Customer Churn Analysis for Tesco PLC using Marketing Analytics
VerifiedAdded on 2023/06/04
|16
|3867
|364
Report
AI Summary
This assignment focuses on analyzing a dataset to provide effective results for Tesco PLC, a British multinational store chain. The report explores customer churn prediction using Classification and Regression (C&R) trees in SPSS Modeler and the RFM (Recency, Frequency, Monetary) method in Excel. It aims to develop a model to predict customer churn, evaluating the performance of the models. The report includes an introduction, problem definition, literature review, data set description, methodology, analysis of results, and conclusion. The C&R method is used to predict churn, while the RFM method is used to evaluate customer segmentation and behavior. The report discusses the importance of customer retention and the application of data mining techniques to identify churn patterns and build effective customer retention strategies, ultimately aiming to reduce marketing costs and improve customer support. The analysis involves the application of Binary classification trees and the RFM strategy, with detailed discussions and results. The work builds upon existing research on customer churn and provides recommendations for improving customer retention strategies at Tesco.

Marketing Analytics
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Executive summary
This assignment intends to explore the offered dataset to give the effective results to a
Tesco PLC association. This association is a British multinational all inclusive store chain
and it headquartered in Welwyn Garden city, United Kingdom, England and Hertfordshire.
This general store chain is a third greatest retailer on the world in perspective of advantages
and second greatest retailer on the world in light of wages. It has stores in 12 countries over
the Europe and Asia. It offers the going with things in nine particular classes like Apparel,
Bakery, Deli, Dairy, Fresh Produce, General Merchandise, Grocery, Liquor, and Meat. It
manufactures the advantages by moving in the resolve plot with two levels like Gold and
Silver. The Tesco advance towards the transforming into the UK greatest supermarket chain
and it in a general sense changed the country's market business. It moreover dispatches the
club card point that is cardholders are can accumulate the one club card point for every one
Europe they spend in the Tesco Store and Website. Thusly, we will build up the model to
anticipate the customer upset from provided data set by using the Classification and
Regression (C&R) and moreover evaluate the gathered establish performances. Also, survey
the created show displays by using the RFM strategy. These are will be discussed in detail.
The Binary classification trees (Classification and Regression (C&R)) procedure is done by
using the SPSS modeller programming and RFM strategy is done by using Excel. These are
will be analysed and executed.
1
This assignment intends to explore the offered dataset to give the effective results to a
Tesco PLC association. This association is a British multinational all inclusive store chain
and it headquartered in Welwyn Garden city, United Kingdom, England and Hertfordshire.
This general store chain is a third greatest retailer on the world in perspective of advantages
and second greatest retailer on the world in light of wages. It has stores in 12 countries over
the Europe and Asia. It offers the going with things in nine particular classes like Apparel,
Bakery, Deli, Dairy, Fresh Produce, General Merchandise, Grocery, Liquor, and Meat. It
manufactures the advantages by moving in the resolve plot with two levels like Gold and
Silver. The Tesco advance towards the transforming into the UK greatest supermarket chain
and it in a general sense changed the country's market business. It moreover dispatches the
club card point that is cardholders are can accumulate the one club card point for every one
Europe they spend in the Tesco Store and Website. Thusly, we will build up the model to
anticipate the customer upset from provided data set by using the Classification and
Regression (C&R) and moreover evaluate the gathered establish performances. Also, survey
the created show displays by using the RFM strategy. These are will be discussed in detail.
The Binary classification trees (Classification and Regression (C&R)) procedure is done by
using the SPSS modeller programming and RFM strategy is done by using Excel. These are
will be analysed and executed.
1

Table of Contents
1 Introduction.......................................................................................................................3
2 Problem Definition............................................................................................................3
3 Literature Review.............................................................................................................4
4 Data Set..............................................................................................................................5
5 Methodology......................................................................................................................5
6 Analysis and Results.........................................................................................................7
6.1 Classification and Regression (C&R) – IBM SPSS Modeller...............................8
6.2 RFM Method – Excel..............................................................................................11
6.3 Evaluation................................................................................................................12
7 Conclusion and Recommendations...............................................................................13
References...............................................................................................................................15
2
1 Introduction.......................................................................................................................3
2 Problem Definition............................................................................................................3
3 Literature Review.............................................................................................................4
4 Data Set..............................................................................................................................5
5 Methodology......................................................................................................................5
6 Analysis and Results.........................................................................................................7
6.1 Classification and Regression (C&R) – IBM SPSS Modeller...............................8
6.2 RFM Method – Excel..............................................................................................11
6.3 Evaluation................................................................................................................12
7 Conclusion and Recommendations...............................................................................13
References...............................................................................................................................15
2
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

1 Introduction
This assignment intends to look at the offered dataset to give the ground-breaking results
to a Tesco PLC association. This association is a British multinational store chain and it
headquartered in Welwyn Garden city, United Kingdom, England and Hertfordshire. This
market chain is a third greatest retailer on the planet in light of advantages and second
greatest retailer on the planet in perspective of earnings. It has stores in 12 countries over the
Europe and Asia. It is the essential supply promote pioneer in the Thailand, Hungary, UK and
Malaysia. It offers the going with things in nine particular classes like Apparel, Bakery, Deli,
Dairy, Fresh Produce, General Merchandise, Grocery, Liquor, and Meat. It constructs the
advantages by pushing in the loyalty plot with two levels like Gold and Silver. The Tesco
advance towards the transforming into the UK greatest general store chain and it on an
extremely fundamental level changed the country's market business. It similarly dispatches
the club card point that is cardholders are can accumulate the one club card point for every
one Europe they spend in the Tesco Store and Website. This methodology is used to enables
the association to accumulate the data on purchase direct of customers and utilize it to makes
the altered offers and lead the concentrated on support campaigns. Along these lines, we will
build up the model to foresee the customer beat from gave educational records by using the
Classification and Regression (C&R) and evaluate the fabricated model displays. In like
manner, evaluate the manufactured model presentations by using the RFM method. These are
will be analysed in detail. The Binary order trees (Classification and Regression (C&R))
methodology is done by using the SPSS modeller programming and RFM strategy is done by
using Excel. These are will be penniless down and executed.
2 Problem Definition
The Tesco PLC showcase anchor requires to examine the offered dataset to build up the
model to envision the customer beat from gave enlightening lists by using the twofold
Classification trees and besides survey the constructed display presentations. Moreover,
survey the created display presentations by using the RFM technique. The Binary course of
action trees system is done by using the SPSS modeller programming and RFM strategy is
done by using Excel (Arroyo Resino, 2017). These are will be penniless down and executed.
These examination are must be contribute the customer support and diminishes the displaying
utilization because the present offers are does not diminishes the promoting use.
3
This assignment intends to look at the offered dataset to give the ground-breaking results
to a Tesco PLC association. This association is a British multinational store chain and it
headquartered in Welwyn Garden city, United Kingdom, England and Hertfordshire. This
market chain is a third greatest retailer on the planet in light of advantages and second
greatest retailer on the planet in perspective of earnings. It has stores in 12 countries over the
Europe and Asia. It is the essential supply promote pioneer in the Thailand, Hungary, UK and
Malaysia. It offers the going with things in nine particular classes like Apparel, Bakery, Deli,
Dairy, Fresh Produce, General Merchandise, Grocery, Liquor, and Meat. It constructs the
advantages by pushing in the loyalty plot with two levels like Gold and Silver. The Tesco
advance towards the transforming into the UK greatest general store chain and it on an
extremely fundamental level changed the country's market business. It similarly dispatches
the club card point that is cardholders are can accumulate the one club card point for every
one Europe they spend in the Tesco Store and Website. This methodology is used to enables
the association to accumulate the data on purchase direct of customers and utilize it to makes
the altered offers and lead the concentrated on support campaigns. Along these lines, we will
build up the model to foresee the customer beat from gave educational records by using the
Classification and Regression (C&R) and evaluate the fabricated model displays. In like
manner, evaluate the manufactured model presentations by using the RFM method. These are
will be analysed in detail. The Binary order trees (Classification and Regression (C&R))
methodology is done by using the SPSS modeller programming and RFM strategy is done by
using Excel. These are will be penniless down and executed.
2 Problem Definition
The Tesco PLC showcase anchor requires to examine the offered dataset to build up the
model to envision the customer beat from gave enlightening lists by using the twofold
Classification trees and besides survey the constructed display presentations. Moreover,
survey the created display presentations by using the RFM technique. The Binary course of
action trees system is done by using the SPSS modeller programming and RFM strategy is
done by using Excel (Arroyo Resino, 2017). These are will be penniless down and executed.
These examination are must be contribute the customer support and diminishes the displaying
utilization because the present offers are does not diminishes the promoting use.
3
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

3 Literature Review
This paper speaks to (Dingli, Marmara and Fournier, 2017), Customer are one of the
organization's most basic resources. In context of this, organizations need to give customers'
developing powers with a specific genuine goal to hold and keep building up the business. A
negative composed exertion with a customers may surmise that Customer may blend. An
essential point inside the business is to have a normal perception of customers' needs,
whereby thorough perspectives of their models might be inspected. Transversely over
undertakings, information on customer's financial aspects, basic regard based information and
from time to time customer endurance (Net Promoter Scores) are anchored and might be
utilized for examination. Scientists take a gander at that jobs and edges increment if the
correct Customer are held then again with pulling in new ones. With information mining
systems, information might be dealt with and isolated to perceive precedents and individual
lead measures. Analysts likewise examine that it is ending up more helpful to apply
information mining frameworks rather than self-sufficient quantifiable models to anticipate
results. The explanation for this, is an immediate consequence of the solid expansion in
information. This paper examines the information readiness and examination required to
refresh and improve business procedures to diminish Customer with a high propensity to beat
(Board, 2017). The Customer who have been seen as churners will be passed on to the Sales
and Marketing social event of the near to store. A more critical comprehension as for why
these Customer may make will be passed on. Following this, utilizing the data accomplished
from the Customer, an upkeep crusade will be proposed to base on the possible beating
Customer.
According to this paper (Tamaddoni, Stakhovych and Ewing, 2015), Customer beat
device is one of the issues that most worry to organizations today. Sensible models can be
conveyed for perceiving future churners. As the measure of fitting social occasion strategies
amasses, it has wound up being harder to survey which one is the best for our application and
which parameters to use for its underwriting. To pick the most proper methodology,
interchange perspectives detached from exactness which is the most without a doubt
comprehended parameter can and ought to be considered as: quality, speed, interpretability
and solace. In this paper we propose a hypothesis for reviewing honest models for game-plan
with the utilization of a composite marker. This composite pointer measures
multidimensional contemplations which can't be gotten by a solitary parameter and help
pioneers to manage this astonishing issue. Three decisions are proposed giving specific
4
This paper speaks to (Dingli, Marmara and Fournier, 2017), Customer are one of the
organization's most basic resources. In context of this, organizations need to give customers'
developing powers with a specific genuine goal to hold and keep building up the business. A
negative composed exertion with a customers may surmise that Customer may blend. An
essential point inside the business is to have a normal perception of customers' needs,
whereby thorough perspectives of their models might be inspected. Transversely over
undertakings, information on customer's financial aspects, basic regard based information and
from time to time customer endurance (Net Promoter Scores) are anchored and might be
utilized for examination. Scientists take a gander at that jobs and edges increment if the
correct Customer are held then again with pulling in new ones. With information mining
systems, information might be dealt with and isolated to perceive precedents and individual
lead measures. Analysts likewise examine that it is ending up more helpful to apply
information mining frameworks rather than self-sufficient quantifiable models to anticipate
results. The explanation for this, is an immediate consequence of the solid expansion in
information. This paper examines the information readiness and examination required to
refresh and improve business procedures to diminish Customer with a high propensity to beat
(Board, 2017). The Customer who have been seen as churners will be passed on to the Sales
and Marketing social event of the near to store. A more critical comprehension as for why
these Customer may make will be passed on. Following this, utilizing the data accomplished
from the Customer, an upkeep crusade will be proposed to base on the possible beating
Customer.
According to this paper (Tamaddoni, Stakhovych and Ewing, 2015), Customer beat
device is one of the issues that most worry to organizations today. Sensible models can be
conveyed for perceiving future churners. As the measure of fitting social occasion strategies
amasses, it has wound up being harder to survey which one is the best for our application and
which parameters to use for its underwriting. To pick the most proper methodology,
interchange perspectives detached from exactness which is the most without a doubt
comprehended parameter can and ought to be considered as: quality, speed, interpretability
and solace. In this paper we propose a hypothesis for reviewing honest models for game-plan
with the utilization of a composite marker. This composite pointer measures
multidimensional contemplations which can't be gotten by a solitary parameter and help
pioneers to manage this astonishing issue. Three decisions are proposed giving specific
4
weights to the included parameters considering the last customer's needs. Our structure
discovers which the best classifier is by boosting the estimation of the composite marker. We
test our proposal on an approach of five beat mastermind models drawn from a main
problem, three of them being built up on specific classifiers and the other two being worked
by utilizing combined classifiers. Another additional respect offered by this work is to
consider the information factors decision effect on the execution of the mix want show up.
We will think about four uncommon decisions: noteworthy factors, indicate factors (together
with remarkable ones), Principal part examination (PCA) and stacking technique (Chapman,
2017). Numerical outcomes utilizing genuine information from a Spanish retailing
organization are appeared and assessed recollecting a definitive goal to display the execution
and validness of our recommendation.
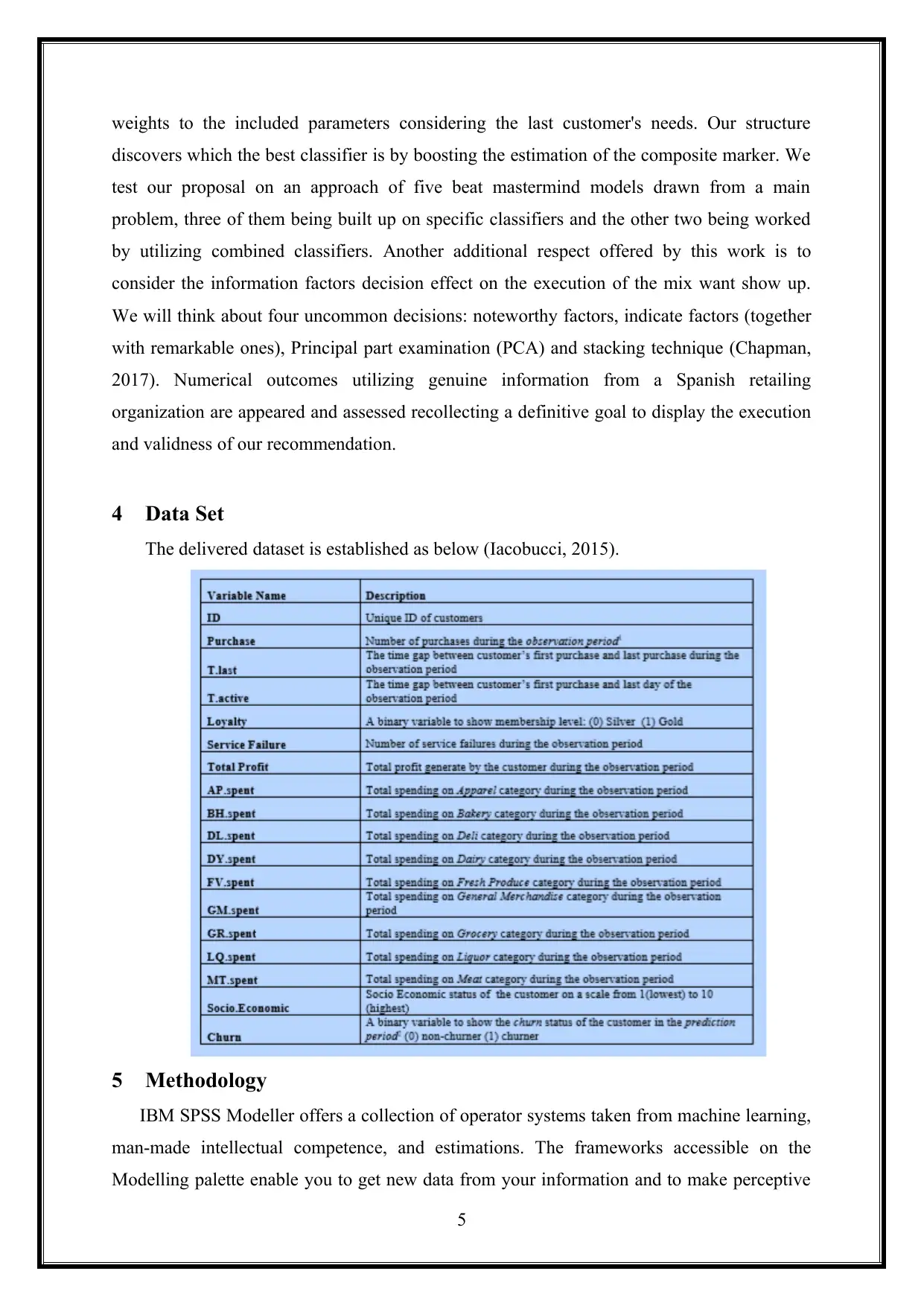
4 Data Set
The delivered dataset is established as below (Iacobucci, 2015).
5 Methodology
IBM SPSS Modeller offers a collection of operator systems taken from machine learning,
man-made intellectual competence, and estimations. The frameworks accessible on the
Modelling palette enable you to get new data from your information and to make perceptive
5
discovers which the best classifier is by boosting the estimation of the composite marker. We
test our proposal on an approach of five beat mastermind models drawn from a main
problem, three of them being built up on specific classifiers and the other two being worked
by utilizing combined classifiers. Another additional respect offered by this work is to
consider the information factors decision effect on the execution of the mix want show up.
We will think about four uncommon decisions: noteworthy factors, indicate factors (together
with remarkable ones), Principal part examination (PCA) and stacking technique (Chapman,
2017). Numerical outcomes utilizing genuine information from a Spanish retailing
organization are appeared and assessed recollecting a definitive goal to display the execution
and validness of our recommendation.
4 Data Set
The delivered dataset is established as below (Iacobucci, 2015).
5 Methodology
IBM SPSS Modeller offers a collection of operator systems taken from machine learning,
man-made intellectual competence, and estimations. The frameworks accessible on the
Modelling palette enable you to get new data from your information and to make perceptive
5
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

models ("Discovering Statistics Using IBM SPSS Statistics. And Sex and Drugs and
Rock'n'Roll", 2014). Every framework has certain attributes and is most legitimate for
specific sorts of issues. Indicating procedures are detached into three classes:
• Classification
• Association
• Segmentation
Classification Models
Classification models utilize the estimations of something close to one information fields
to predict the estimation of no short of what one yield, or target, fields. A few cases of these
structures are: decision trees (C&R Tree, QUEST, CHAID and C5.0 calculations), backslide,
neural systems, support vector machines, and Bayesian systems. Classification models
influences Association s to anticipate an insinuated result, for example, paying little
personality to whether a customers will purchase or leave or whether an exchange fits a
known instance of trickery. Showing frameworks combine machine learning, control
affirmation, subgroup ID, honest methodology, and diverse model age.
Association Models
Association models discover designs in your information where something like one parts
are associated with no short of what one unmistakable segments. The models make pick sets
that portray these associations. Here the fields inside the information can go about as the two
data sources and targets. You could discover these Associations physically, in any case
Association oversee estimations do in that limit out and out more rapidly, and can inquire
about more wonderful diagrams. Apriori and Carma models are examples of the utilization of
such checks. One other sort of Association exhibit is a movement recognizing evidence
feature, which finds consecutive points of reference in time-created information. Association
models are most gainful while imagining different result for instance, Customer who got
thing X in like way procured Y and Z. Association models relate a specific end, (for example,
the decision to purchase something) with an Classification of conditions. The benefit of
Association lead tallies over the more standard decision tree figuring's (C5.0 and C&RT) is
that Associations can exist between any of the characteristics. A decision tree tally will
produce rules with just a solitary end, while Association figuring's endeavour to discover
different basics, every last one of which may have a substitute end (Popović, 2015).
Segmentation Models
6
Rock'n'Roll", 2014). Every framework has certain attributes and is most legitimate for
specific sorts of issues. Indicating procedures are detached into three classes:
• Classification
• Association
• Segmentation
Classification Models
Classification models utilize the estimations of something close to one information fields
to predict the estimation of no short of what one yield, or target, fields. A few cases of these
structures are: decision trees (C&R Tree, QUEST, CHAID and C5.0 calculations), backslide,
neural systems, support vector machines, and Bayesian systems. Classification models
influences Association s to anticipate an insinuated result, for example, paying little
personality to whether a customers will purchase or leave or whether an exchange fits a
known instance of trickery. Showing frameworks combine machine learning, control
affirmation, subgroup ID, honest methodology, and diverse model age.
Association Models
Association models discover designs in your information where something like one parts
are associated with no short of what one unmistakable segments. The models make pick sets
that portray these associations. Here the fields inside the information can go about as the two
data sources and targets. You could discover these Associations physically, in any case
Association oversee estimations do in that limit out and out more rapidly, and can inquire
about more wonderful diagrams. Apriori and Carma models are examples of the utilization of
such checks. One other sort of Association exhibit is a movement recognizing evidence
feature, which finds consecutive points of reference in time-created information. Association
models are most gainful while imagining different result for instance, Customer who got
thing X in like way procured Y and Z. Association models relate a specific end, (for example,
the decision to purchase something) with an Classification of conditions. The benefit of
Association lead tallies over the more standard decision tree figuring's (C5.0 and C&RT) is
that Associations can exist between any of the characteristics. A decision tree tally will
produce rules with just a solitary end, while Association figuring's endeavour to discover
different basics, every last one of which may have a substitute end (Popović, 2015).
Segmentation Models
6
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Segmentation models isolate the information into sections, or groups, of records that have
relative points of reference of data fields. As they are just excited about the information
fields, Segmentation models have no understanding of yield or target fields. Cases of
Segmentation models are Kohonen structures, K-Means gathering, two-advance clustering
and abnormality territory. Segmentation models are helpful in conditions where the particular
outcome is dull. Bundling models is revolve around perceiving social events of for all intents
and purposes indistinguishable records and naming the records as demostrated by the party to
which they have a place. This is supervised without the upside of earlier getting some
answers concerning the get-togethers and their attributes, and it sees Classification models
from the other demonstrating frameworks in that there is no predefined yield or target field
for the model to envision.
Here, we are using the Classification and Regression (C&R) and RPM strategy.
Classification and Regression (C&R)
The Classification and Regression (C&R) Tree focus point conveys a decision tree that
engages you to envision or depict future perceptions. The framework utilizes recursive
allotting to part the course of action records into territories by limiting the contamination at
each development, where an inside point in the tree is viewed as "unadulterated" if 100% of
cases in the middle fall into a particular class of the objective field. Target and information
fields can be numeric extents or incomparable and all parts are twofold.
RPM Method
RFM (Recency, Frequency, and Monetary) investigation is a demostrated showing model
for toxic customers Segmentation. It groups Customer in context of their exchange history –
how beginning late, how regularly and what aggregate did they purchase. RFM isolates
Customer into different Classifications or groups to see Customer who will probably react to
movements furthermore for future personalization associations ("IBM Knowledge Center",
2018). RFM remains for,
• Recency – How beginning late the customers procured
• Frequency – How frequently the customers buys
• Monetary (or every so often Margin) – How much they spend
Every single one of these measures is a key pointer of how marvellous a customers they
are, yet together you get an unprecedented scoring metric that can reveal to you an
unbelievable strategy about where (or who) your leverage is started.
7
relative points of reference of data fields. As they are just excited about the information
fields, Segmentation models have no understanding of yield or target fields. Cases of
Segmentation models are Kohonen structures, K-Means gathering, two-advance clustering
and abnormality territory. Segmentation models are helpful in conditions where the particular
outcome is dull. Bundling models is revolve around perceiving social events of for all intents
and purposes indistinguishable records and naming the records as demostrated by the party to
which they have a place. This is supervised without the upside of earlier getting some
answers concerning the get-togethers and their attributes, and it sees Classification models
from the other demonstrating frameworks in that there is no predefined yield or target field
for the model to envision.
Here, we are using the Classification and Regression (C&R) and RPM strategy.
Classification and Regression (C&R)
The Classification and Regression (C&R) Tree focus point conveys a decision tree that
engages you to envision or depict future perceptions. The framework utilizes recursive
allotting to part the course of action records into territories by limiting the contamination at
each development, where an inside point in the tree is viewed as "unadulterated" if 100% of
cases in the middle fall into a particular class of the objective field. Target and information
fields can be numeric extents or incomparable and all parts are twofold.
RPM Method
RFM (Recency, Frequency, and Monetary) investigation is a demostrated showing model
for toxic customers Segmentation. It groups Customer in context of their exchange history –
how beginning late, how regularly and what aggregate did they purchase. RFM isolates
Customer into different Classifications or groups to see Customer who will probably react to
movements furthermore for future personalization associations ("IBM Knowledge Center",
2018). RFM remains for,
• Recency – How beginning late the customers procured
• Frequency – How frequently the customers buys
• Monetary (or every so often Margin) – How much they spend
Every single one of these measures is a key pointer of how marvellous a customers they
are, yet together you get an unprecedented scoring metric that can reveal to you an
unbelievable strategy about where (or who) your leverage is started.
7
6 Analysis and Results
Here, we will formulate the model to predict the customer beat from provided
informative records by using the binary Classification trees (Classification and Regression
(C&R)) and survey the created display shows. Moreover, survey the assembled demonstrate
displays by using the RFM system. The Binary Classification trees system is done by using
the SPSS modeller programming and RFM methodology is done by using Excel (Starkings,
2012).
6.1 Classification and Regression (C&R) – IBM SPSS Modeller
To do the Classification and Regression (C&R) on IBM SPSS Modeller by follows the below
steps (Brownlee, 2018).
Open the IBM SPSS Modeller.
Load given data set and it is demonstrated as under.
Then, click the modelling to choose C&R. Finally, choose the attributes. It is displayed in
below.
8
Here, we will formulate the model to predict the customer beat from provided
informative records by using the binary Classification trees (Classification and Regression
(C&R)) and survey the created display shows. Moreover, survey the assembled demonstrate
displays by using the RFM system. The Binary Classification trees system is done by using
the SPSS modeller programming and RFM methodology is done by using Excel (Starkings,
2012).
6.1 Classification and Regression (C&R) – IBM SPSS Modeller
To do the Classification and Regression (C&R) on IBM SPSS Modeller by follows the below
steps (Brownlee, 2018).
Open the IBM SPSS Modeller.
Load given data set and it is demonstrated as under.
Then, click the modelling to choose C&R. Finally, choose the attributes. It is displayed in
below.
8
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
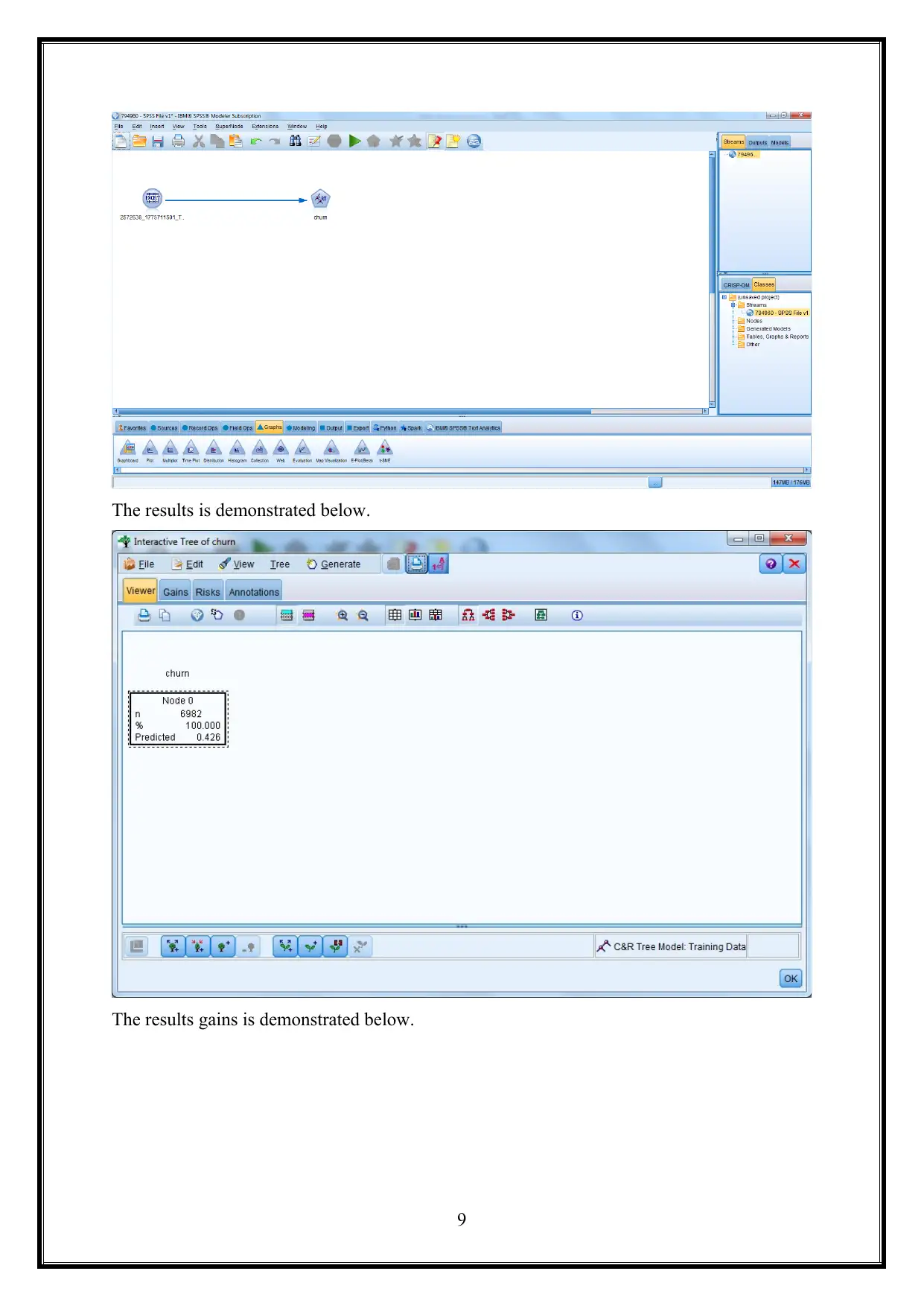
The results is demonstrated below.
The results gains is demonstrated below.
9
The results gains is demonstrated below.
9
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
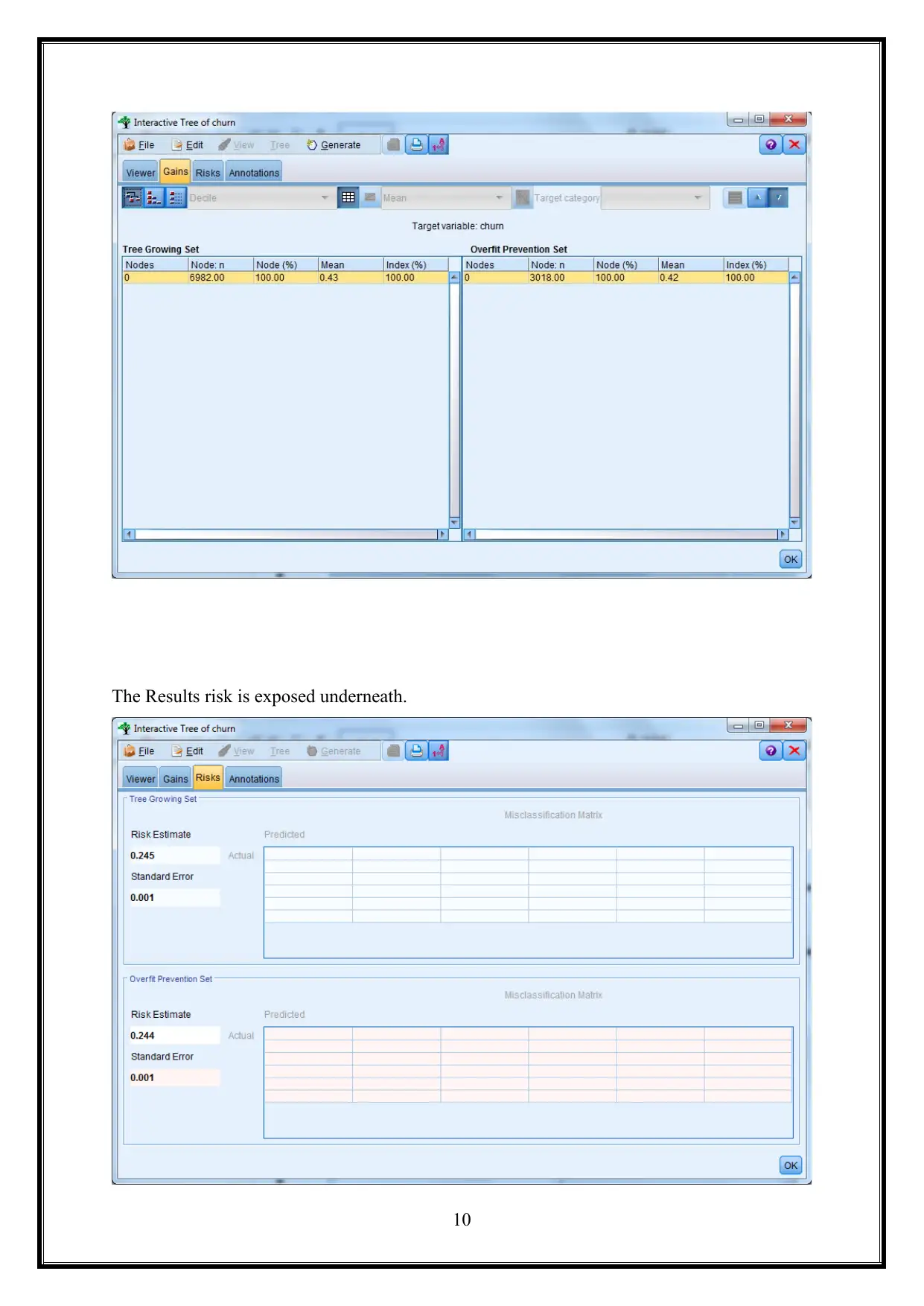
The Results risk is exposed underneath.
10
10

The Grow tree for results is demonstrated below.
C&R tree method is figured on the dataset to amass an appreciation of the available
data. With the true objective of this investigation, Churn is described as a customer who stops
executing with the store. Customers who reduce in arrangements will be named non-churners.
Customers who leave the supermarket in the going with time span are requested as churners.
Keeping in mind the end goal to recognize churners, the dataset is isolated into two time
assignments or time windows. The essential window is the judicious window which
recognizes dynamic customers (Xiao, Xu & Xu, 2015). Development is portrayed by the
customers including trades inside this period. Customers which incorporate development
inside the central window are marked as non-churners, while whatever is left of the
customers are separate as churners. The last are abstained from the examination as they have
recently beaten. The accompanying window, the beat assessment window mastermind
whatever is left of the customers are churner or non-churner. If customers execute in this
period they are non-churners, while if no trades are seen then they are churners.
6.2 RFM Method – Excel
For Test Data,
11
C&R tree method is figured on the dataset to amass an appreciation of the available
data. With the true objective of this investigation, Churn is described as a customer who stops
executing with the store. Customers who reduce in arrangements will be named non-churners.
Customers who leave the supermarket in the going with time span are requested as churners.
Keeping in mind the end goal to recognize churners, the dataset is isolated into two time
assignments or time windows. The essential window is the judicious window which
recognizes dynamic customers (Xiao, Xu & Xu, 2015). Development is portrayed by the
customers including trades inside this period. Customers which incorporate development
inside the central window are marked as non-churners, while whatever is left of the
customers are separate as churners. The last are abstained from the examination as they have
recently beaten. The accompanying window, the beat assessment window mastermind
whatever is left of the customers are churner or non-churner. If customers execute in this
period they are non-churners, while if no trades are seen then they are churners.
6.2 RFM Method – Excel
For Test Data,
11
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 16


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.