Math 453/553/653: Coursework 3 - Exponential Distribution and Bayes
VerifiedAdded on 2022/08/30
|8
|745
|17
Homework Assignment
AI Summary
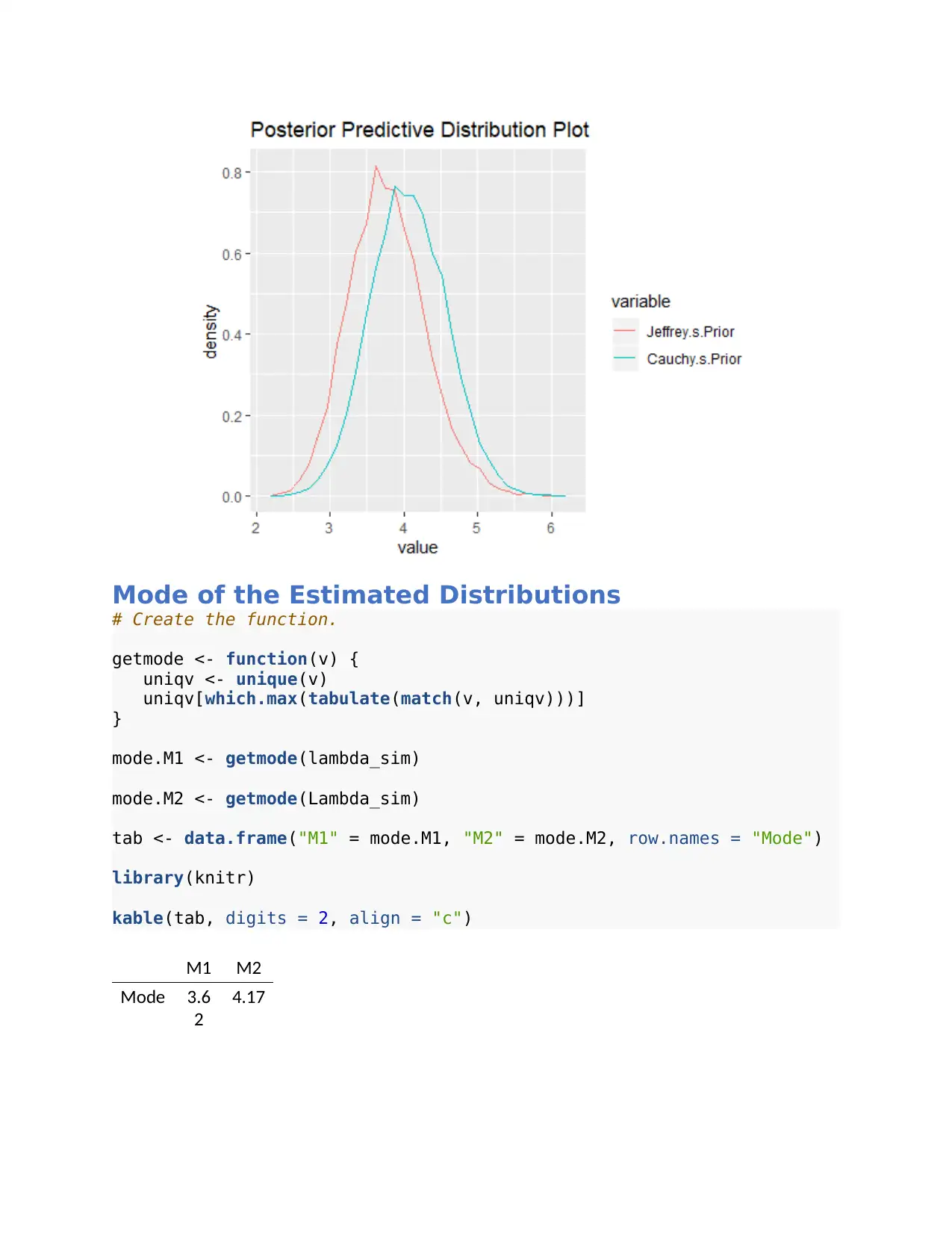
This document presents the complete solution to Math 453 Coursework 3, which involves analyzing customer waiting times for a food delivery service. The assignment focuses on modeling the waiting times using an exponential distribution and calculating the Jeffrey's prior. The solution demonstrates the calculation of the Bayes factor for different priors, including the use of a Cauchy prior, and provides R code to estimate posterior distributions using the grid approximation method. The analysis includes posterior predictive distribution plots and mode estimation for the estimated distributions. The second question uses Laplace's method to estimate the posterior.







1 out of 8
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.