Research Report: Computer Usage on UOW Library Ground Floor
VerifiedAdded on 2021/06/15
|6
|1543
|162
Report
AI Summary
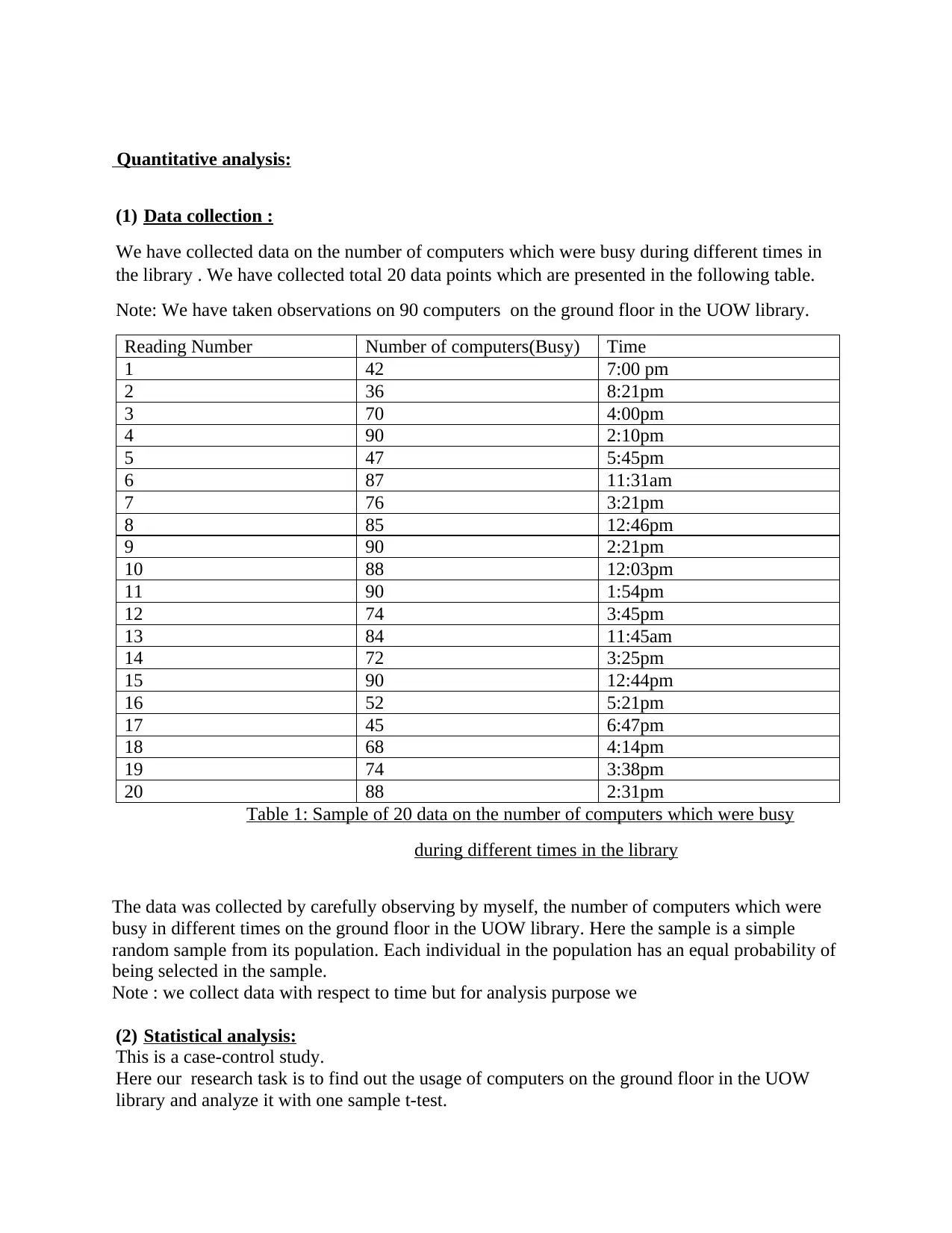
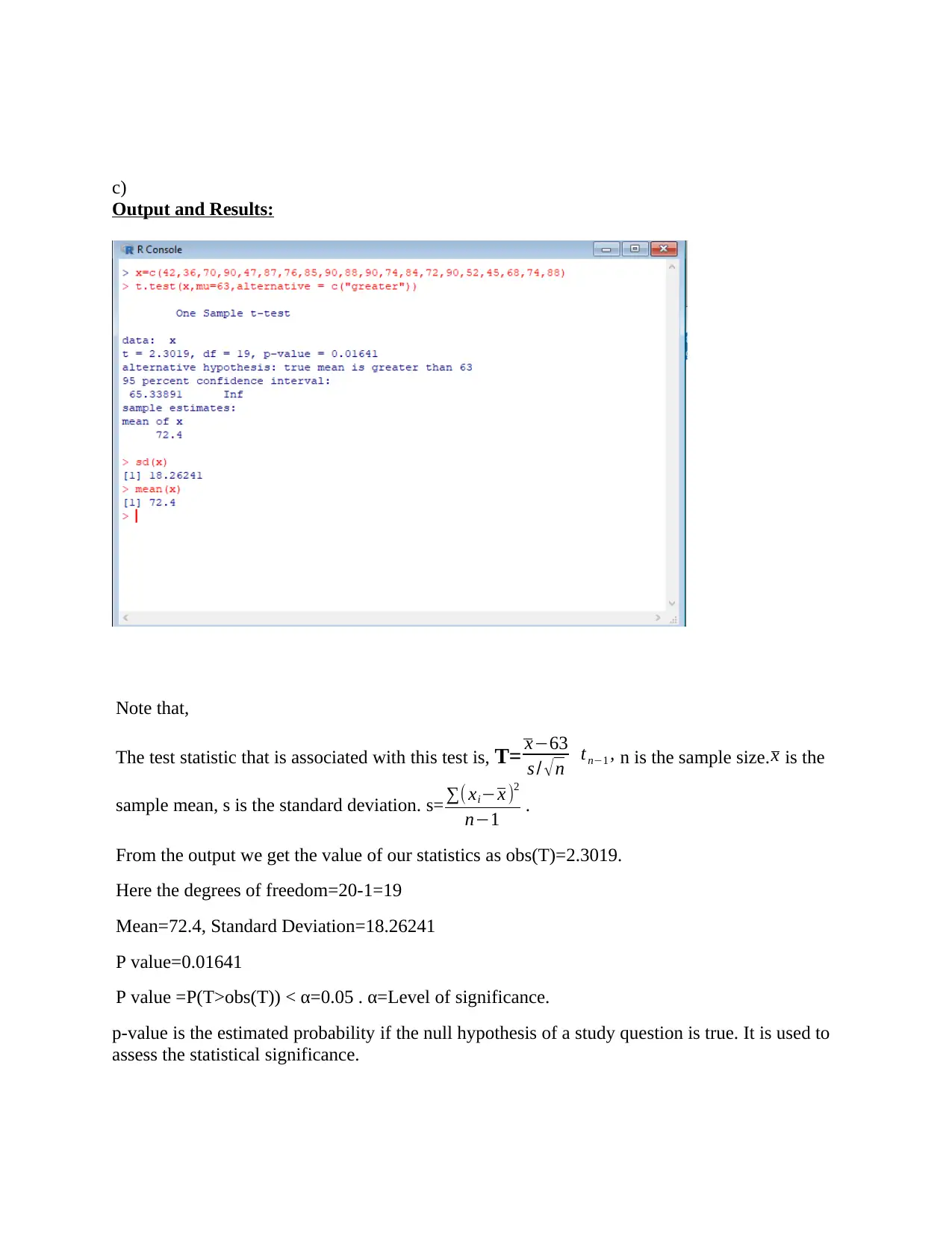
This report presents a statistical analysis of computer usage on the ground floor of the UOW library. The study aimed to determine whether the current number of computers is sufficient to meet student demand. Data was collected over 20 observations, recording the number of occupied computers at different times. A one-sample t-test was employed to analyze the data, comparing the observed usage against a threshold of 70% occupancy. The results of the t-test, including the test statistic, degrees of freedom, mean, standard deviation, and p-value, are presented. The analysis concluded that the library should provide more computers for students on the ground floor. The report includes a discussion of the statistical methods, assumptions, and a formal report. The report also includes an appendix defining key statistical terms and suggests further research directions, such as collecting more data and analyzing the impact of adding more computers.




1 out of 6
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.