Machine Learning for Student Success: ABCEU Project Report Analysis
VerifiedAdded on 2023/01/11
|23
|5105
|51
Report
AI Summary
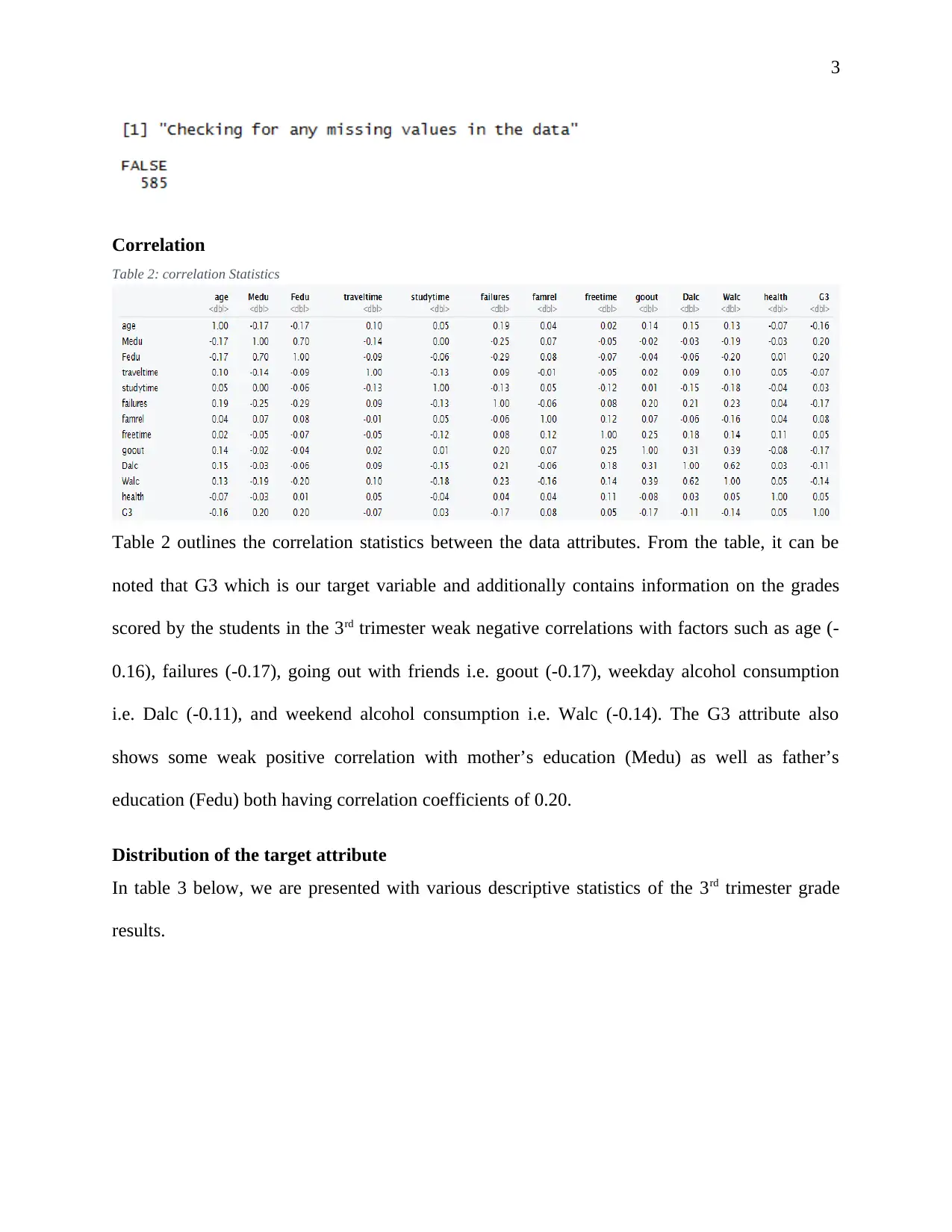
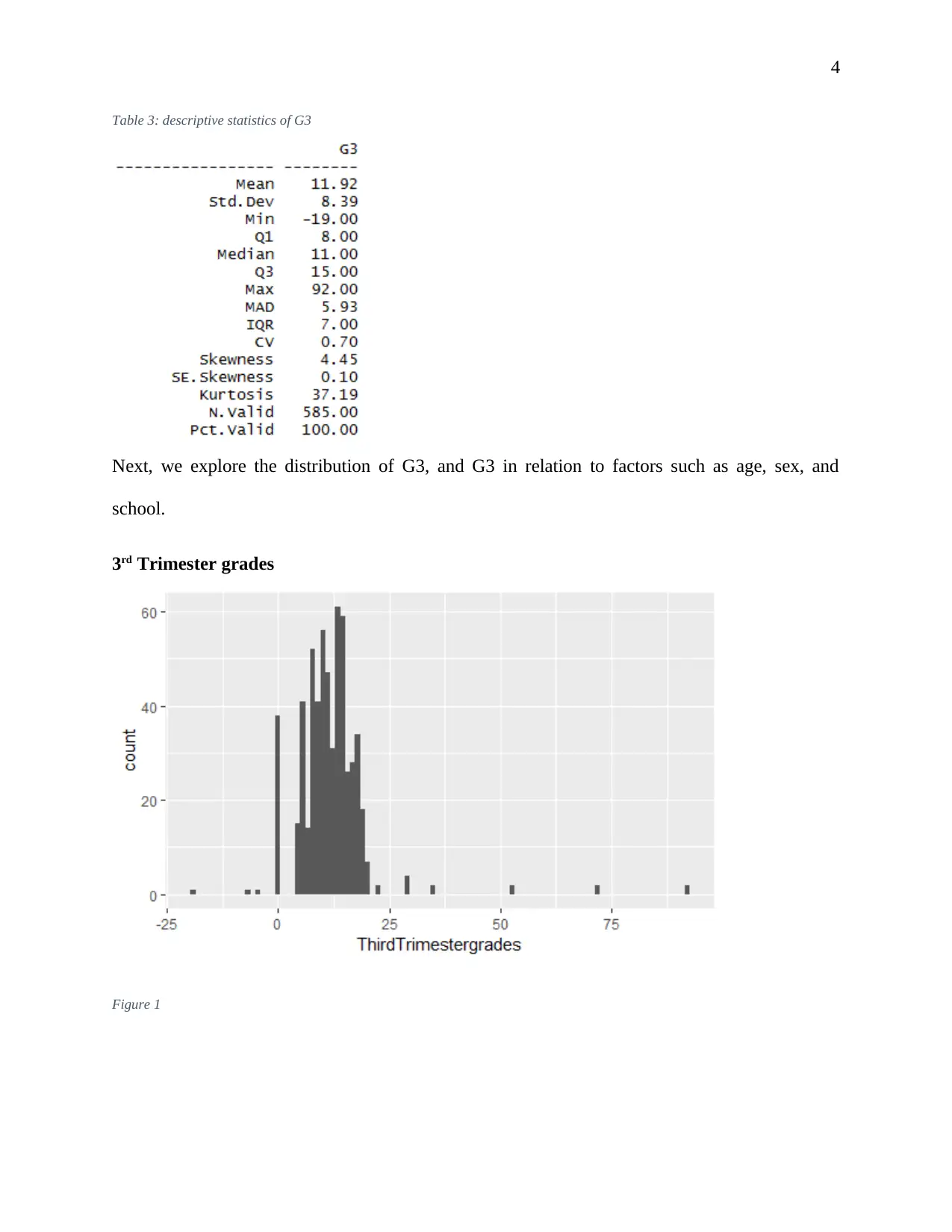
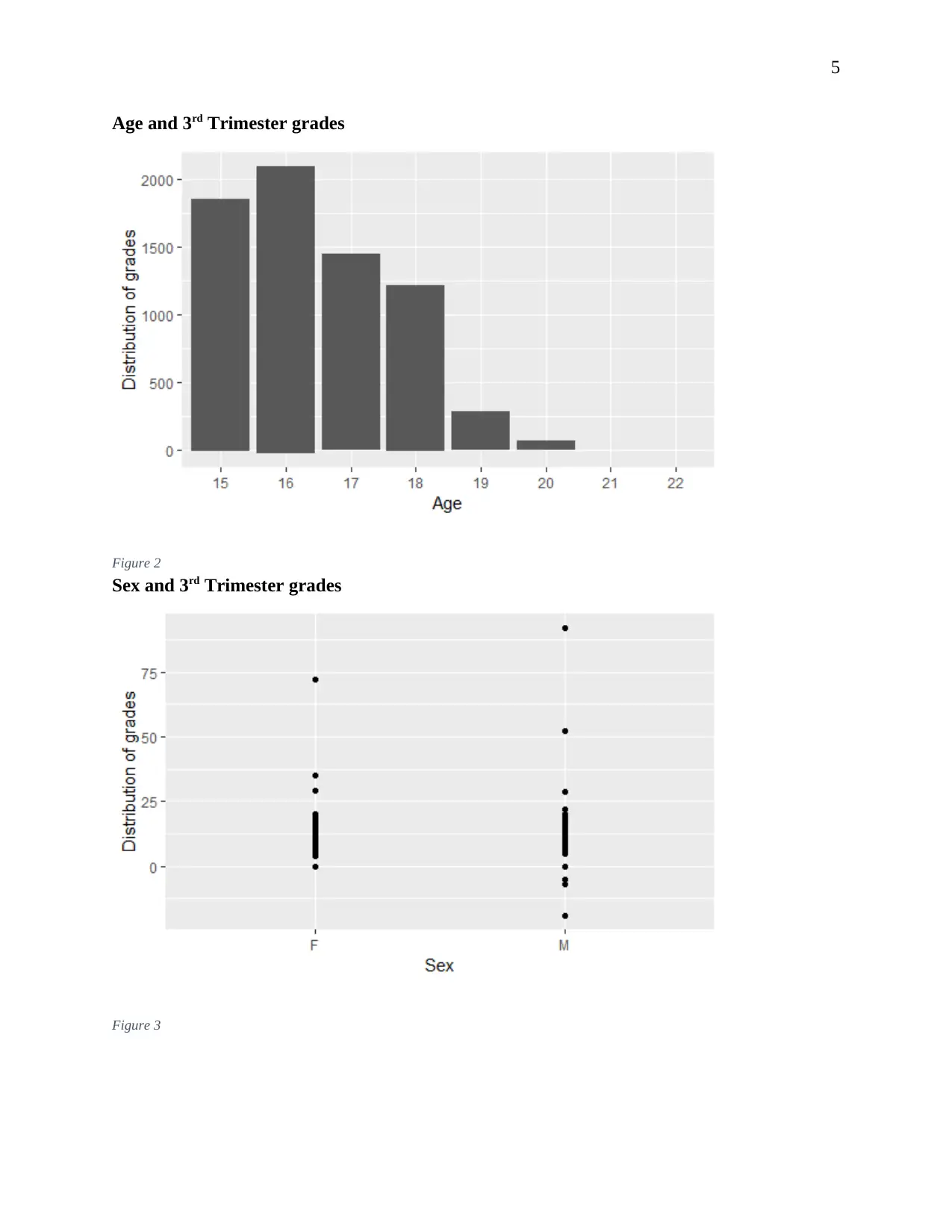
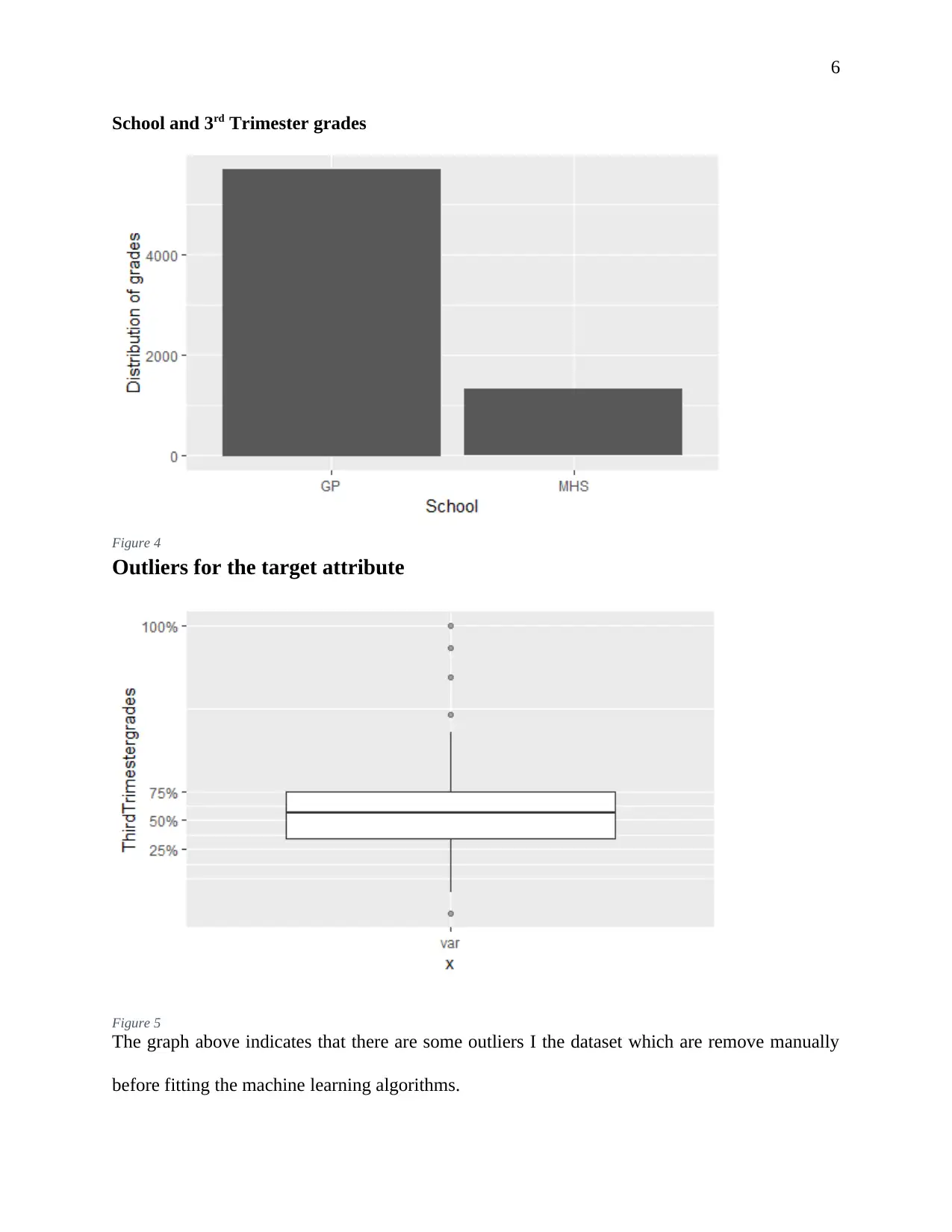
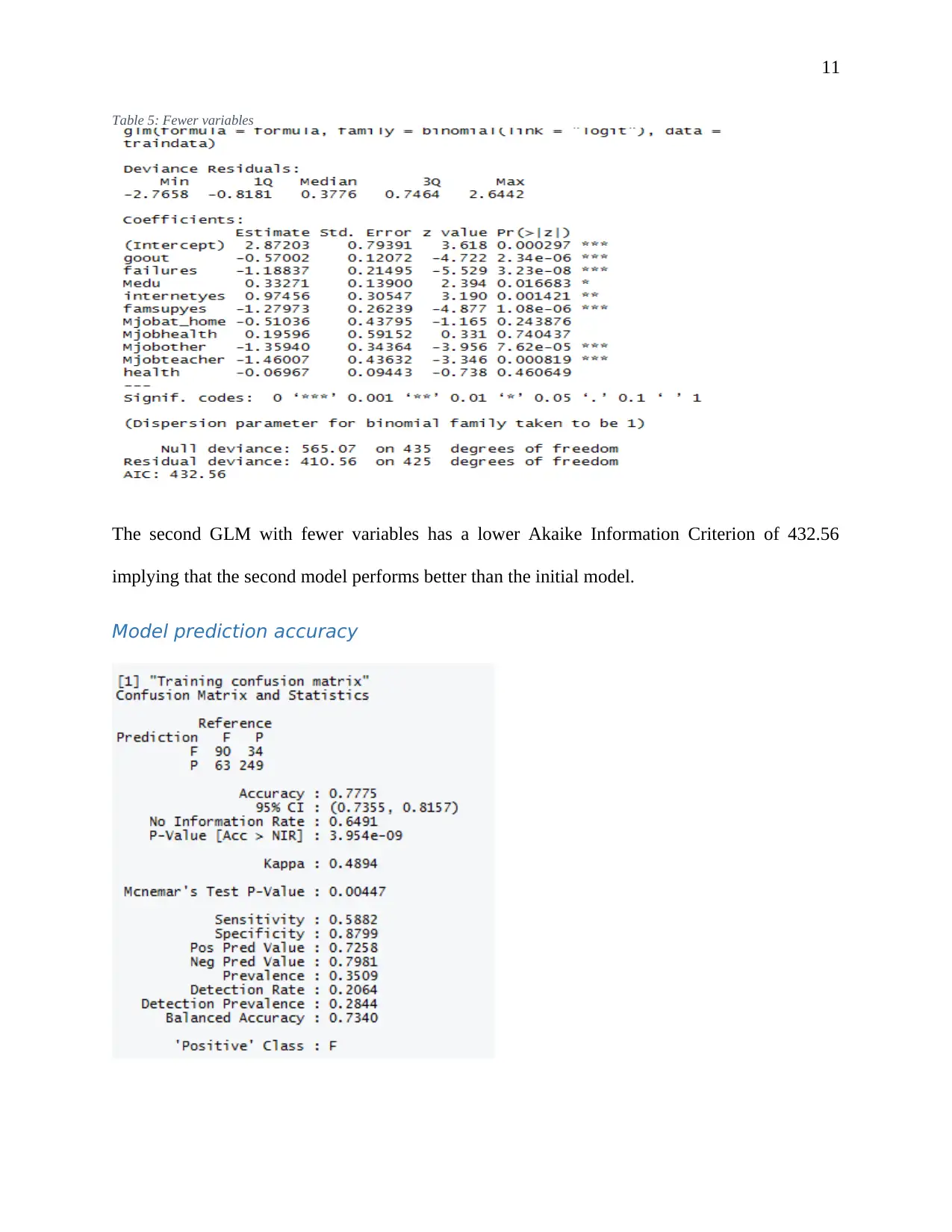
This report presents an analysis of student data from ABC Universal Education (ABCEU) to predict pass rates using machine learning techniques. The objective is to identify factors that significantly influence student success. The analysis employs a data-driven approach, utilizing machine learning algorithms including Decision Trees, Random Forest, and Generalized Linear Models (GLM). After data exploration and feature selection, the models are implemented in R, and their performance is evaluated using metrics such as accuracy, sensitivity, specificity, and the confusion matrix. The Random Forest model demonstrates the highest accuracy. The report includes an executive summary, data exploration, feature selection, model selection, and validation. The findings provide insights into the most relevant factors determining student pass rates, offering ABCEU actionable recommendations to improve student outcomes.







1 out of 23
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.