International Business Statistics Report: Data Analysis and Findings
VerifiedAdded on 2023/01/17
|10
|1787
|85
Report
AI Summary
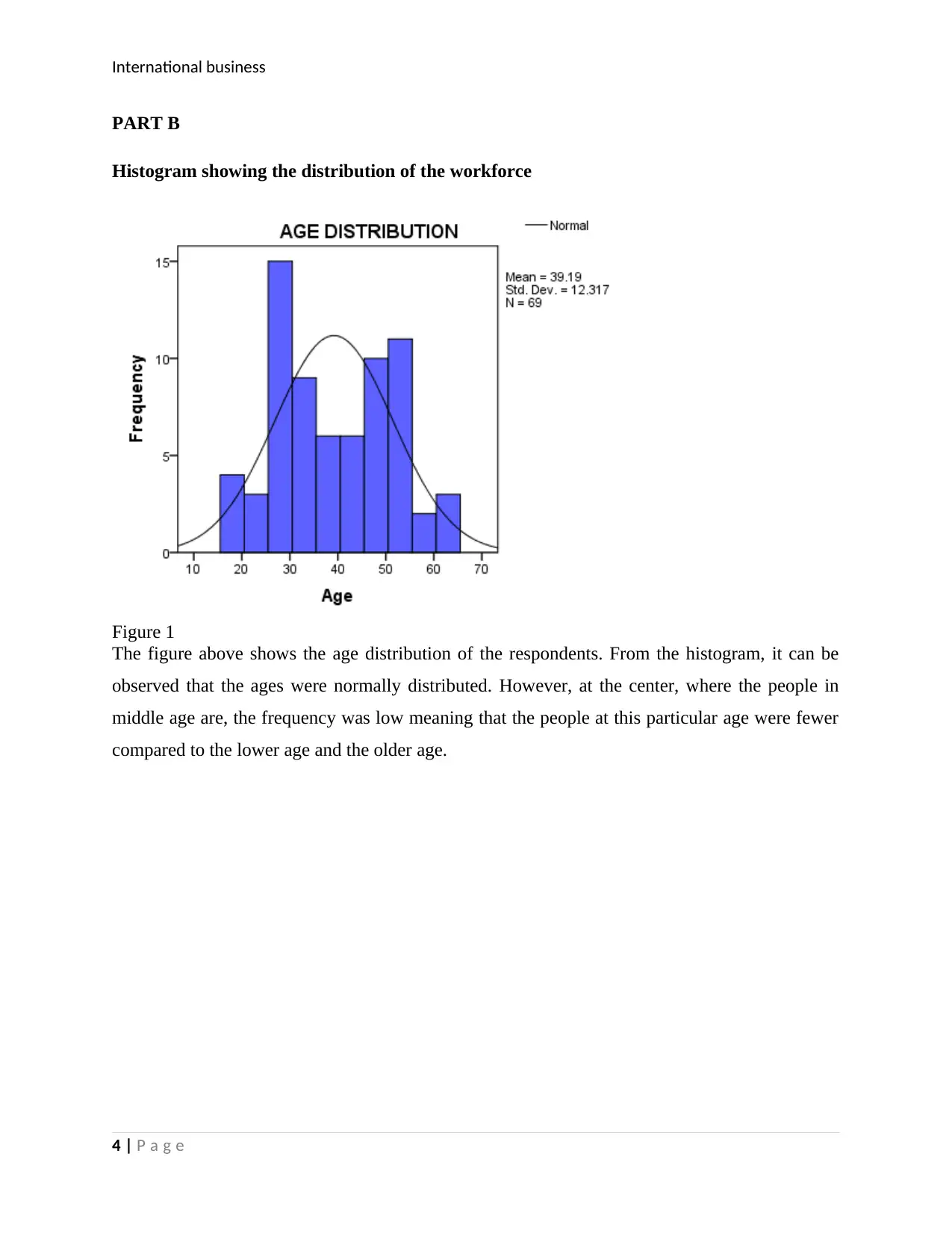
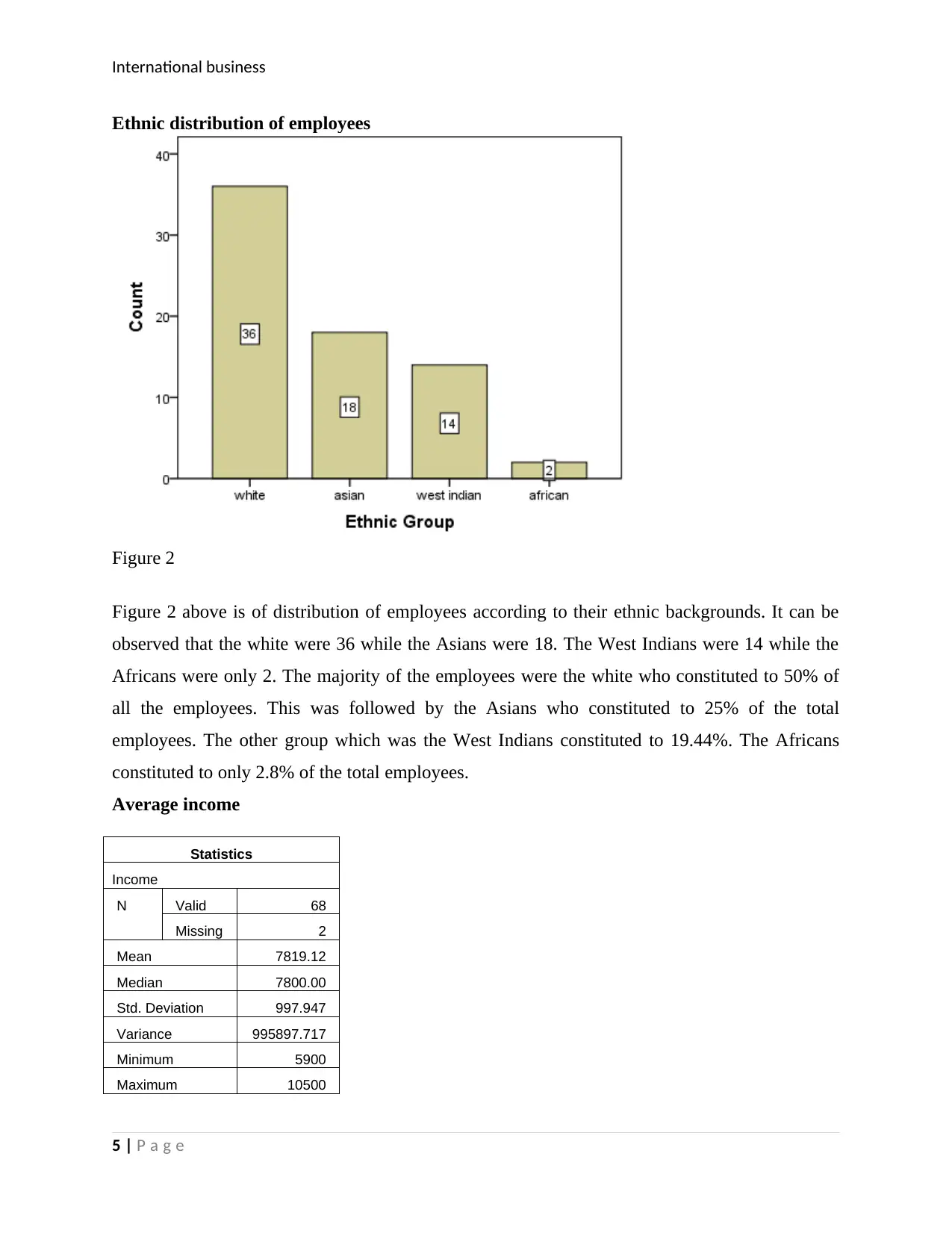
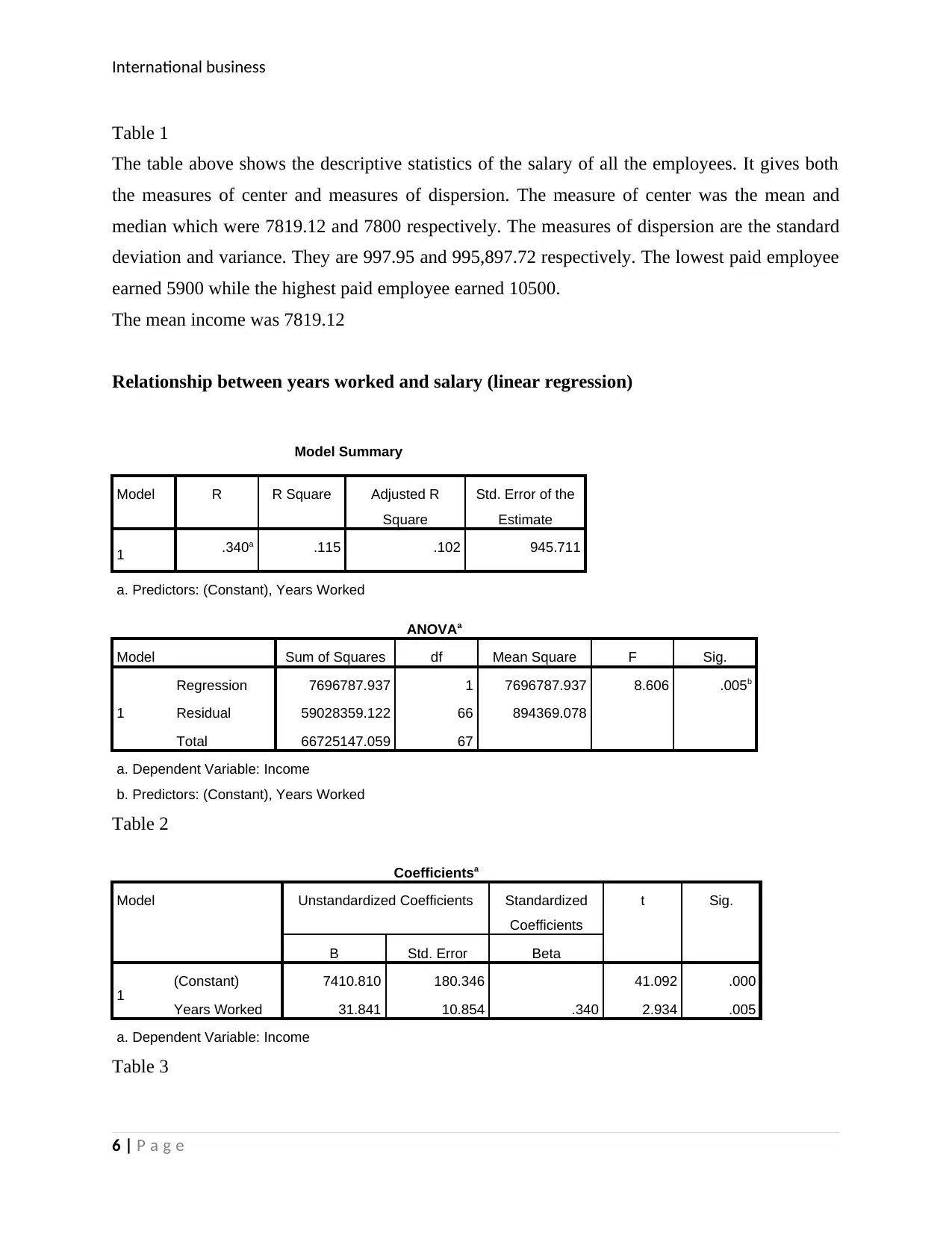
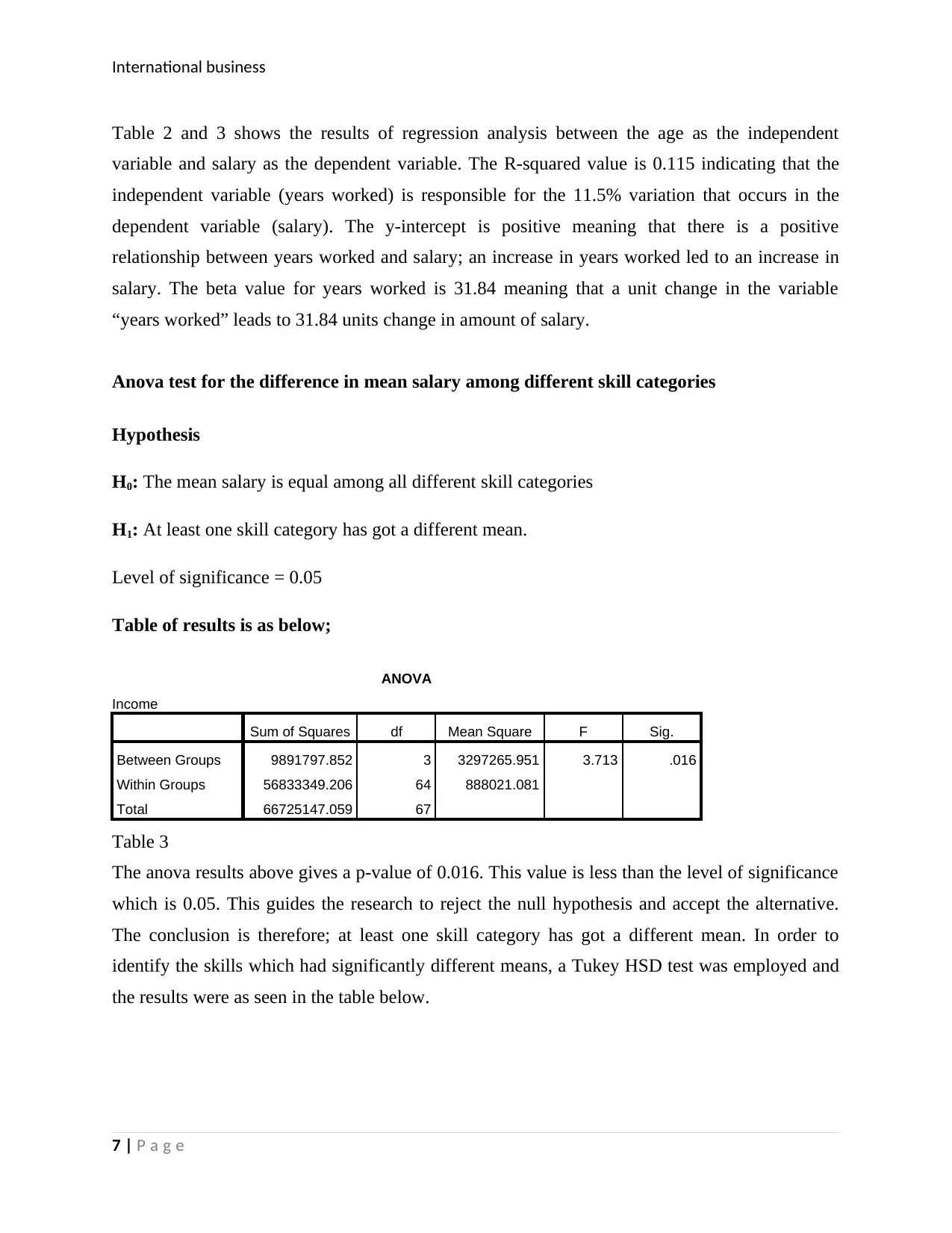
This report presents an analysis of international business statistics, focusing on a research study conducted by a local council regarding the recycling of food waste and the potential of biogas production. The report begins with a data requirement table outlining the research objectives, sampling method (simple random sampling), and data collection tool (semi-structured questionnaire). Part B of the report includes data analysis using histograms, and tables to display findings on employee demographics, income statistics, and the relationship between years worked and salary using linear regression. Furthermore, the report explores the difference in mean salary among different skill categories using ANOVA and Tukey HSD tests. Finally, the report examines the difference between proportions of males and females who attended a firm's meeting using a Chi-square test. The results of these statistical analyses are presented with interpretations, conclusions, and relevant tables. References are also provided.




1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.