Management Science: Regression and Hypothesis Testing Solutions
VerifiedAdded on 2023/04/24
|13
|2242
|369
Homework Assignment
AI Summary
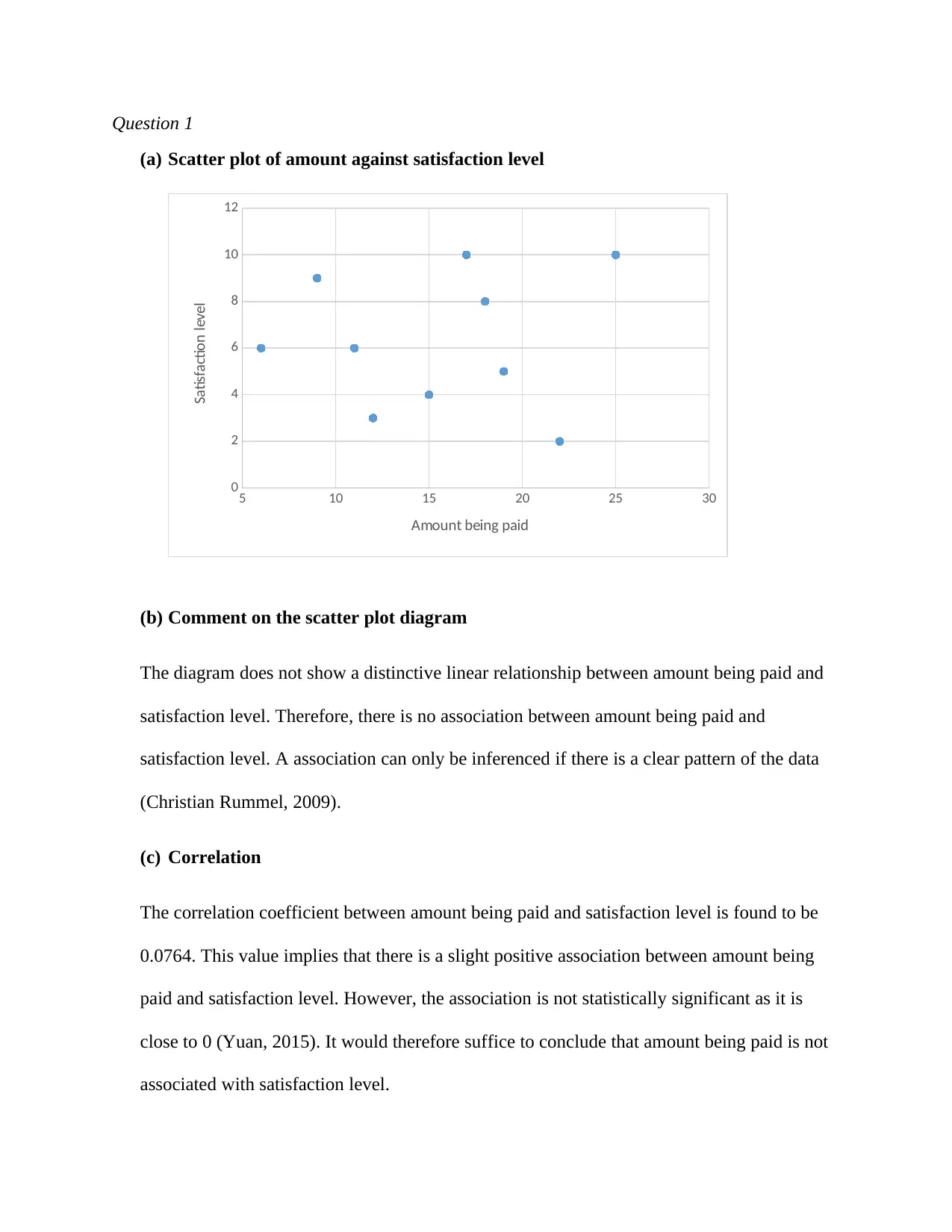
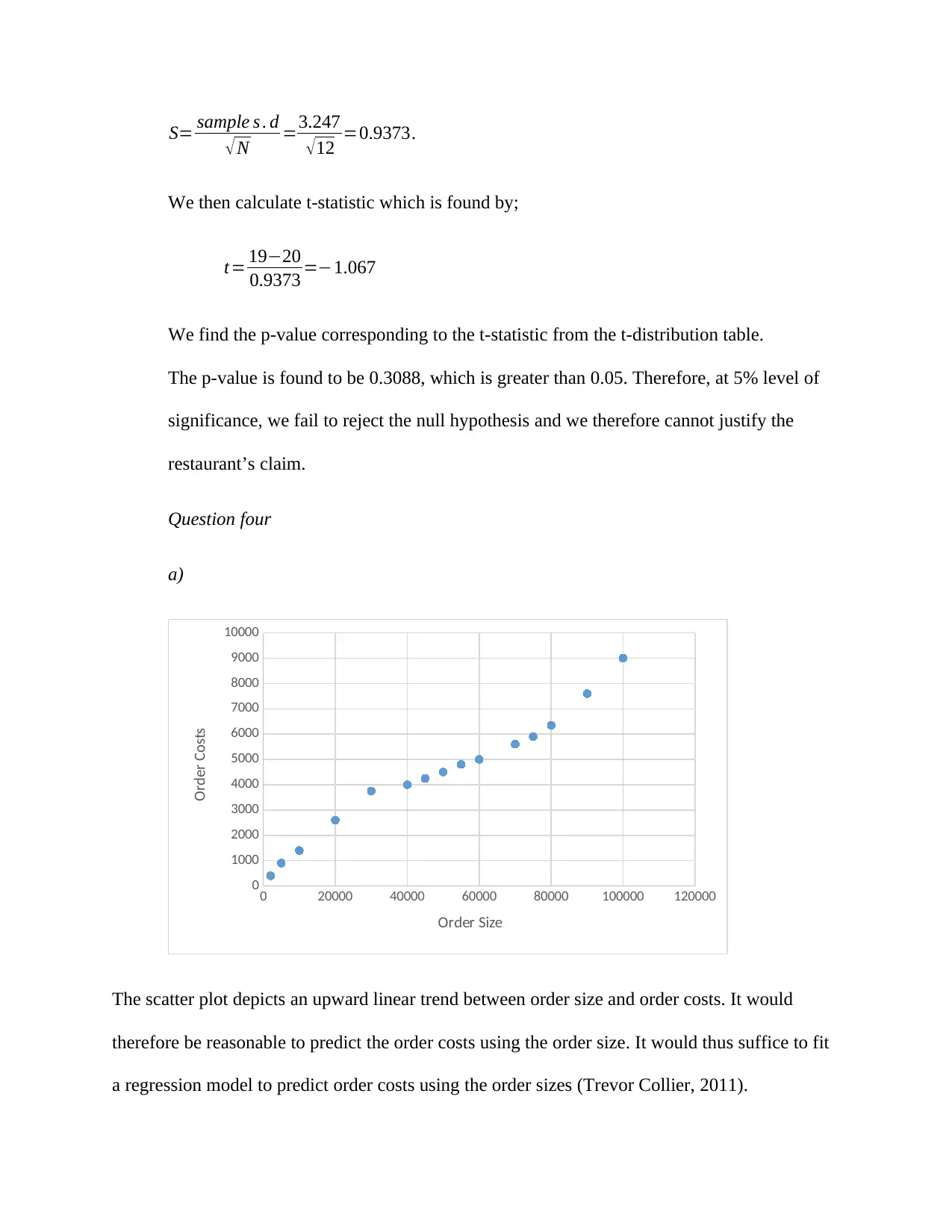
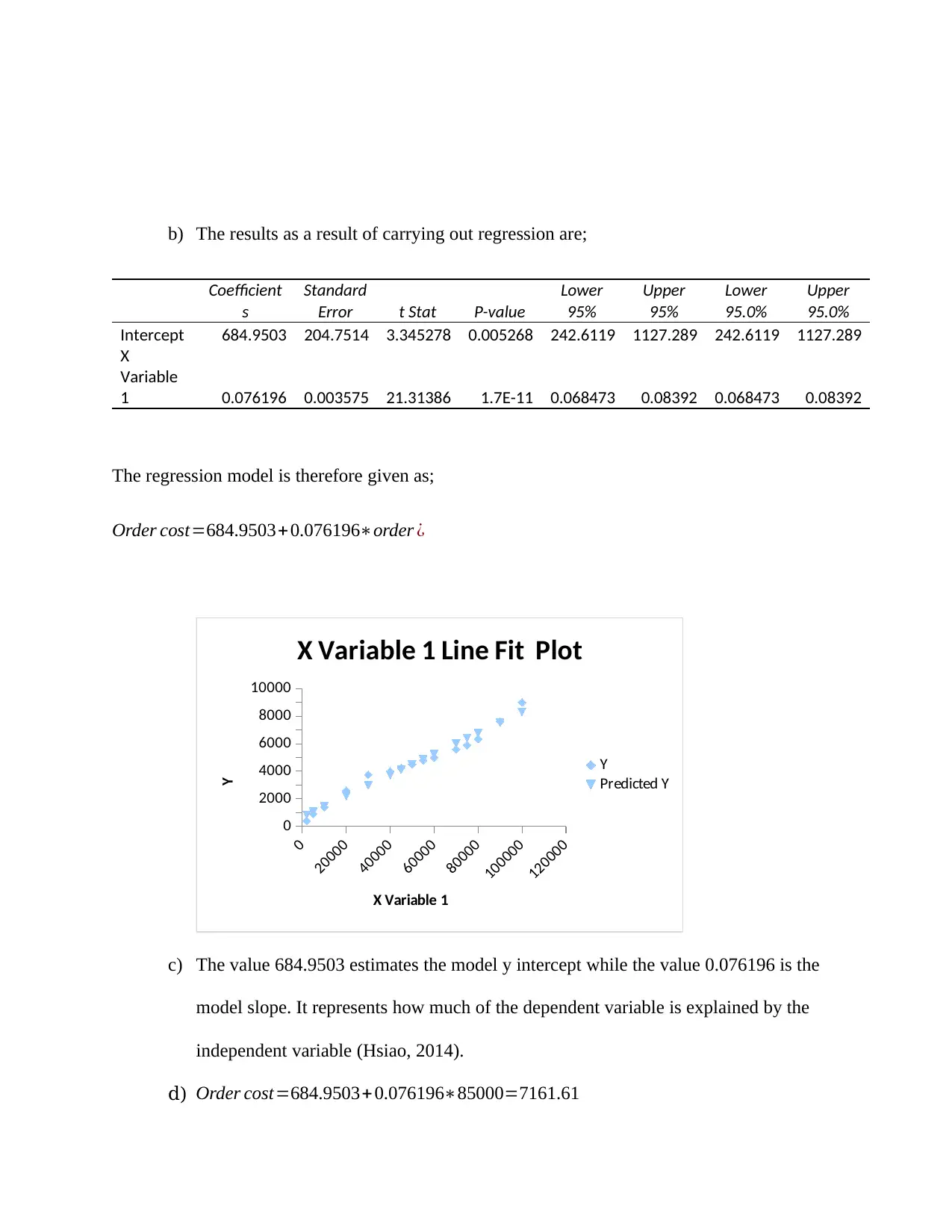
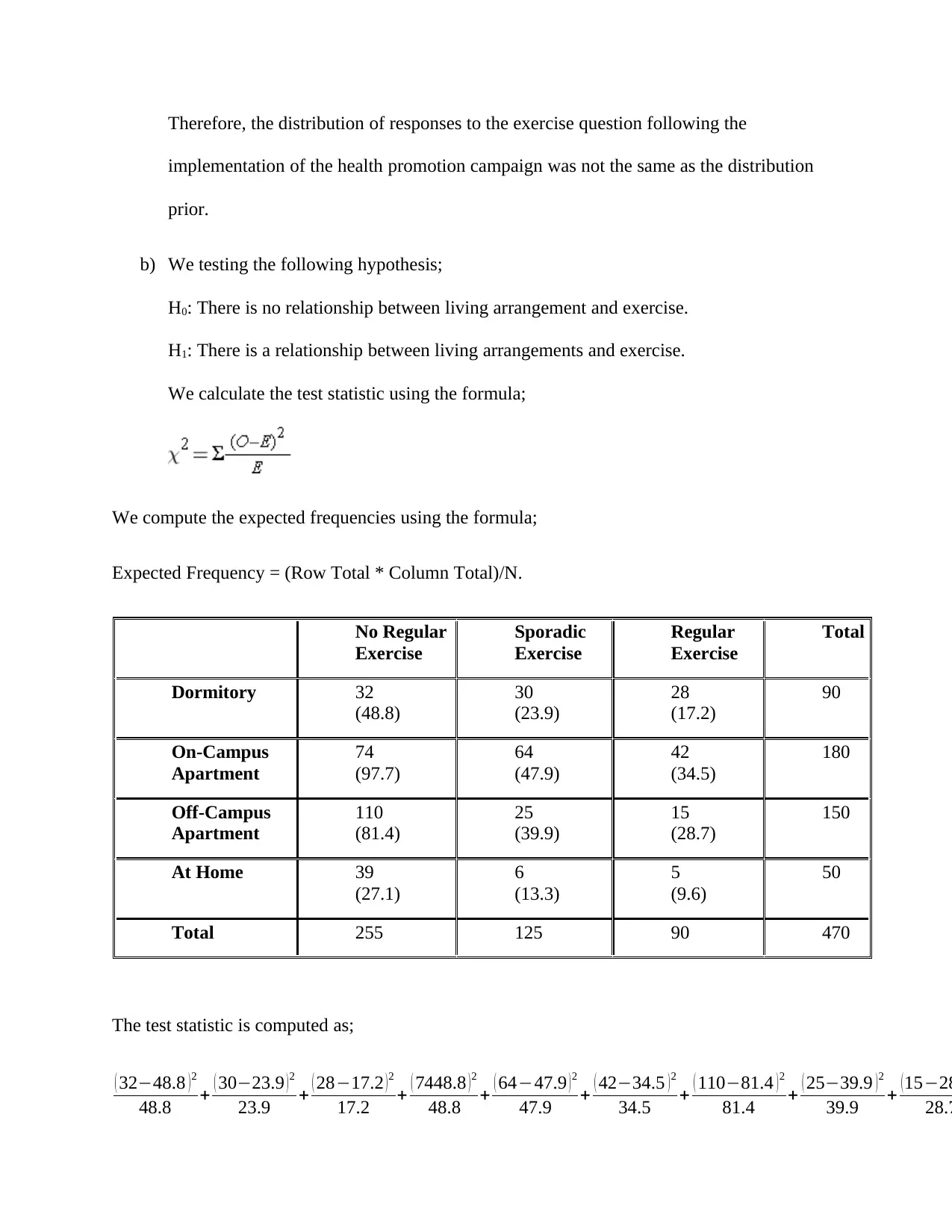
This assignment solution covers several statistical analyses within the context of Management Science. It includes the creation and interpretation of a scatter plot to assess the relationship between amount paid and satisfaction level, calculation and explanation of the correlation coefficient and R-squared value, and the derivation and application of a regression model to predict satisfaction levels based on cost. The solution also addresses hypothesis testing, including a test of proportions related to credit union mergers and a t-test to evaluate restaurant claims, along with chi-square tests to analyze the impact of health promotion campaigns and the relationship between living arrangements and exercise habits. Finally, it covers point estimates, confidence intervals, and hypothesis testing for comparing customer satisfaction ratings between two companies. Each question provides detailed calculations, interpretations, and conclusions based on statistical significance.








1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.