Quantitative Business Analysis: Hierarchical Clustering for UPS
VerifiedAdded on 2022/08/28
|10
|1780
|18
Project
AI Summary
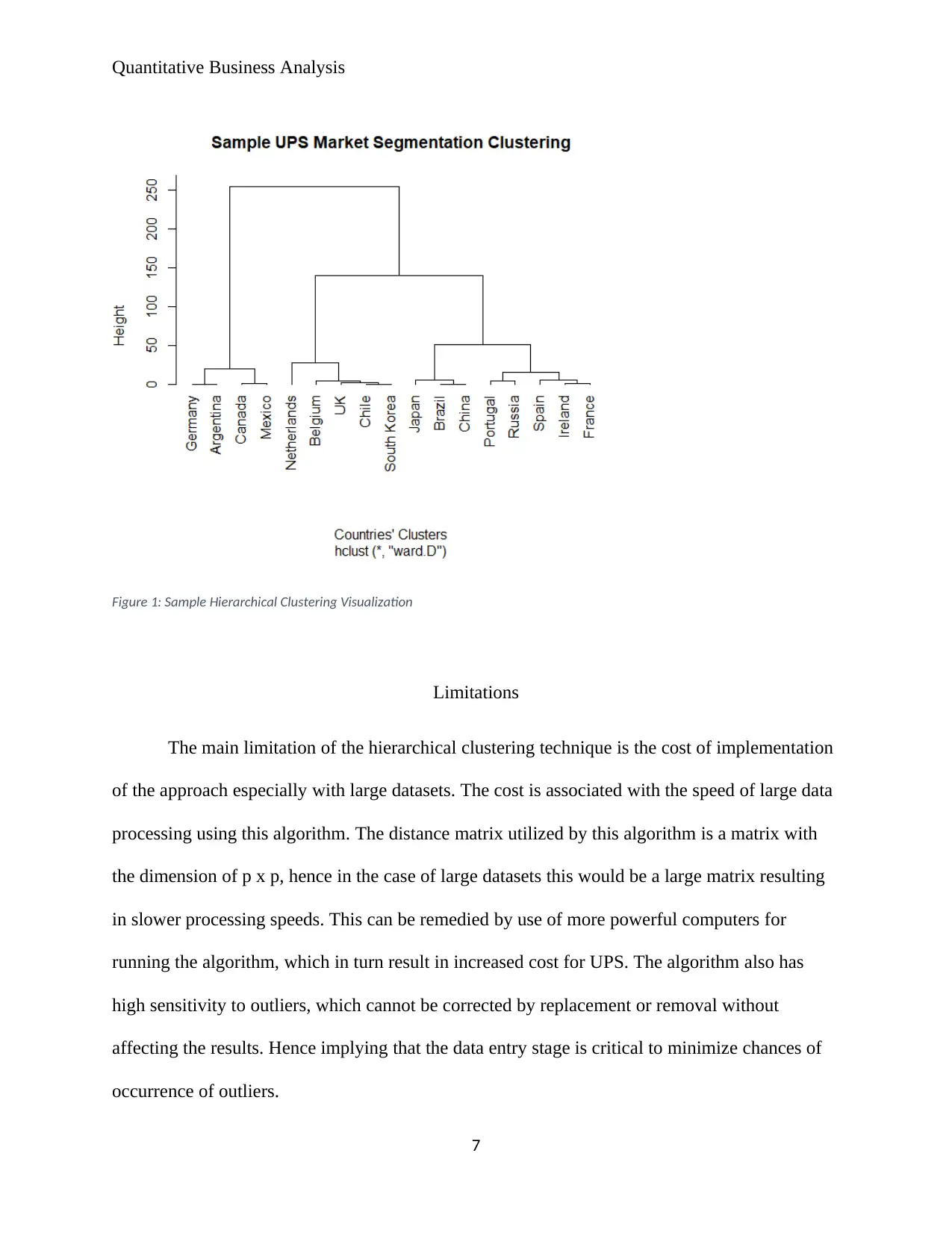
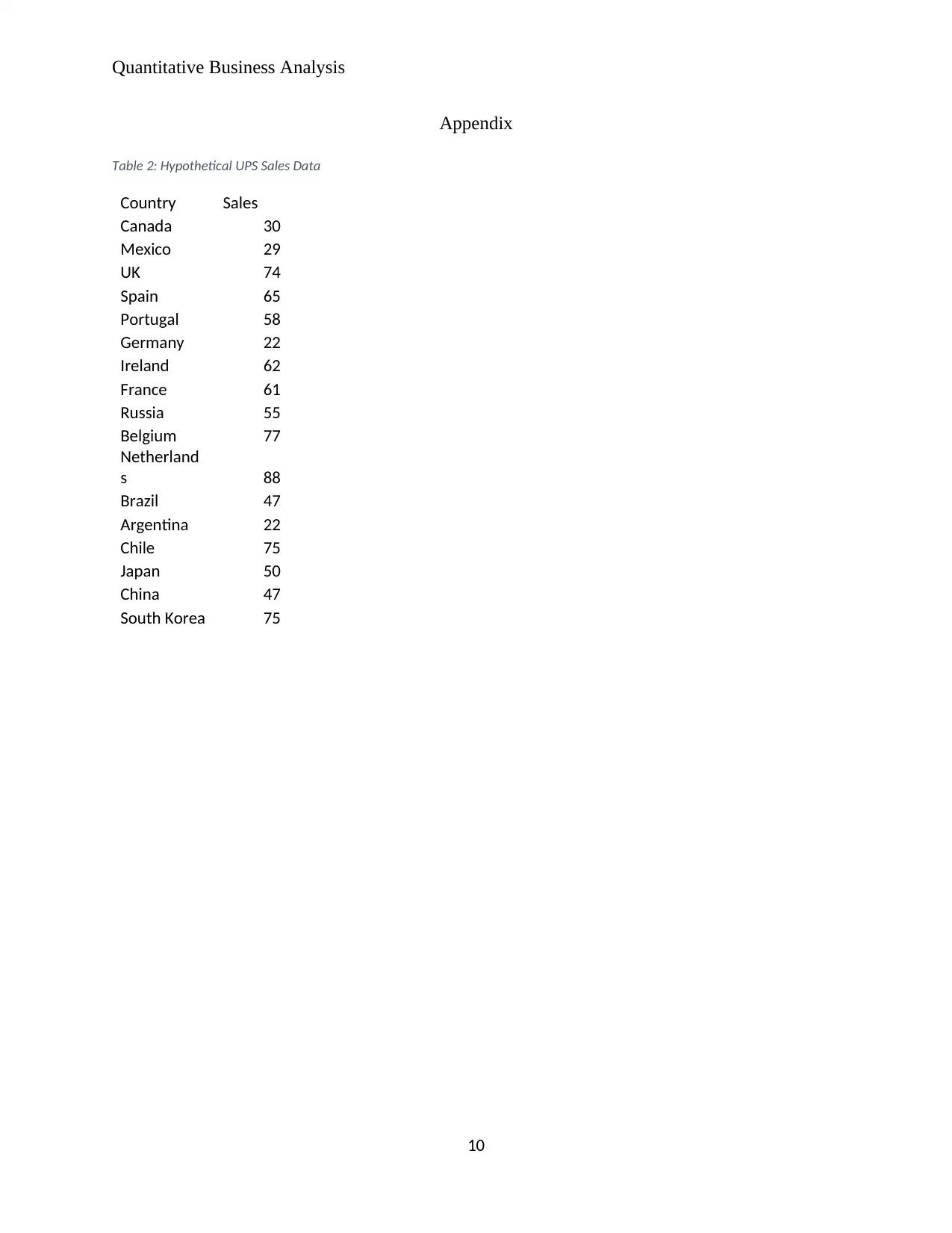
This project provides a comprehensive quantitative business analysis of UPS, a global logistics company, focusing on market segmentation challenges. The analysis highlights the need for effective segmentation due to diverse market dynamics influenced by factors like politics, income, and culture. The project proposes the use of big data analytics, specifically cluster analysis, as a solution. It delves into hierarchical cluster analysis as the most suitable technique for UPS, given the flexibility needed to account for a wide range of services and the ability to minimize information loss. The project includes a sample cluster analysis using hypothetical sales data, demonstrating the R Programming Code and output, along with a visualization of the clusters. The limitations of the hierarchical clustering technique, such as the computational cost and sensitivity to outliers, are also discussed. The project concludes by emphasizing the importance of effective data entry to minimize the chances of outliers. References to relevant academic papers on clustering, market segmentation, and logistics are also provided.








1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.