Machine Learning Classification: Algorithms and Performance Report
VerifiedAdded on 2022/11/09
|10
|1323
|244
Report
AI Summary
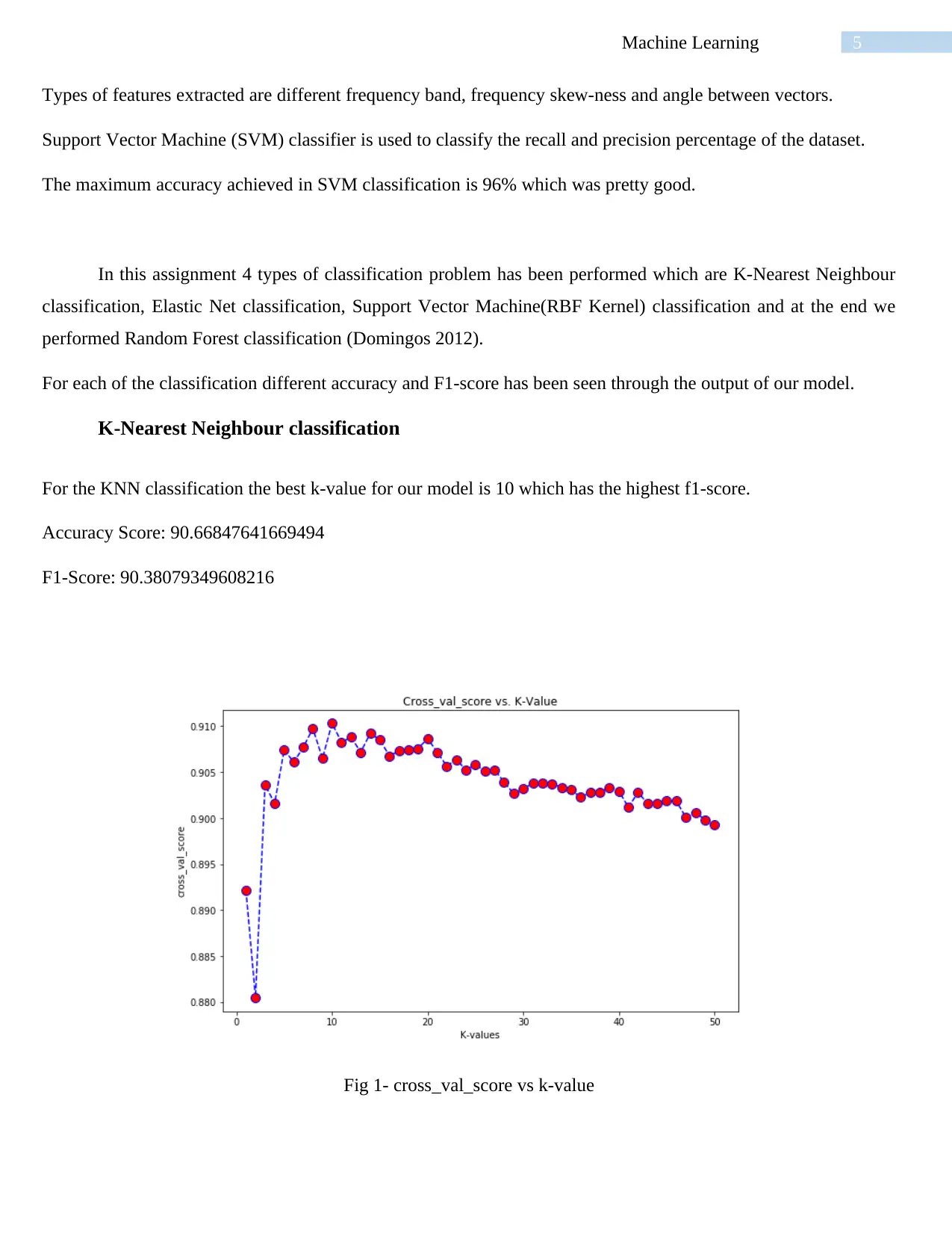
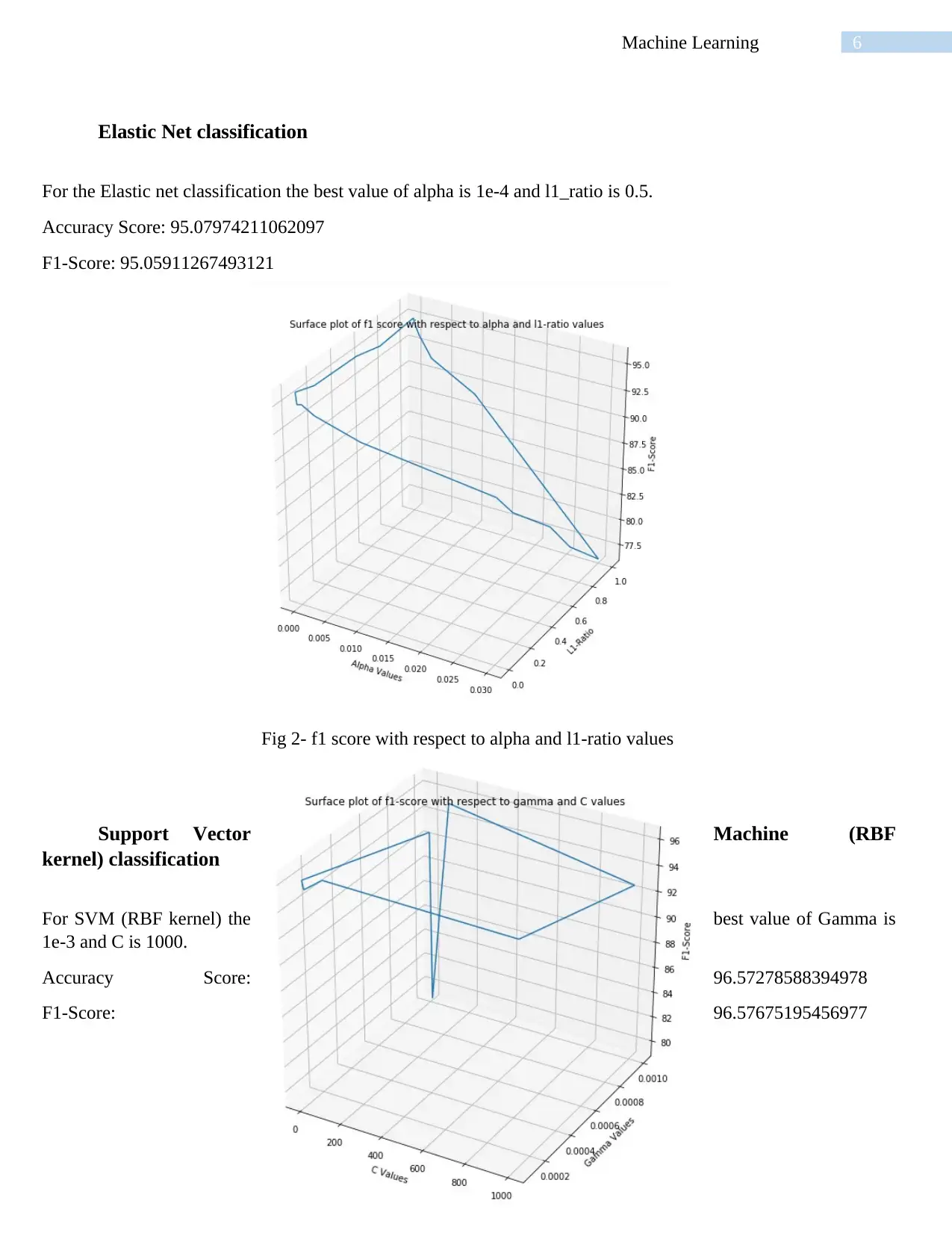
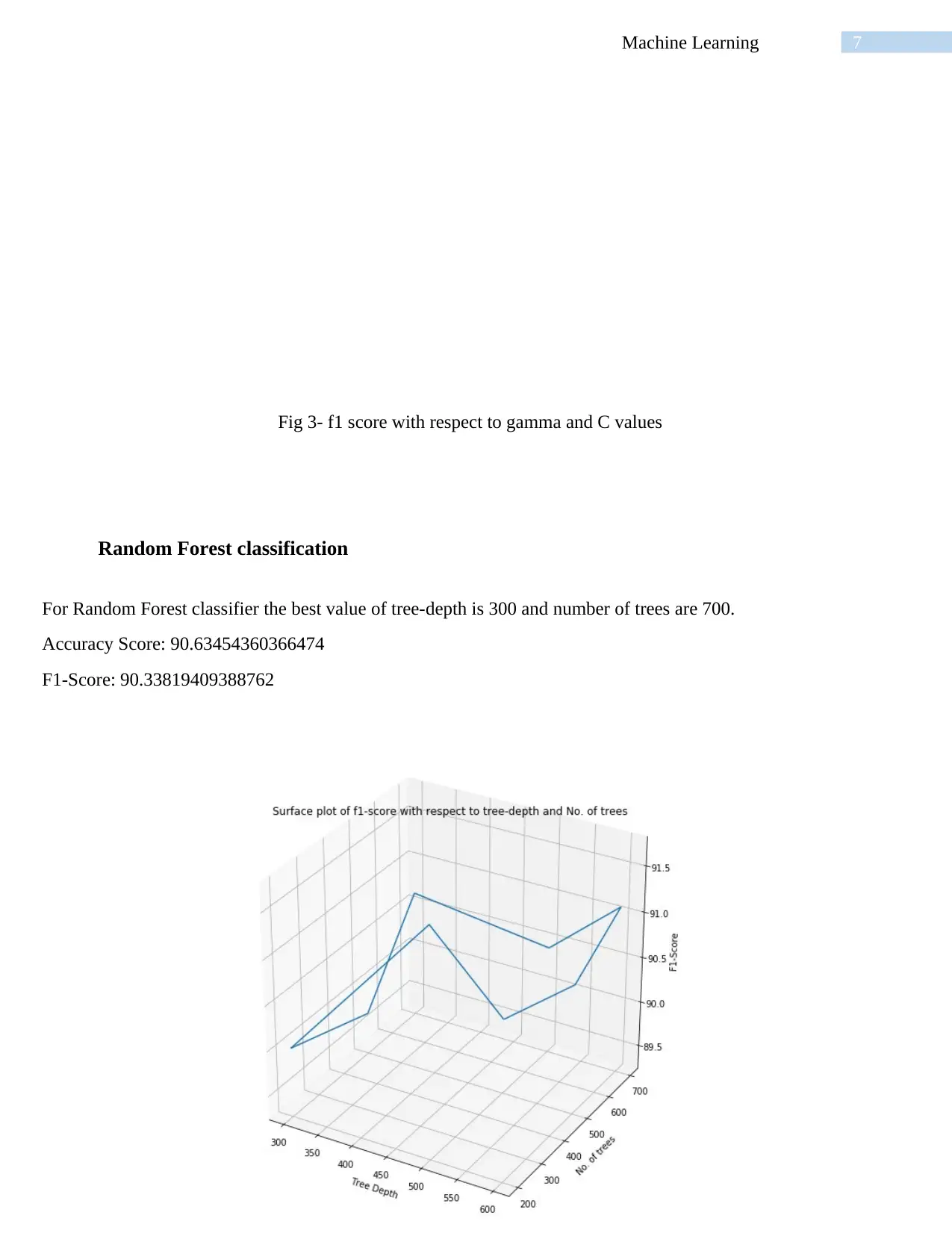
This report presents a detailed analysis of machine learning classification techniques, focusing on the performance of various algorithms on a human activity recognition dataset. The study evaluates four classification methods: K-Nearest Neighbor (KNN), Elastic Net, Support Vector Machine (SVM) with an RBF kernel, and Random Forest. The report provides an executive summary, introduction to machine learning concepts (supervised and unsupervised learning), and a discussion of the data collection process, involving 30 volunteers performing static and dynamic activities. Each classification technique is assessed using accuracy and F1-score metrics, with the optimal hyperparameter settings for each model. The results reveal that SVM (RBF kernel) achieves the highest accuracy and F1-score, outperforming the other algorithms. The report concludes with a discussion of the findings, highlighting the strengths and weaknesses of each method, and suggests future directions for improving classification accuracy by exploring additional algorithms.







1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.