MIS772 Predictive Analytics (2019 T1) A1-LP2: Classification Report
VerifiedAdded on 2023/01/10
|8
|2069
|100
Report
AI Summary
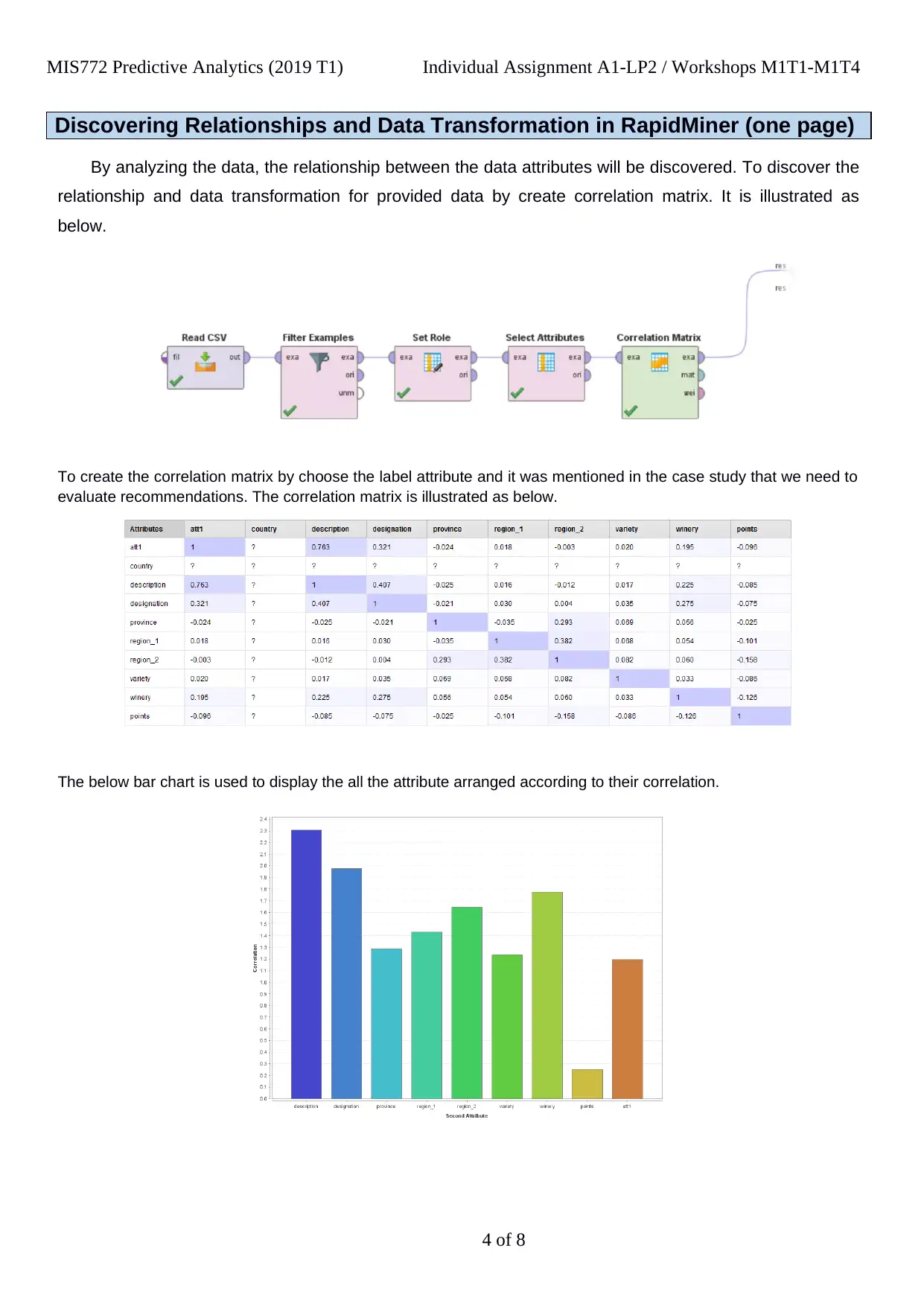
This report details the analysis of a predictive analytics assignment (MIS772) focused on classifying wine data using RapidMiner. The student begins with an executive summary, outlining the project's objectives, which include exploring wine data to derive insights for Australian Wine Importers (AWI). The project involves data preparation, including handling missing values and attribute selection. The core of the report involves discovering relationships within the data through correlation matrices, and creating predictive models using Decision Tree and Random Tree algorithms within RapidMiner. The models are then evaluated using performance operators (Accuracy and Kappa), and further refined through cross-validation to estimate statistical performance. The student also discusses the deployment of the models. The report concludes with a discussion of further research and extensions, highlighting the potential of the created models to predict wine price ranges based on winery attributes and taste results. The student also mentions the lack of independent research to confirm the predictions and the overall effectiveness of the models.






1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.