ECON634: Macquarie University Econometrics Take-home Test Solutions
VerifiedAdded on 2023/06/04
|14
|1832
|429
Homework Assignment
AI Summary
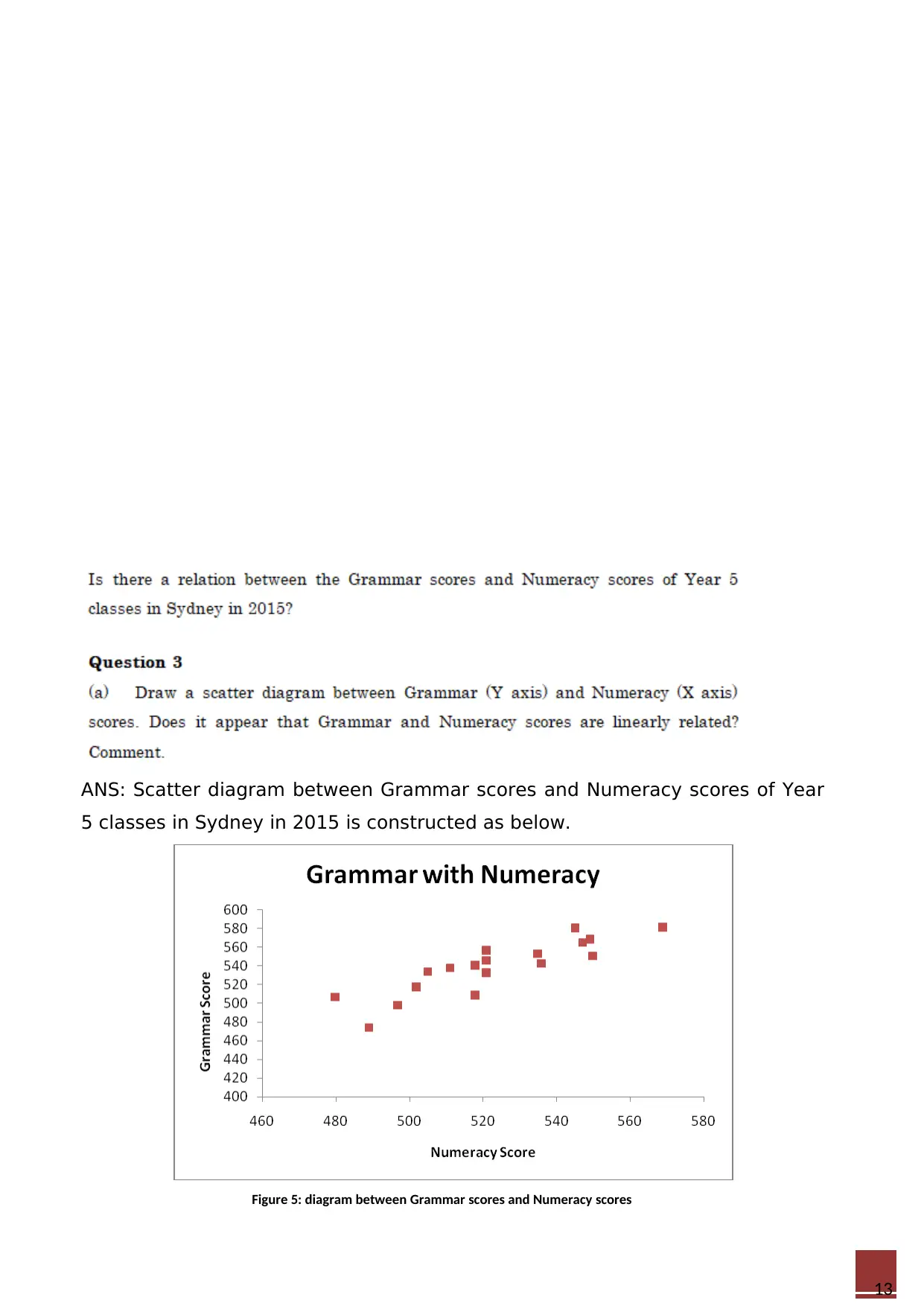
This document presents solutions to the ECON634 Econometrics and Business Statistics take-home test from Semester 2, 2018. The solutions cover various statistical concepts including hypothesis testing, confidence intervals, and regression analysis. The test assesses the application of these concepts through a series of problems involving sampling distributions, the central limit theorem, and comparisons of population means and proportions. The solutions include detailed calculations, interpretations of results, and the use of statistical tests such as t-tests, z-tests, and F-tests. Furthermore, the assignment addresses topics such as descriptive statistics, confidence interval estimations, and the interpretation of regression models. The analysis incorporates the use of Excel for statistical calculations and graphical representations, providing a comprehensive understanding of the statistical methods used to analyze business data. The assignment includes references to relevant literature, demonstrating a strong understanding of the subject matter.







1 out of 14
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.