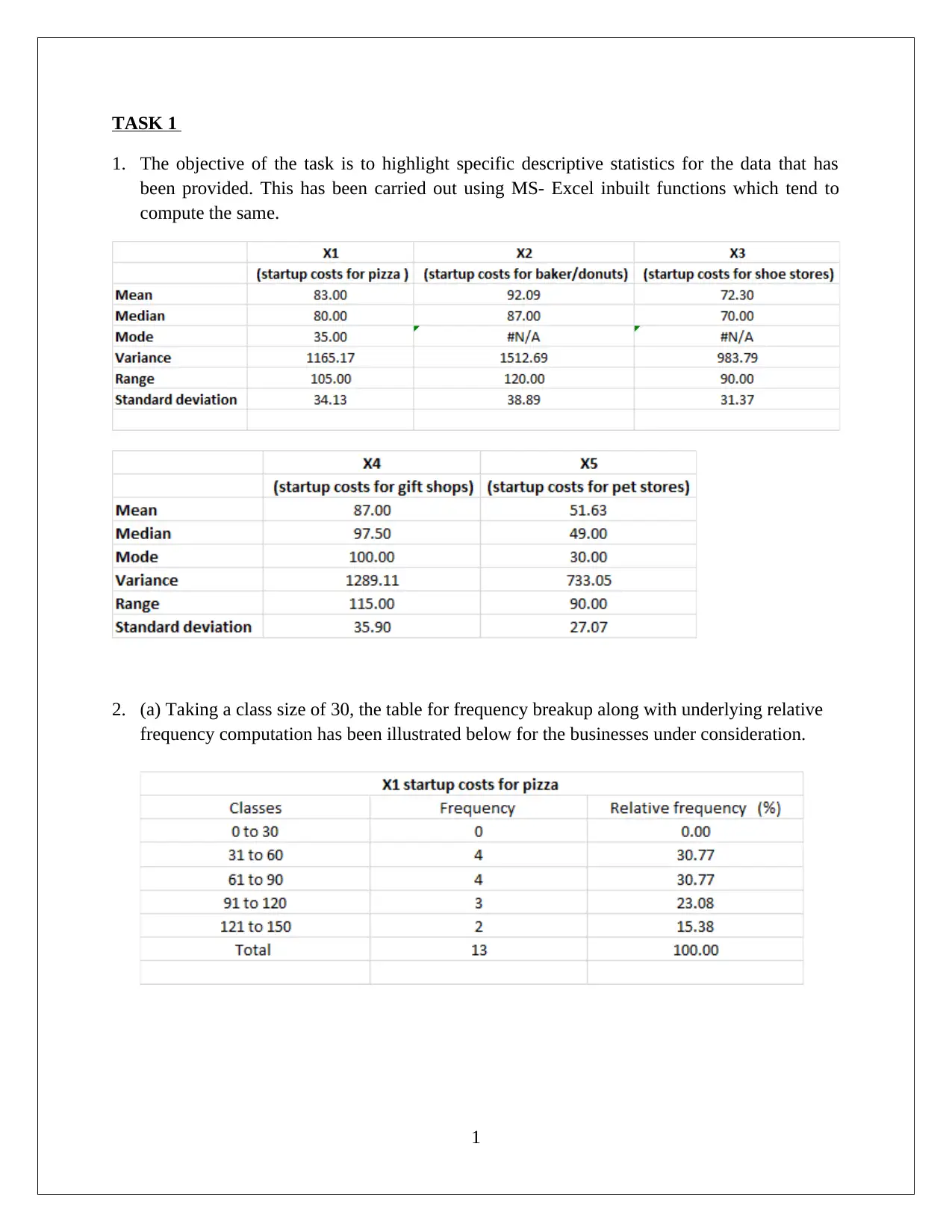
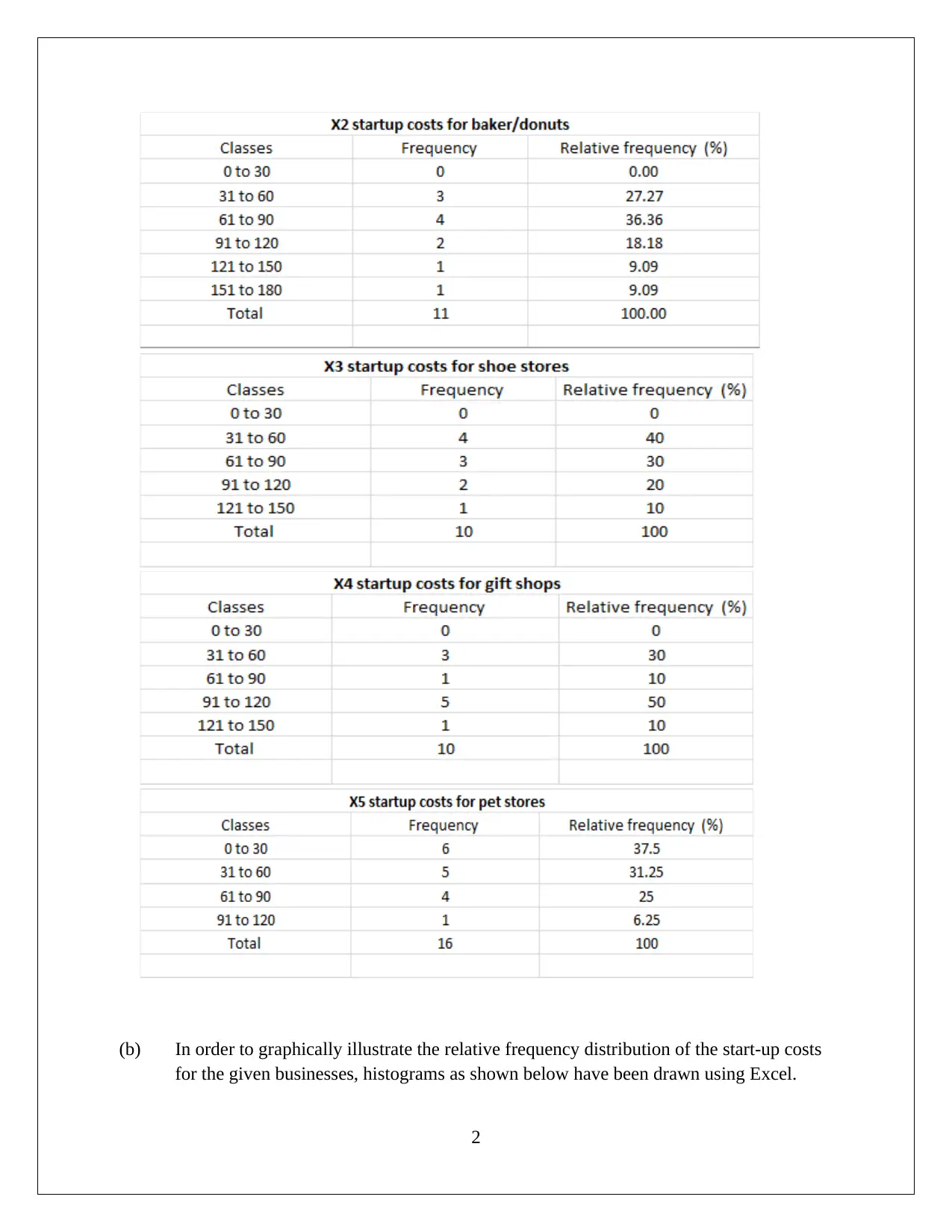
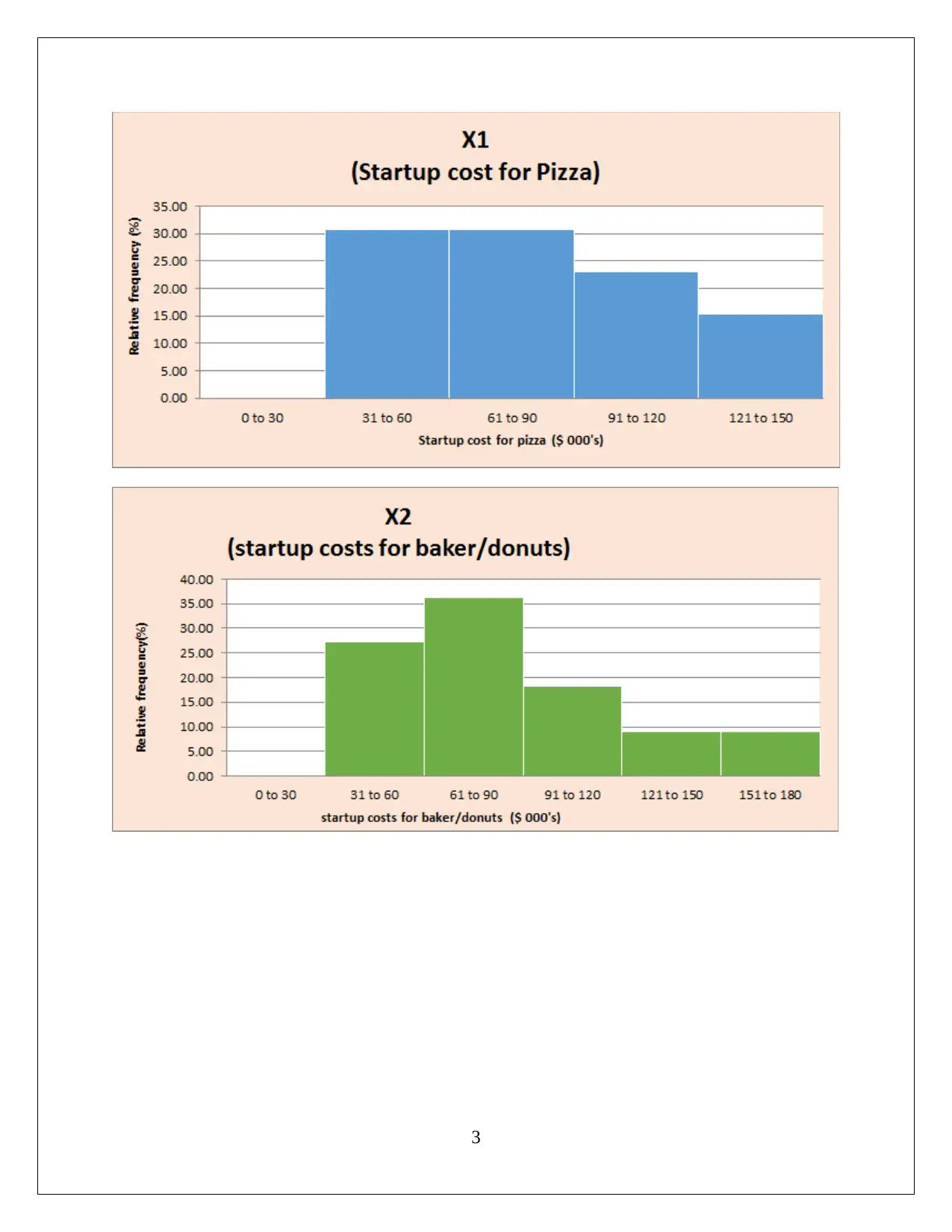
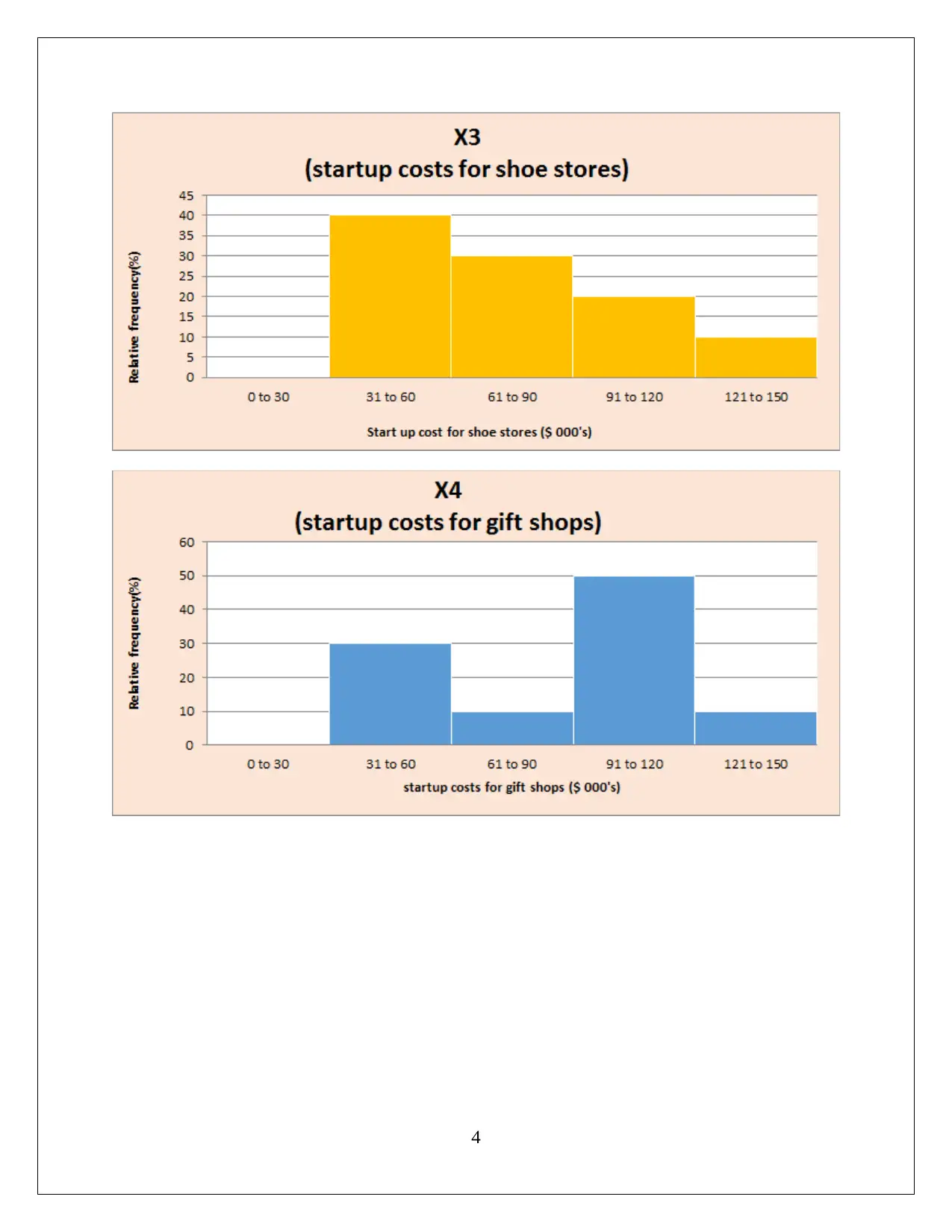
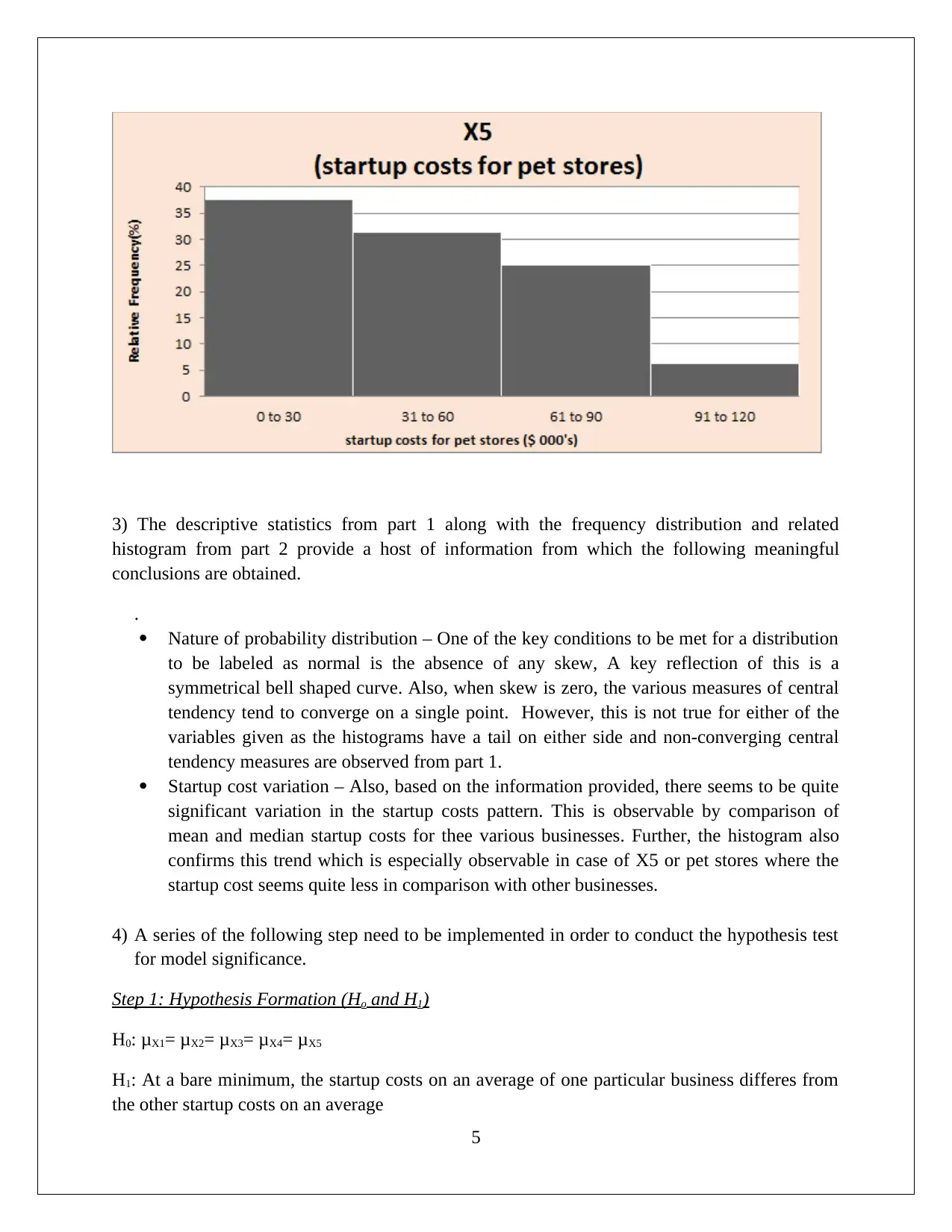
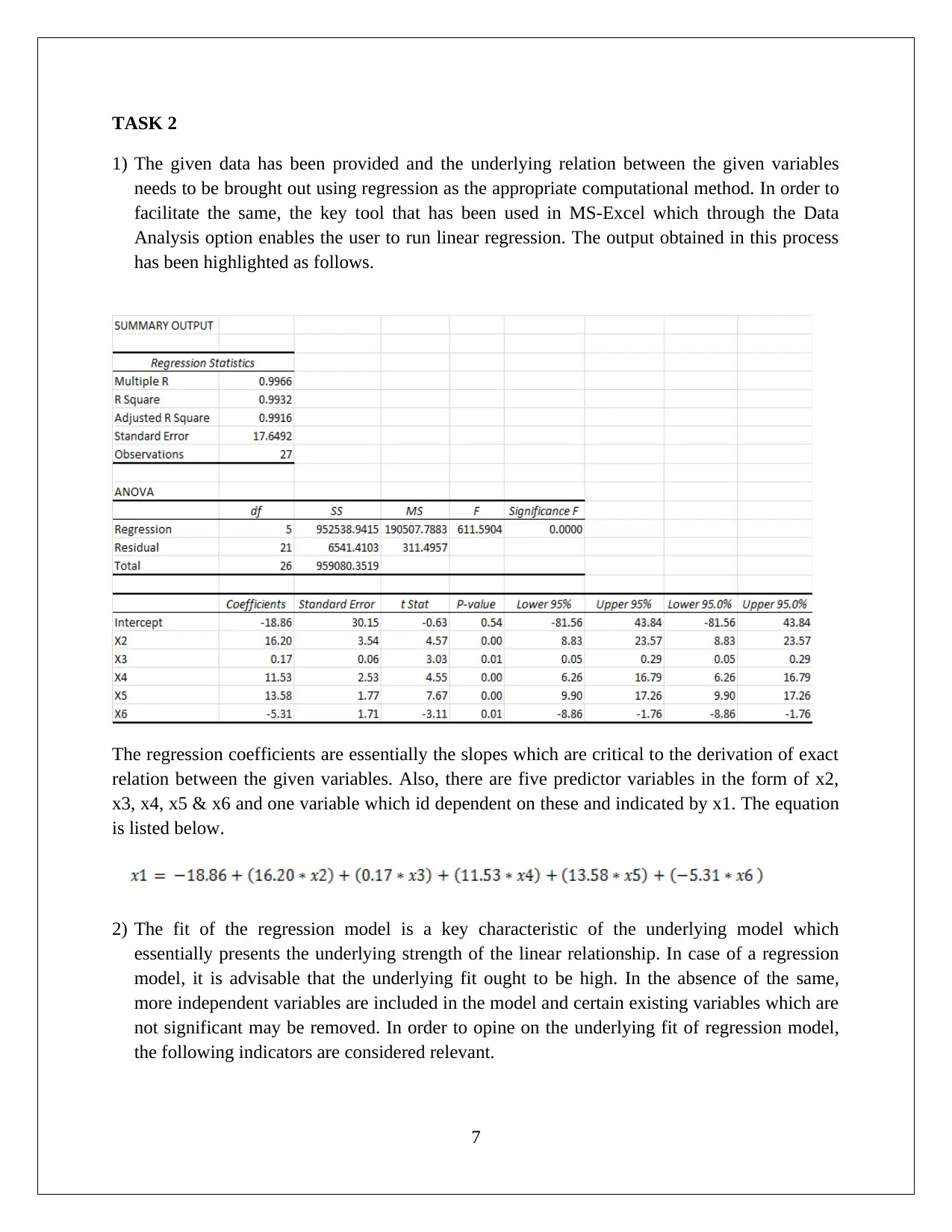
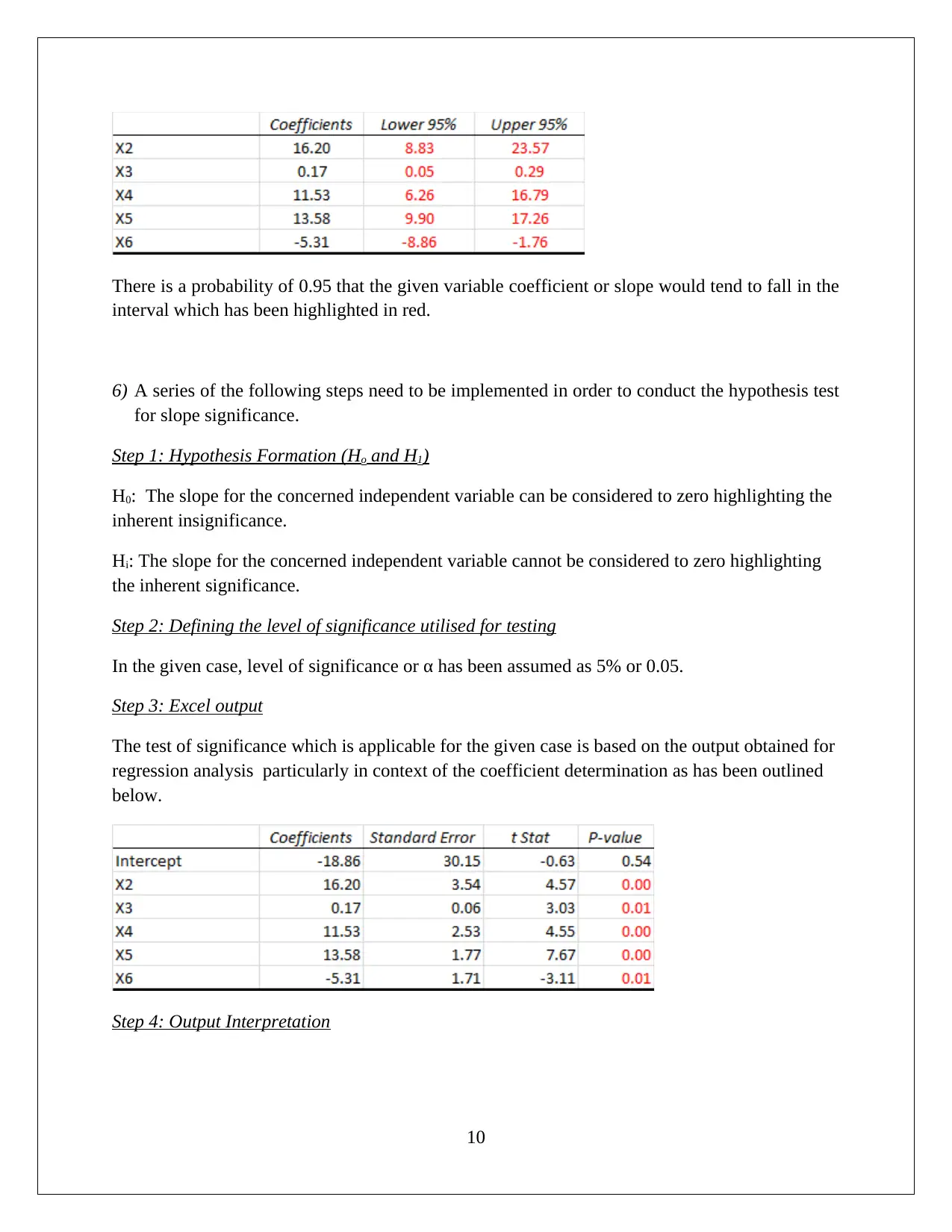
This assignment solution for HI6007 Statistics encompasses two key tasks. Task 1 focuses on descriptive statistics, including frequency distribution and histogram analysis of startup costs for various businesses. The solution highlights the nature of probability distribution, variation in startup costs, and conducts a hypothesis test using ANOVA to assess the significance of differences in startup costs. Task 2 delves into regression analysis, exploring the relationship between annual sales and predictor variables like franchise store area, inventory, advertising spending, customer coverage, and competing stores. The solution details the regression model's fit, interprets regression coefficients, and performs hypothesis tests for model and slope significance, ultimately concluding that the linear relationships are statistically significant. Finally, the solution provides a predictive model for annual sales based on given inputs.





1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.