BUSSSBF Course Assignment: Statistical Analysis of Household Data
VerifiedAdded on 2022/07/28
|8
|1020
|19
Homework Assignment
AI Summary
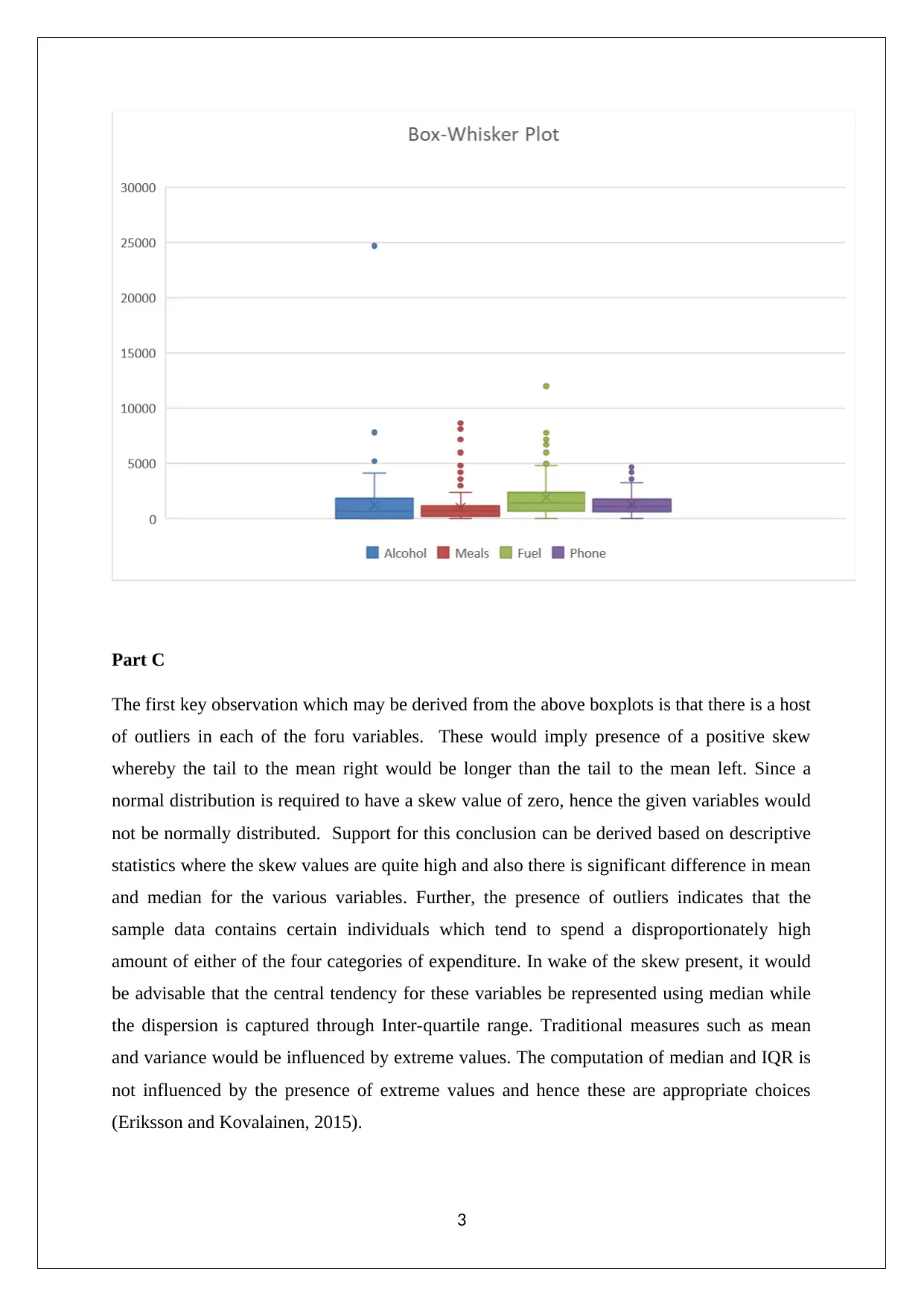
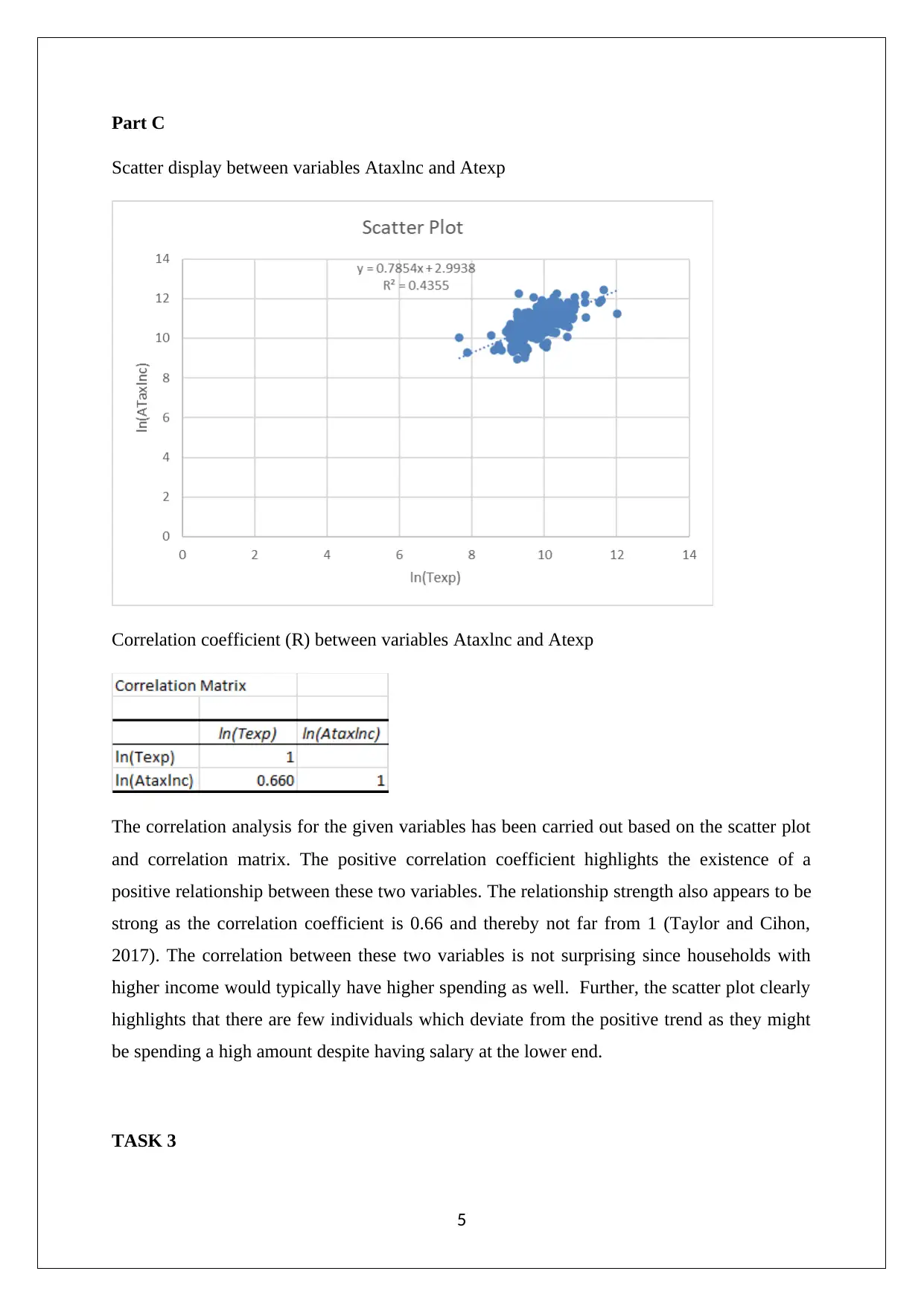
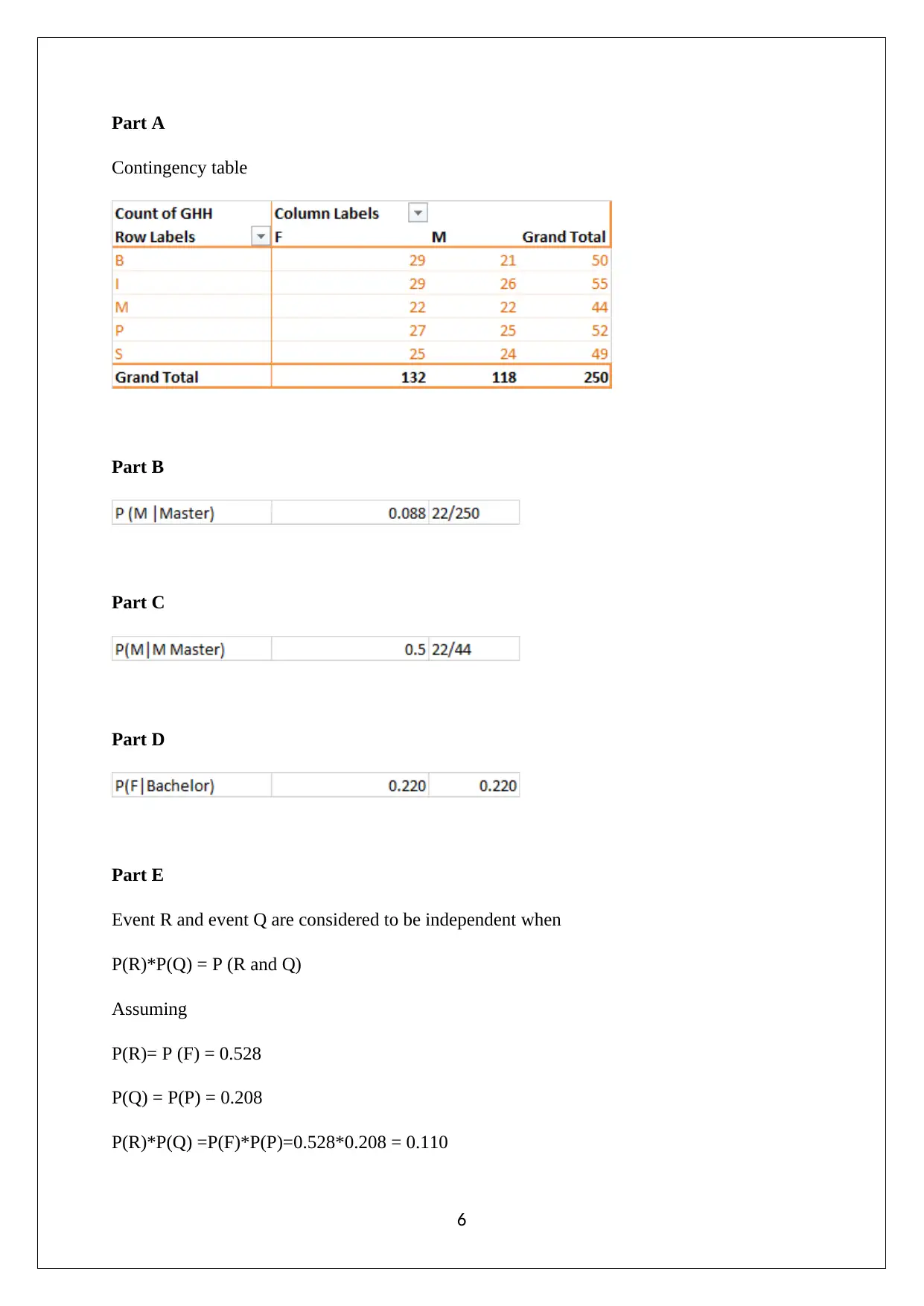
This assignment analyzes household data using statistical methods, addressing tasks related to sampling techniques, descriptive statistics, and probability. The student begins by employing simple random sampling to extract a sample of 250 observations and justifies the choice of this sampling method. Descriptive statistics are then calculated and visualized using box-whisker plots for variables such as alcohol, meals, fuel, and phone expenditure. The presence of outliers and the non-normality of the data distribution are discussed, along with the appropriate measures of central tendency and dispersion. Further, the assignment explores the 90th and 10th percentiles of after-tax income, the probability of household characteristics, and the correlation between variables using scatter plots and correlation coefficients. Finally, the assignment constructs a contingency table and calculates probabilities based on gender and education level, evaluating the independence of events.





1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.