Report on Numeracy and Data Analysis of Bristol Humidity Data
VerifiedAdded on 2023/06/05
|10
|1489
|113
Report
AI Summary
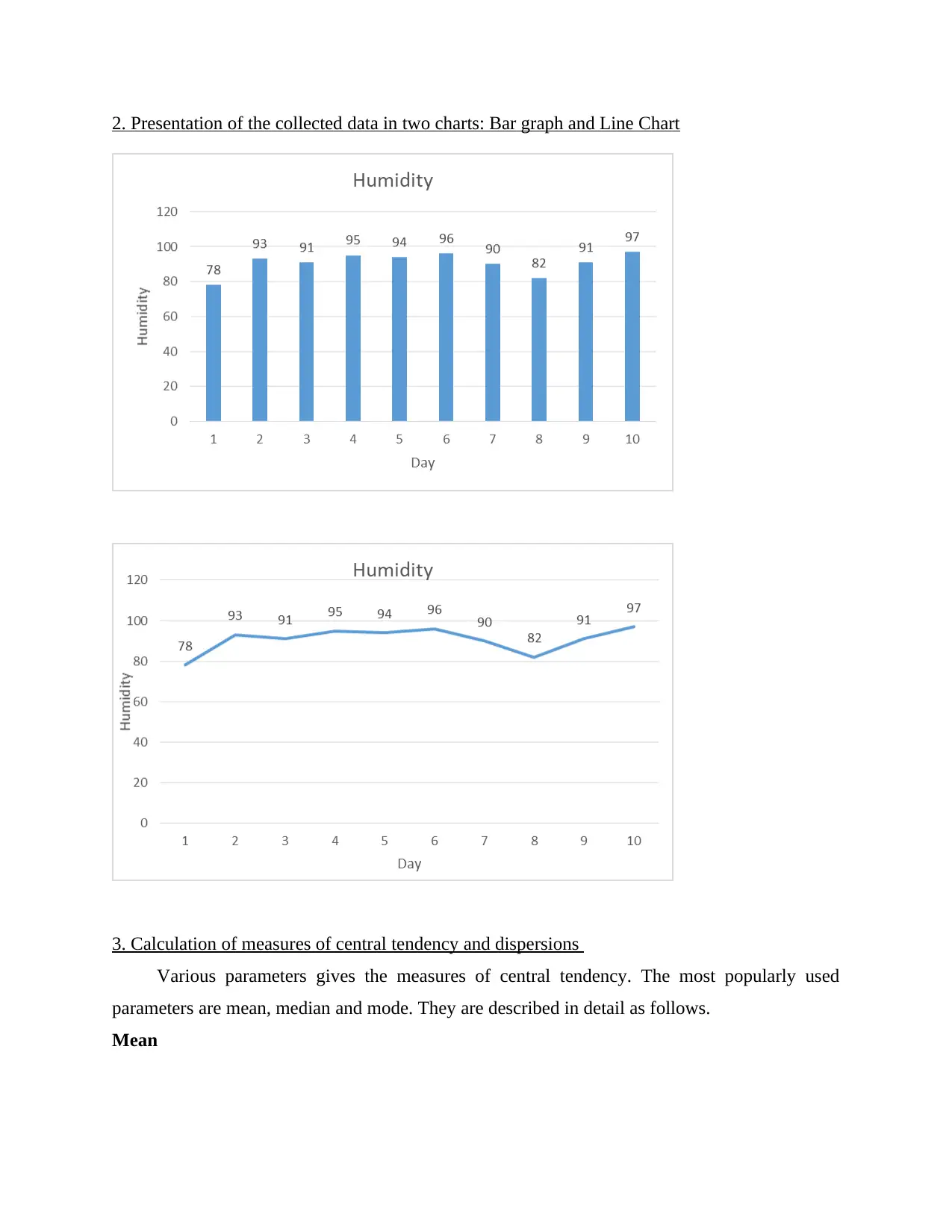
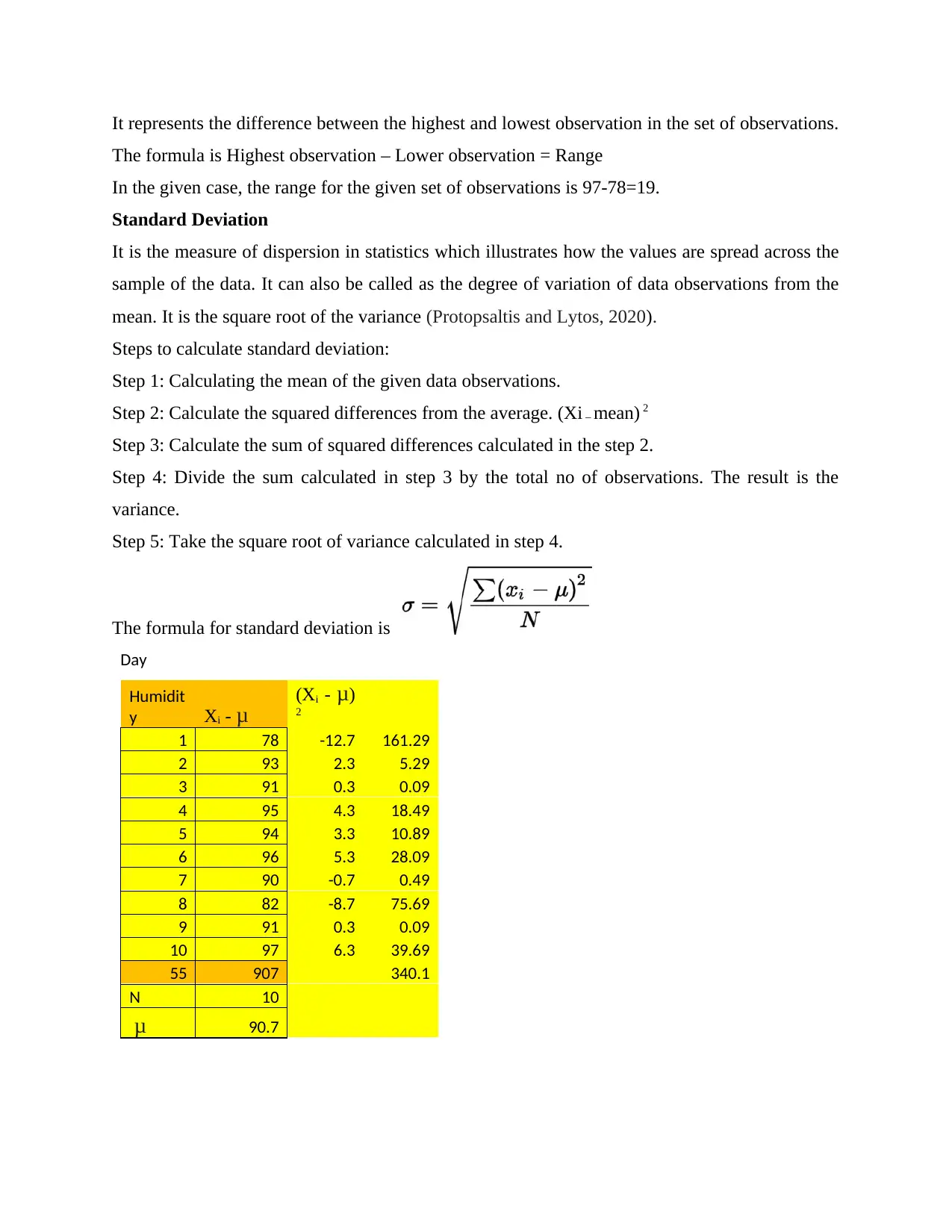
This report provides a comprehensive analysis of humidity data collected for Bristol, United Kingdom, over ten consecutive days. The data is presented in tabular and graphical formats, including bar graphs and line charts. The report calculates and explains various measures of central tendency, such as mean, median, and mode, and measures of dispersion, including range and standard deviation. Furthermore, it analyzes a linear forecasting model (y = mx + c) to predict future humidity values based on current trends. The report concludes by emphasizing the importance of data analysis in research, highlighting its role in simplifying complex data and deriving meaningful insights. Desklib offers more solved assignments and past papers for students.








1 out of 10
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.