Multiple Linear Regression Case Study: Insurance Rate Prediction Model
VerifiedAdded on 2023/06/11
|7
|769
|83
Case Study
AI Summary
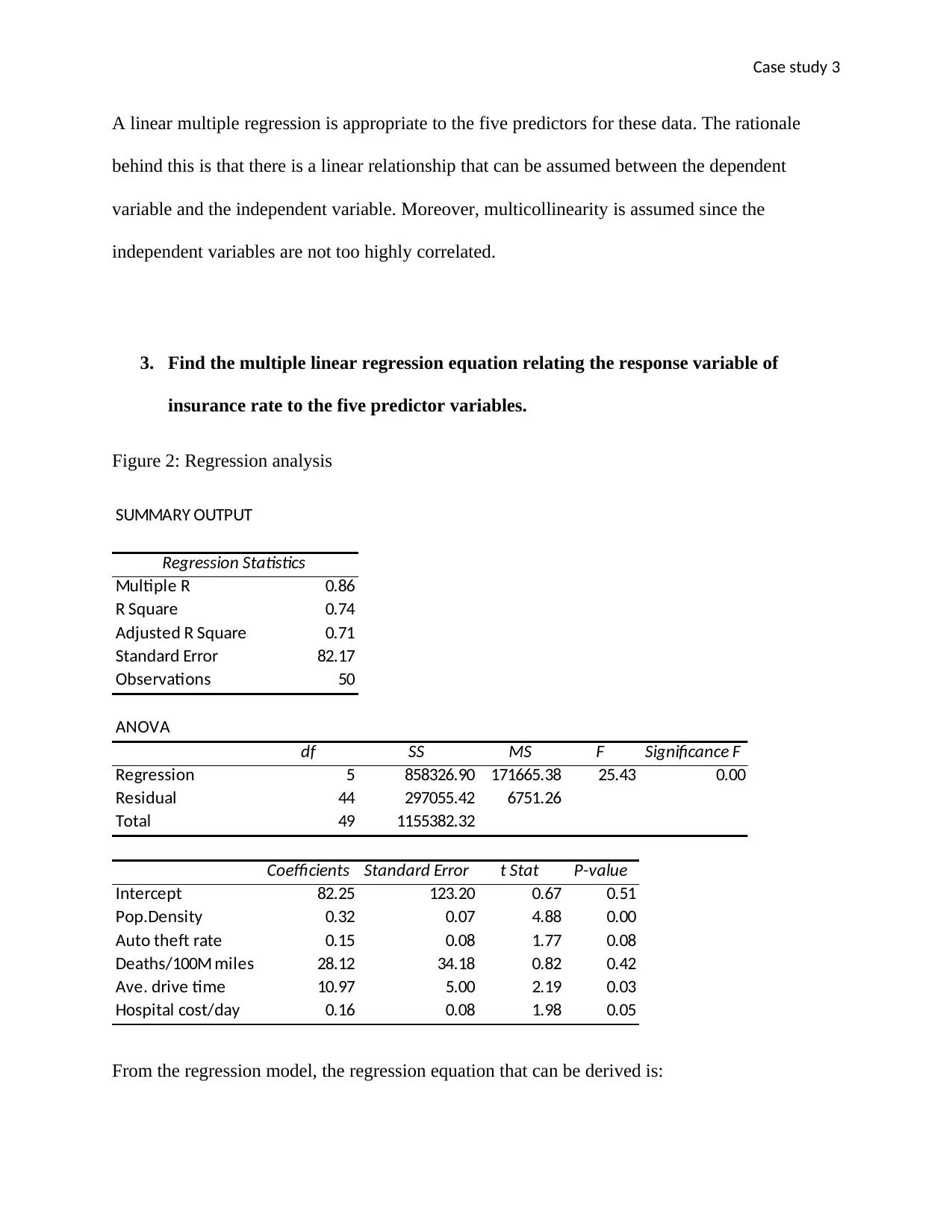
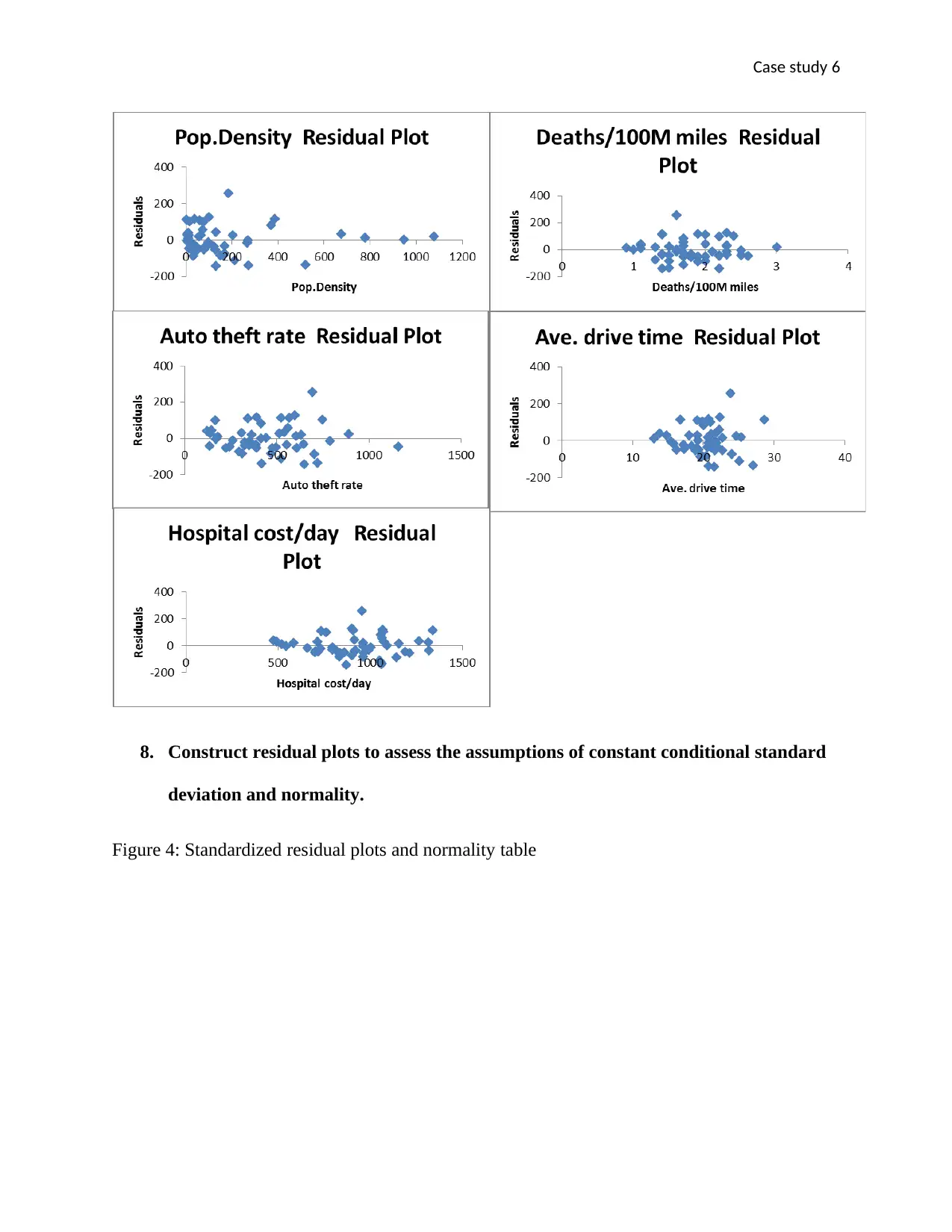
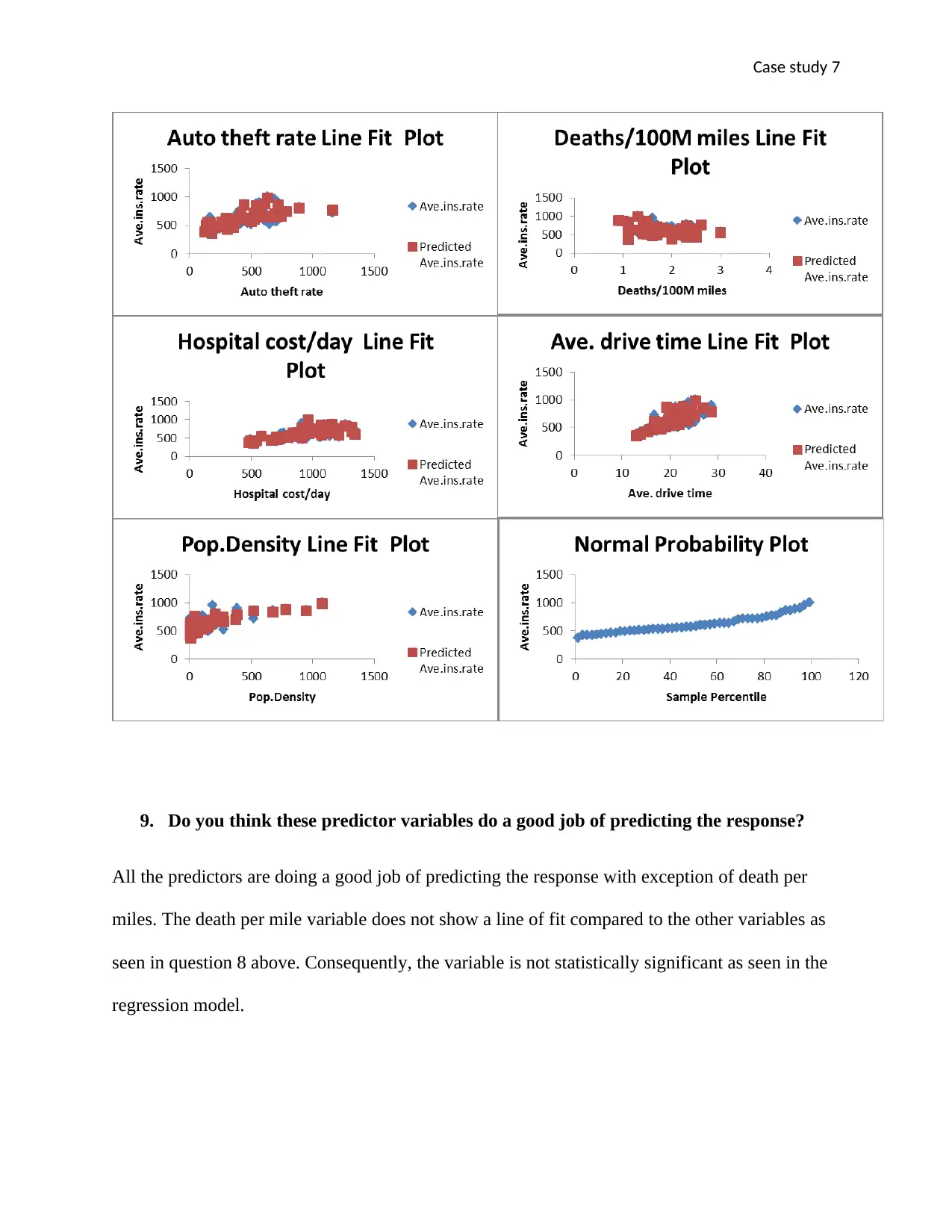
This case study utilizes multiple linear regression to analyze the factors influencing insurance rates. A scatterplot matrix reveals linear relationships between variables, suggesting the appropriateness of a multiple linear regression model. The derived regression equation, Ave.ins.rate = 82.25 + 0.32Pop.Density + 0.15Auto_theft_rate + 28.12Deaths/100M_Miles + 10.97Ave.drive_time + 0.16Hopsital_cost/day, indicates the impact of each predictor variable on the average insurance rate. The adjusted R-squared value of 0.71 signifies that 71% of the variability in insurance rates is explained by the model's variables. However, statistical significance tests suggest that not all predictors should remain in the equation, specifically auto theft rate and deaths per 100m miles. Residual plots are constructed to assess the model's assumptions and appropriateness, revealing that most predictors perform well in predicting the response variable, except for death per miles. Desklib provides this and other solved assignments to aid students in their studies.




1 out of 7
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.