Analysis of Inverted Index, Boolean and Vector Queries in AI
VerifiedAdded on 2020/05/16
|12
|1059
|68
Homework Assignment
AI Summary
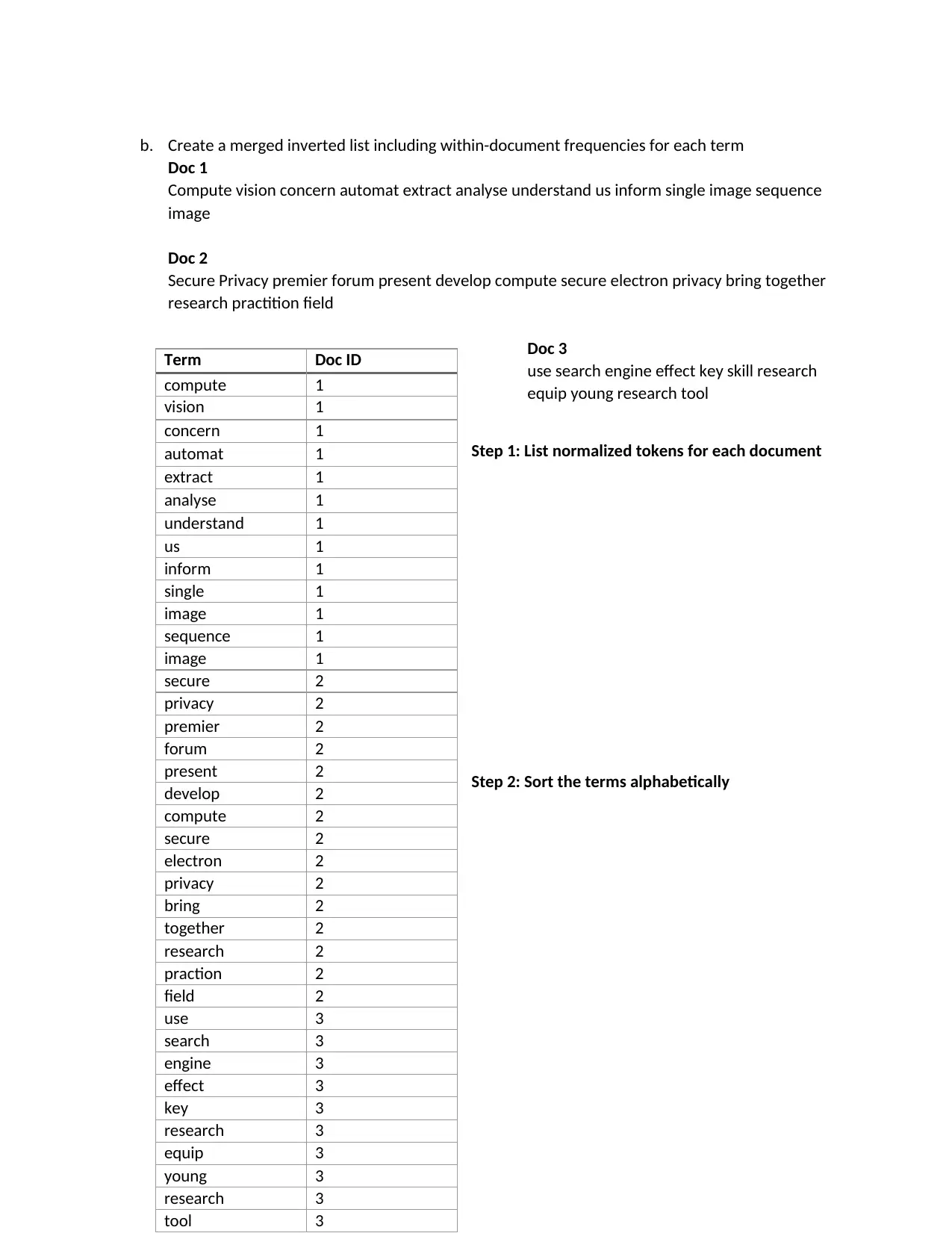
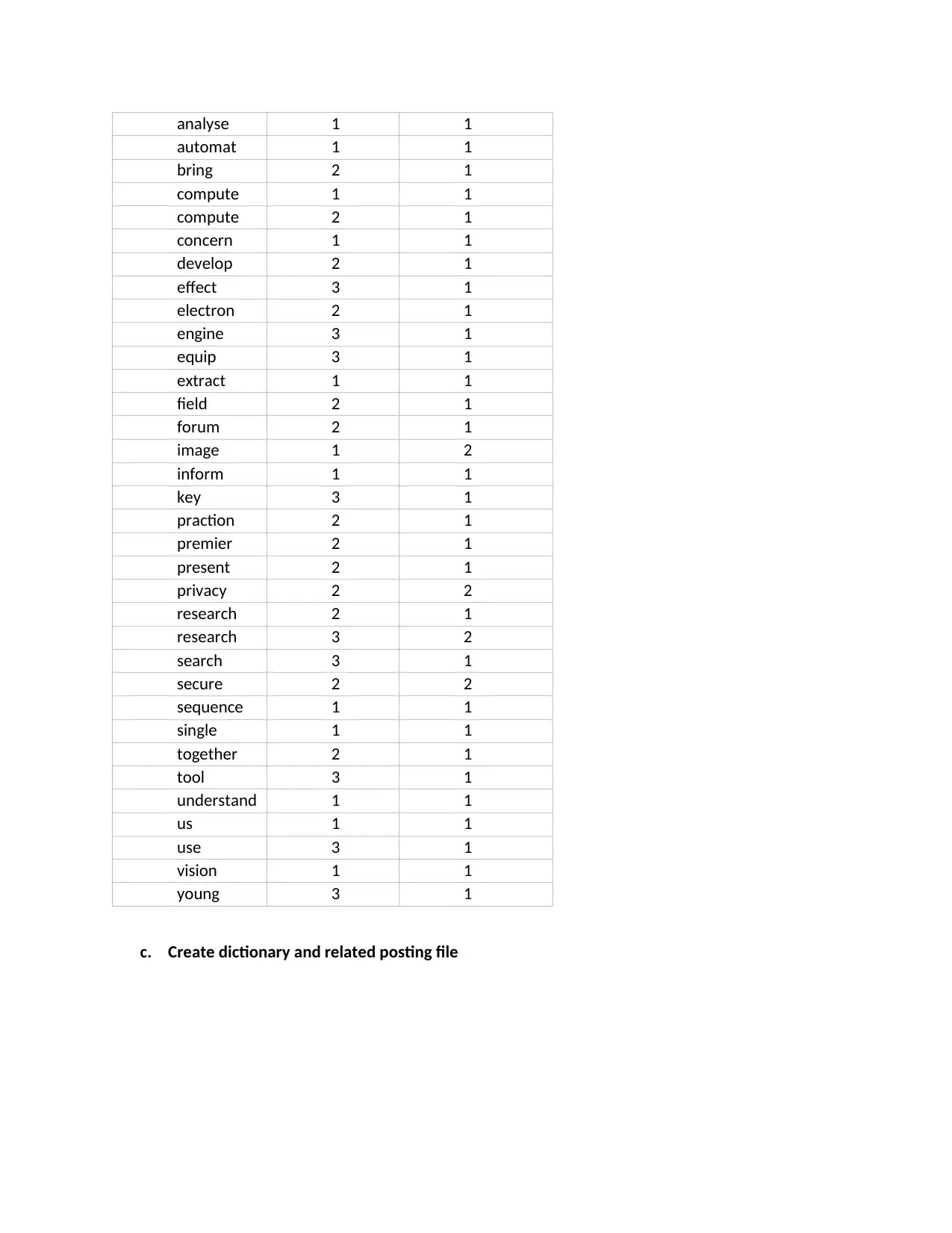
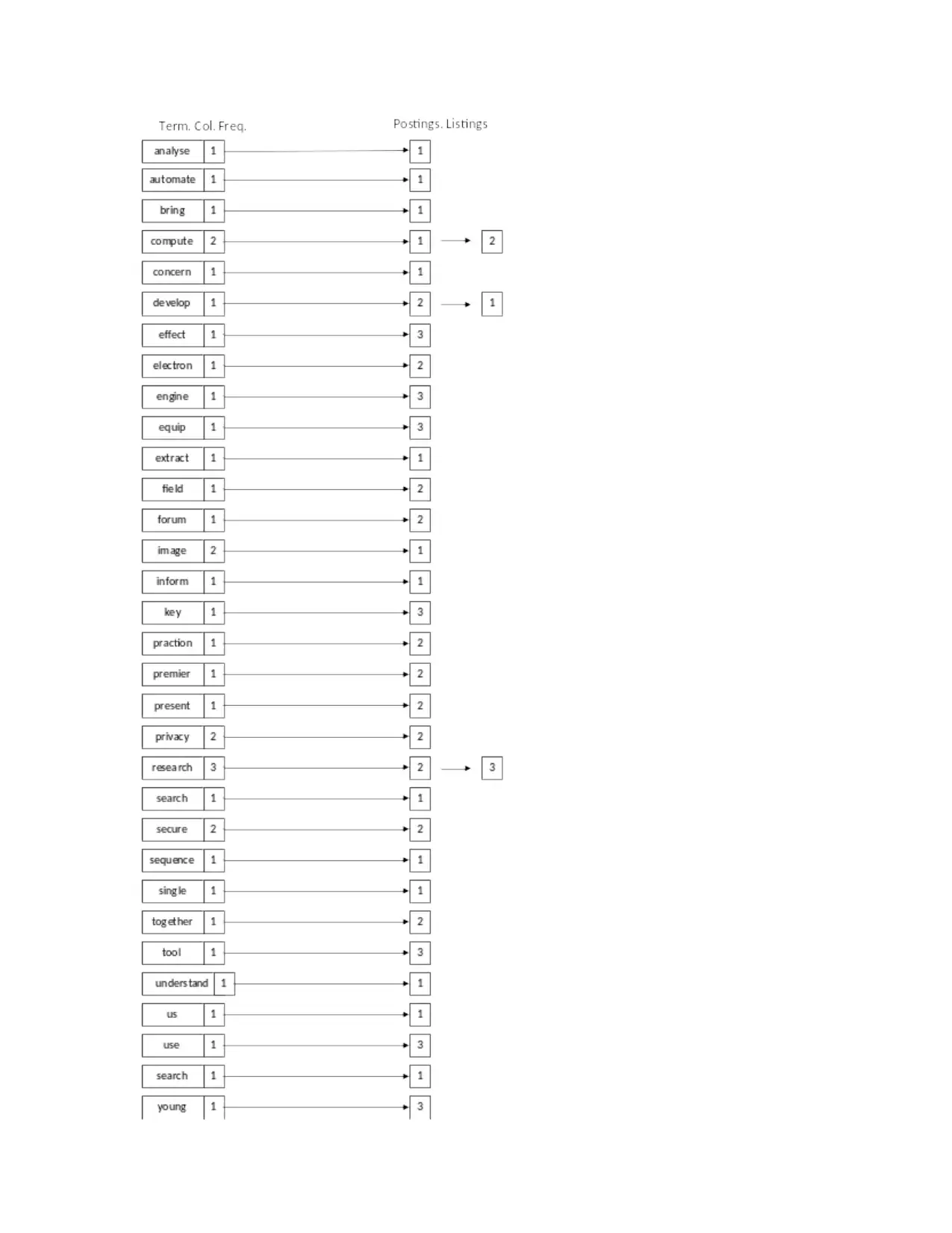
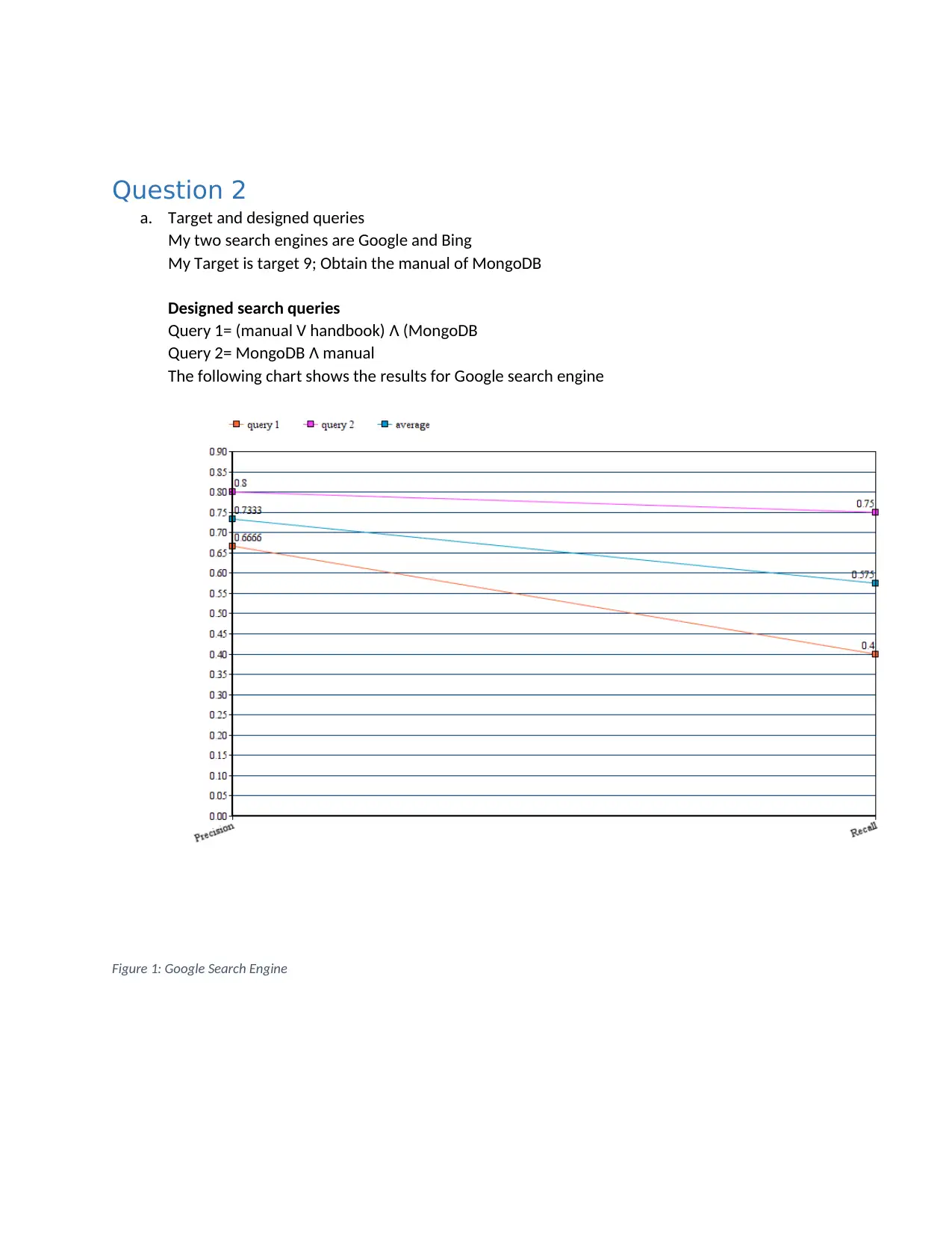
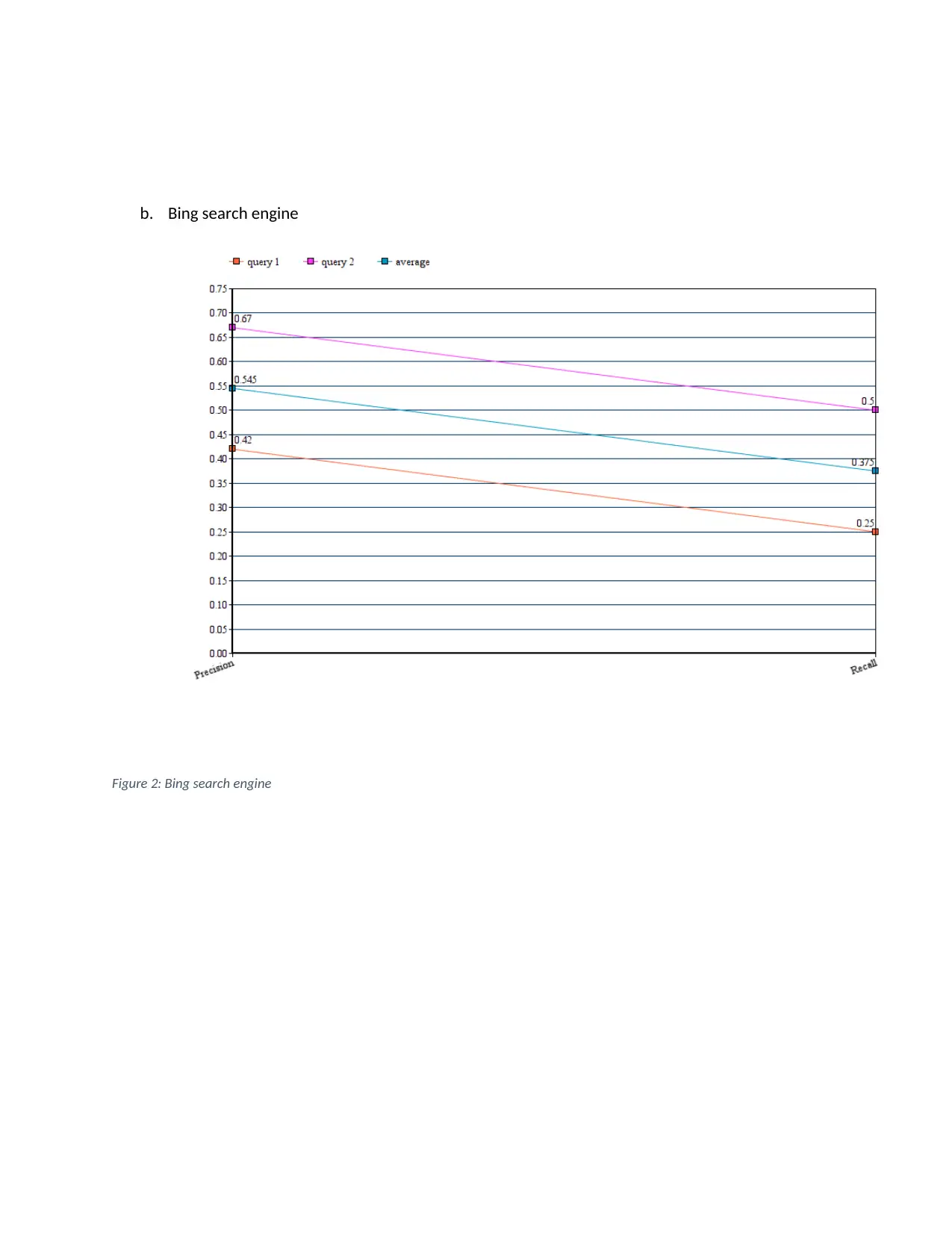
This assignment explores core concepts in information retrieval and search engine technology. It begins by constructing an inverted index for a set of documents, detailing the steps of tokenization, stop word removal, stemming, and merging terms with document frequencies. The solution then applies Boolean and vector queries, specifically cosine similarity, to retrieve relevant documents based on search terms. A comparative analysis is performed between Boolean and vector models, highlighting the vector model's accuracy. Furthermore, the assignment evaluates two search engines, Google and Bing, using designed queries to find a MongoDB manual, comparing their performance based on precision and recall, and concluding that Google is superior. The document includes a bibliography referencing key information retrieval sources.







1 out of 12

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.