MKF5912 - Marketing Research Data Analysis: SPSS Output Analysis
VerifiedAdded on 2022/11/30
|5
|724
|198
Homework Assignment
AI Summary
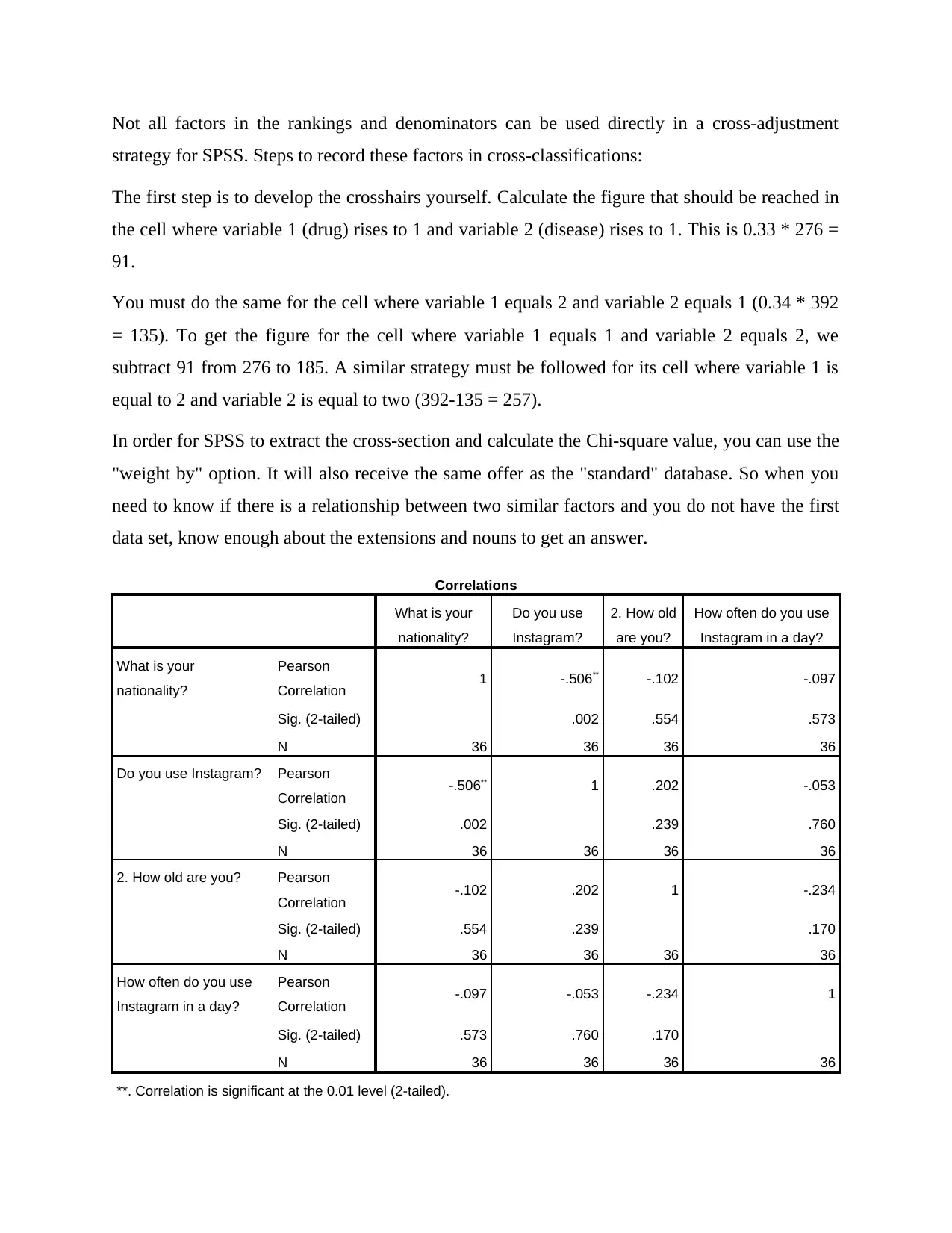
This assignment presents an analysis of marketing research data, focusing on hypothesis testing, cross-tabulation, and the interpretation of SPSS output. Part A examines the analysis of output, including p-values and levels of significance, with examples of cross-tabulation and its utility in identifying relationships between variables. Part B delves into the variables used in cross-tabulation, including how to handle variables that cannot be directly used in cross-tabulation strategies, and how to perform the necessary calculations to incorporate these variables. The document also includes an analysis of correlations, including Pearson correlation, and provides a sample cross-tabulation question to illustrate the process of hypothesis testing, as well as the Chi-Square test to determine the association between age and brand preference. The assignment provides detailed steps to formulate hypotheses and interpret the results of the statistical tests.




1 out of 5
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.