Big Data with HIVE: Data Warehousing, Querying, and Partitioning
VerifiedAdded on 2023/06/01
|8
|1105
|326
Report
AI Summary
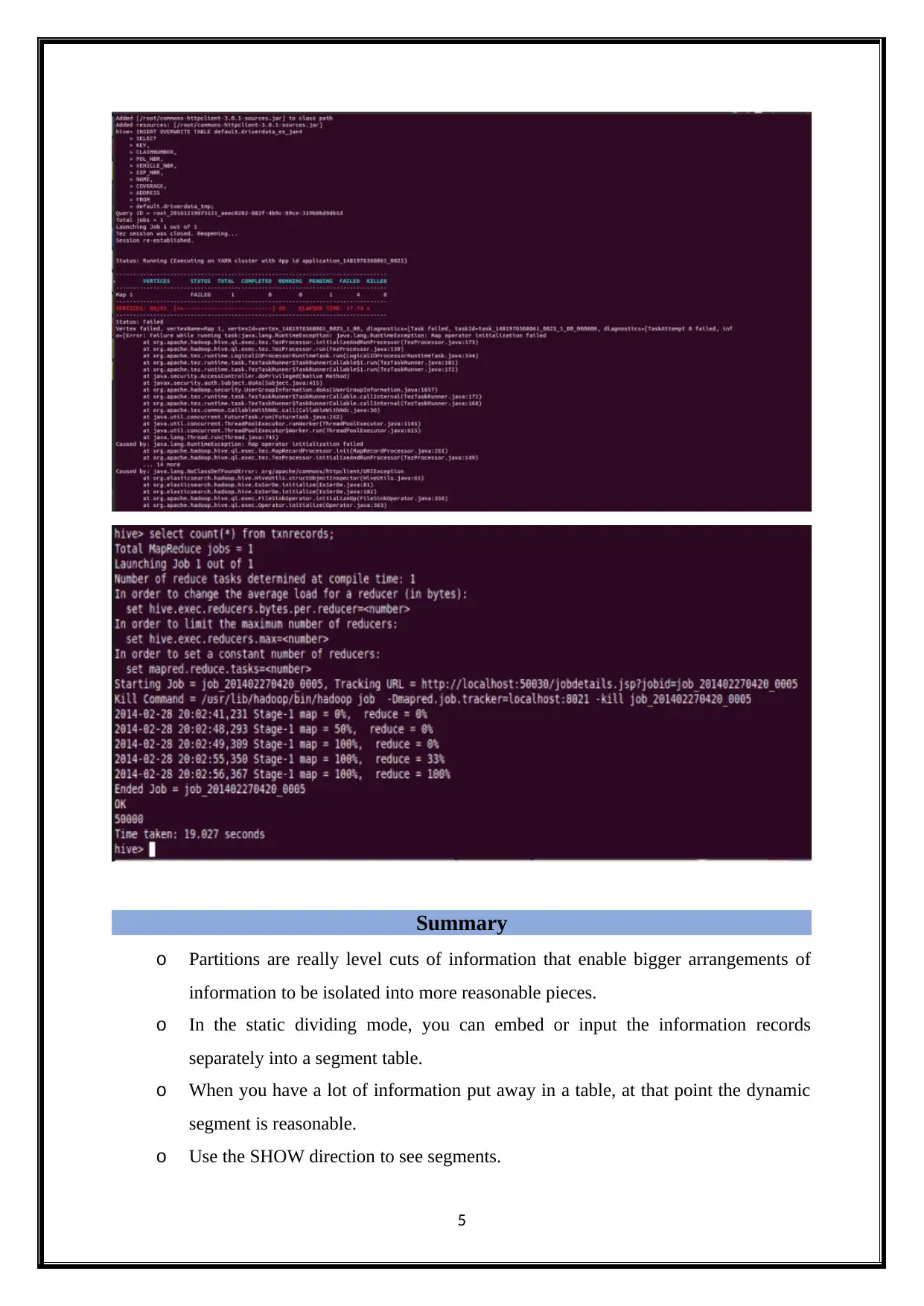
This report provides an overview of using Apache Hive in big data environments for data warehousing, querying, and managing large datasets. It highlights Hive's role in providing a SQL-like interface (HiveQL) to perform MapReduce tasks on extensive datasets within a Hadoop cluster. The report discusses Hive's advantages, such as unified resource management, simplified arrangement, and shared security, making it suitable for petabyte-scale data growth. It covers key aspects like data partitioning, which enhances query performance, and demonstrates how to connect datasets using SQL-like join semantics. The summary also includes a discussion of static and dynamic partitioning modes, along with commands for managing partitions, offering a comprehensive understanding of Hive's capabilities in big data processing and analysis.







1 out of 8
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.