Intelligent Systems Implementation: Phishing URL Detection Report
VerifiedAdded on 2021/04/29
|16
|3047
|156
Report
AI Summary
This report details a machine learning-based system for detecting phishing URLs. The project utilizes a supervised learning model that analyzes lexical features of URLs, such as the number of dots, delimiters, and the presence of IP addresses. The study employs a dataset from Aalto University, comprising legitimate and malicious URLs, and implements three classifiers: Decision Tree, Adaboost, and KNN. The Decision Tree classifier demonstrated the best performance, and transfer learning was applied to further improve accuracy. The report outlines the approach, implementation, performance evaluation, and future work, providing a comprehensive analysis of the phishing URL detection system. The report also highlights the importance of such systems in the context of increasing phishing attacks during the COVID-19 pandemic and references related works that explore similar techniques.

CSG2341 – Intelligent Systems
Implementation Report:
Phishing URL Detection Machine Learning And Lexical
Features Extraction
Table of Contents
Abstract.......................................................................................................................................................3
Introduction.................................................................................................................................................3
Related Works.........................................................................................................................................4
Approach and Implementation....................................................................................................................5
Pre-processed Dataset..............................................................................................................................5
Implementation Report:
Phishing URL Detection Machine Learning And Lexical
Features Extraction
Table of Contents
Abstract.......................................................................................................................................................3
Introduction.................................................................................................................................................3
Related Works.........................................................................................................................................4
Approach and Implementation....................................................................................................................5
Pre-processed Dataset..............................................................................................................................5
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Features extraction...................................................................................................................................6
Applying classifiers.................................................................................................................................7
Finalizing the classifier............................................................................................................................7
Applying transfer learning...........................................................................................................................7
Providing Input........................................................................................................................................8
Performance Evaluation..............................................................................................................................8
Specifications............................................................................................................................................10
Future Work..............................................................................................................................................10
Contribution..............................................................................................................................................10
Conclusion.................................................................................................................................................11
References.................................................................................................................................................12
Appendix...................................................................................................................................................13
Abstract
Phishing website, as known as spoofed site, is a web sites that attempt to impersonate the
original web site or disguised as a legitimate web site to cheat the user for their personal
information, password, credit card credentials or other financial purpose. The users without
cybersecurity awareness can be deceived easily by the phishing web sites that are created but
malicious actors. In order to distinguish between legitimate and malicious web site, machine
learning technique has been used to detect phishing web site by analysing the web site’s URL.
Applying classifiers.................................................................................................................................7
Finalizing the classifier............................................................................................................................7
Applying transfer learning...........................................................................................................................7
Providing Input........................................................................................................................................8
Performance Evaluation..............................................................................................................................8
Specifications............................................................................................................................................10
Future Work..............................................................................................................................................10
Contribution..............................................................................................................................................10
Conclusion.................................................................................................................................................11
References.................................................................................................................................................12
Appendix...................................................................................................................................................13
Abstract
Phishing website, as known as spoofed site, is a web sites that attempt to impersonate the
original web site or disguised as a legitimate web site to cheat the user for their personal
information, password, credit card credentials or other financial purpose. The users without
cybersecurity awareness can be deceived easily by the phishing web sites that are created but
malicious actors. In order to distinguish between legitimate and malicious web site, machine
learning technique has been used to detect phishing web site by analysing the web site’s URL.

A machine-learning based phishing web site detection system has been proposed in this
report to determine whether an URL is legitimate or malicious. It is a supervised learning model
that using lexical based approach which the model will analyse the features in the URL such as
number of dots, number of delimiters, IP addresses and so forth. The dataset for training and
testing models is taken from Aalto University which contains of total 96,018 URLs, half of them
are legitimate and the rest are malicious. However, due to computational limitation (RAM
capacity) and available resources, only 6251 of legitimate and malicious URLs have been used
respectively.
Moreover, three algorithms have been used to which are Decision Tree, Adaboost, and
KNN are used as the classifier. Overall, the Decision Tree classifier get the best result compares
to another two classifiers with a slightly low accuracy and perform a transfer learning with the
same dataset that contains another 6500 legitimate and malicious URLs to get a better result of
from an accuracy of 81% to 83.7%.
Introduction
Amid COVID-19 pandemic, phishing attacks have been increased twice compared to
2019 in Singapore BAHARUDIN, H. (2020). The malicious actors create a phishing website that
impersonate Singapore Government official website and send the URL via email and SMS to the
target and claimed that the government is providing financial support that require users to enter
their bank account and login credentials in order to get the financial support Singapore Govt.
(2020). In addition, the US Federal Trade Commission also show that 18 million USD have been
scammed over the 12,000 fraud cases that is related to COVID-19 Singcert. (2020). Therefore,
there is a need to create a system to deal with phishing URLs in order to protect the online users.
Phishing attacks via a phishing web site is not a new technique. There are several ways to
prevent or detect phishing web site, one of the most common method nowadays is machine
learning technique due to its scalability and adaptability Oumaima El Kouari, Hafssa Benaboud,
and Saiida Lazaar. (2020). Within these few years, there are a lot of algorithms have been
proposed for phishing URLs detection with the lexical features.
Related Works
In paper published by Surya Srikar Sirigineedi, Jayesh Soni, and Himanshu Upadhyay. (2020),
authors proposed a learning-based model to detect phishing activities via the URLs. They
categorized the features of phishing web site into three categories, which are
i) Lexical features, ii) NLP features and iii) Host-based features. The lexical feature is the most
common method to detect phishing website. For example, the malicious actors attempt to remain
unsuspected to the users by using a long domain name, or other special characters that used to
report to determine whether an URL is legitimate or malicious. It is a supervised learning model
that using lexical based approach which the model will analyse the features in the URL such as
number of dots, number of delimiters, IP addresses and so forth. The dataset for training and
testing models is taken from Aalto University which contains of total 96,018 URLs, half of them
are legitimate and the rest are malicious. However, due to computational limitation (RAM
capacity) and available resources, only 6251 of legitimate and malicious URLs have been used
respectively.
Moreover, three algorithms have been used to which are Decision Tree, Adaboost, and
KNN are used as the classifier. Overall, the Decision Tree classifier get the best result compares
to another two classifiers with a slightly low accuracy and perform a transfer learning with the
same dataset that contains another 6500 legitimate and malicious URLs to get a better result of
from an accuracy of 81% to 83.7%.
Introduction
Amid COVID-19 pandemic, phishing attacks have been increased twice compared to
2019 in Singapore BAHARUDIN, H. (2020). The malicious actors create a phishing website that
impersonate Singapore Government official website and send the URL via email and SMS to the
target and claimed that the government is providing financial support that require users to enter
their bank account and login credentials in order to get the financial support Singapore Govt.
(2020). In addition, the US Federal Trade Commission also show that 18 million USD have been
scammed over the 12,000 fraud cases that is related to COVID-19 Singcert. (2020). Therefore,
there is a need to create a system to deal with phishing URLs in order to protect the online users.
Phishing attacks via a phishing web site is not a new technique. There are several ways to
prevent or detect phishing web site, one of the most common method nowadays is machine
learning technique due to its scalability and adaptability Oumaima El Kouari, Hafssa Benaboud,
and Saiida Lazaar. (2020). Within these few years, there are a lot of algorithms have been
proposed for phishing URLs detection with the lexical features.
Related Works
In paper published by Surya Srikar Sirigineedi, Jayesh Soni, and Himanshu Upadhyay. (2020),
authors proposed a learning-based model to detect phishing activities via the URLs. They
categorized the features of phishing web site into three categories, which are
i) Lexical features, ii) NLP features and iii) Host-based features. The lexical feature is the most
common method to detect phishing website. For example, the malicious actors attempt to remain
unsuspected to the users by using a long domain name, or other special characters that used to
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

appear in phishing web site such as ‘?’, ‘//’, ‘.’ and so forth. The NLP feature is used to look for
random words, keywords, and brand names of the phishing web sites. The host-based feature is
to look for its domain properties via WHOIS service for the creation date, expiration date and
registrar name. Since phishing URLs only stay for a short time, and normally contains IP
addresses in their host name. These three categories of features have been used to detect phishing
websites. Moreover, they used wide range of machine learning algorithms such as KNN (K-
Nearest Neighbour), LR (Logistic Regression), SVM (Support Vector Machine), GBC (Gradient
Boosting Classifier), ABC (Ada Boost Classifier), and RFC (Random Forest Classifier) to train
the model with the dataset that contains 36,400 legitimate and 37,175 phishing URLs. Overall,
the ABC get the best result of 94% accuracy in 22,073 URLs testing set. Therefore, Ada Boost
Classifier has been chosen as one of the classifiers for this paper.
In papers released by L. Machado and J. Gadge (2017) and Vijaya, M.S.. (2012) both authors
proposed a machine learning model based on lexical features with DT (Decision Tree) classifier.
The main differences between L. Machado and J. Gadge (2017) and Vijaya, M.S.. (2012) are
dataset used and the number of features. For L. Machado and J. Gadge (2017), their training
dataset contains of 1500 legitimate and 1500 phishing URLs with 9 features, and testing dataset
of another 3000 URLs. The result they achieve is 89.4% accuracy. For Vijaya, M.S.. (2012),
their training dataset and testing dataset are relatively smaller than any others, only contains 100
legitimate and 100 phishing URLs with 17 features. The result they achieve is 98.5% accuracy.
Therefore, a less amount of dataset with more features get a very good result, and a less features
with a large amount of dataset get a decent result.
In Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir, Banu Diri, (2017), several
methodologies have been proposed by the author, such as KNN, ABC and DT. In tern of lexical
features, the result show that KNN get the best results of 83.01% accuracy compared to ABC of
74.74% accuracy and DT of 82.48% accuracy. However, these results are not the same as Surya
Srikar Sirigineedi, Jayesh Soni, and Himanshu Upadhyay. (2020), both of them were using the
same dataset that contain the same amount of legitimate and malicious URLs and same
methodologies. Therefore, there is a need to experiment KNN, ABC, and DT classifier with our
dataset.
In addition, Surya Srikar Sirigineedi, Jayesh Soni, and Himanshu Upadhyay. (2020)
shown that DT get the best result of 97.29% accuracy and ABC get a slightly lower result of
95.93% accuracy with the same dataset that contains only 1116 legitimate and 1428 malicious
URLs.
Lastly, we proposed a machine learning based model with lexical features to detect
phishing URLs since the five papers get an excellent result of 74.74% to 98.5% accuracy with
several different algorithms. The algorithms we proposed are KNN, ABC and DT since these
three algorithms get the best results in Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir,
Banu Diri, (2017). Therefore, the purpose of this paper is to find out which algorithm is the best
for detecting phishing URLs.
random words, keywords, and brand names of the phishing web sites. The host-based feature is
to look for its domain properties via WHOIS service for the creation date, expiration date and
registrar name. Since phishing URLs only stay for a short time, and normally contains IP
addresses in their host name. These three categories of features have been used to detect phishing
websites. Moreover, they used wide range of machine learning algorithms such as KNN (K-
Nearest Neighbour), LR (Logistic Regression), SVM (Support Vector Machine), GBC (Gradient
Boosting Classifier), ABC (Ada Boost Classifier), and RFC (Random Forest Classifier) to train
the model with the dataset that contains 36,400 legitimate and 37,175 phishing URLs. Overall,
the ABC get the best result of 94% accuracy in 22,073 URLs testing set. Therefore, Ada Boost
Classifier has been chosen as one of the classifiers for this paper.
In papers released by L. Machado and J. Gadge (2017) and Vijaya, M.S.. (2012) both authors
proposed a machine learning model based on lexical features with DT (Decision Tree) classifier.
The main differences between L. Machado and J. Gadge (2017) and Vijaya, M.S.. (2012) are
dataset used and the number of features. For L. Machado and J. Gadge (2017), their training
dataset contains of 1500 legitimate and 1500 phishing URLs with 9 features, and testing dataset
of another 3000 URLs. The result they achieve is 89.4% accuracy. For Vijaya, M.S.. (2012),
their training dataset and testing dataset are relatively smaller than any others, only contains 100
legitimate and 100 phishing URLs with 17 features. The result they achieve is 98.5% accuracy.
Therefore, a less amount of dataset with more features get a very good result, and a less features
with a large amount of dataset get a decent result.
In Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir, Banu Diri, (2017), several
methodologies have been proposed by the author, such as KNN, ABC and DT. In tern of lexical
features, the result show that KNN get the best results of 83.01% accuracy compared to ABC of
74.74% accuracy and DT of 82.48% accuracy. However, these results are not the same as Surya
Srikar Sirigineedi, Jayesh Soni, and Himanshu Upadhyay. (2020), both of them were using the
same dataset that contain the same amount of legitimate and malicious URLs and same
methodologies. Therefore, there is a need to experiment KNN, ABC, and DT classifier with our
dataset.
In addition, Surya Srikar Sirigineedi, Jayesh Soni, and Himanshu Upadhyay. (2020)
shown that DT get the best result of 97.29% accuracy and ABC get a slightly lower result of
95.93% accuracy with the same dataset that contains only 1116 legitimate and 1428 malicious
URLs.
Lastly, we proposed a machine learning based model with lexical features to detect
phishing URLs since the five papers get an excellent result of 74.74% to 98.5% accuracy with
several different algorithms. The algorithms we proposed are KNN, ABC and DT since these
three algorithms get the best results in Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir,
Banu Diri, (2017). Therefore, the purpose of this paper is to find out which algorithm is the best
for detecting phishing URLs.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
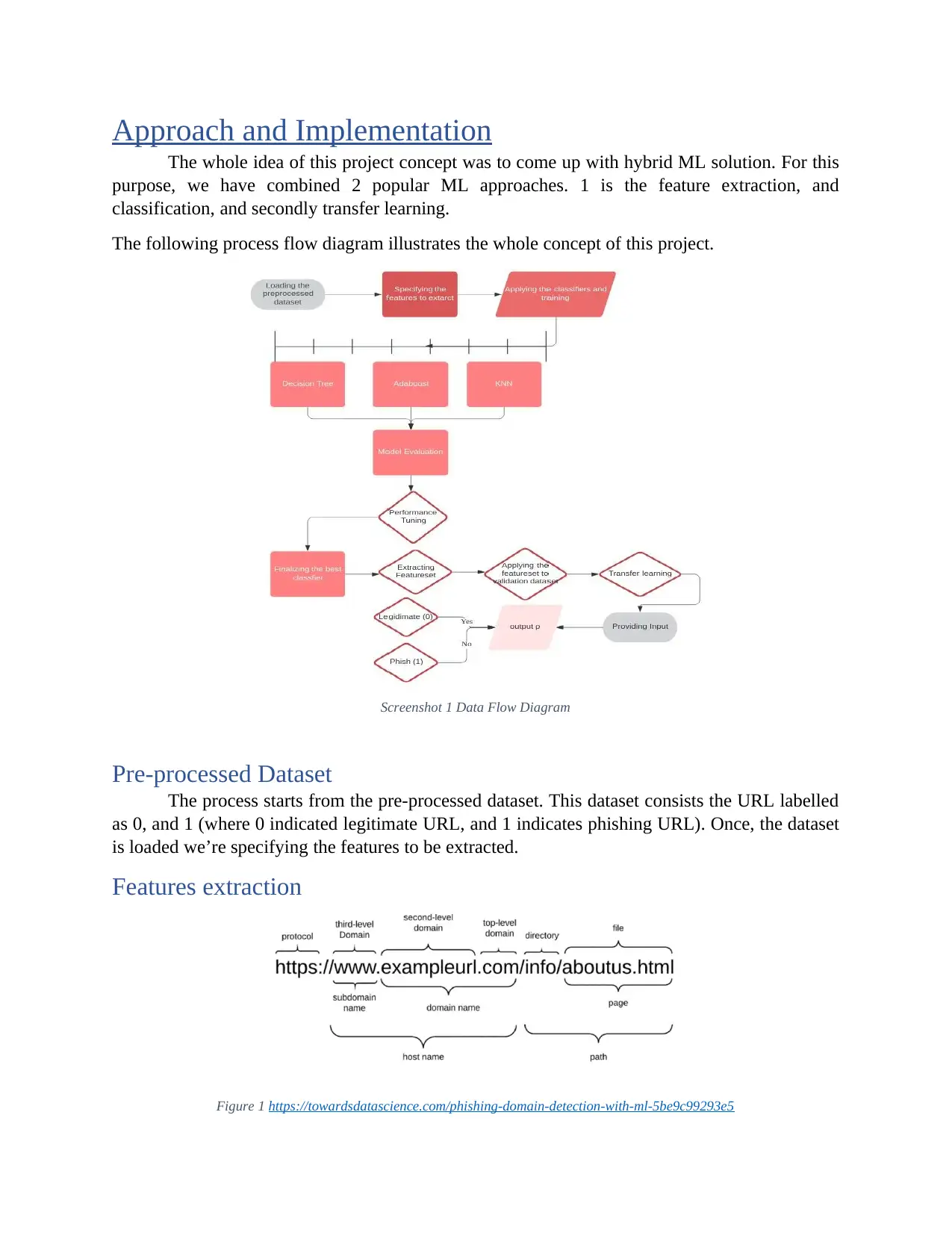
Approach and Implementation
The whole idea of this project concept was to come up with hybrid ML solution. For this
purpose, we have combined 2 popular ML approaches. 1 is the feature extraction, and
classification, and secondly transfer learning.
The following process flow diagram illustrates the whole concept of this project.
Screenshot 1 Data Flow Diagram
Pre-processed Dataset
The process starts from the pre-processed dataset. This dataset consists the URL labelled
as 0, and 1 (where 0 indicated legitimate URL, and 1 indicates phishing URL). Once, the dataset
is loaded we’re specifying the features to be extracted.
Features extraction
Figure 1 https://towardsdatascience.com/phishing-domain-detection-with-ml-5be9c99293e5
The whole idea of this project concept was to come up with hybrid ML solution. For this
purpose, we have combined 2 popular ML approaches. 1 is the feature extraction, and
classification, and secondly transfer learning.
The following process flow diagram illustrates the whole concept of this project.
Screenshot 1 Data Flow Diagram
Pre-processed Dataset
The process starts from the pre-processed dataset. This dataset consists the URL labelled
as 0, and 1 (where 0 indicated legitimate URL, and 1 indicates phishing URL). Once, the dataset
is loaded we’re specifying the features to be extracted.
Features extraction
Figure 1 https://towardsdatascience.com/phishing-domain-detection-with-ml-5be9c99293e5

Above image shows how the feature extraction going to work. Similar with this example, for our project
we extracted the features mentioned in the following table,
Domain information
Number of dots (.) in subdomain
Hyphen in domain (-)
URL Length
At in domain (@)
Double slash (//)
Sub domains
Whether IP is used as URL
The following screenshot shows the few lines of code used for few of features extracted.
Screenshot 2 Code for feature extraction
So, once the features are extracted, we have put them into a feature set which we going to use in
later steps of the program.
Applying classifiers
For this program we are using three classifiers, they are namely, Decision Tree, Adaboost, and
KNN. After the first test results, we have performed tuning to see how efficient it is. For tuning
purpose, we have used GridSearchCV. The following table shows the results of before and after
tuning.
Classifier Before tuning After Tuning
Decision Tree 0.808000 0.812709
Adaboost 0.799636 0.799345
KNN 0.786545 0.793162
we extracted the features mentioned in the following table,
Domain information
Number of dots (.) in subdomain
Hyphen in domain (-)
URL Length
At in domain (@)
Double slash (//)
Sub domains
Whether IP is used as URL
The following screenshot shows the few lines of code used for few of features extracted.
Screenshot 2 Code for feature extraction
So, once the features are extracted, we have put them into a feature set which we going to use in
later steps of the program.
Applying classifiers
For this program we are using three classifiers, they are namely, Decision Tree, Adaboost, and
KNN. After the first test results, we have performed tuning to see how efficient it is. For tuning
purpose, we have used GridSearchCV. The following table shows the results of before and after
tuning.
Classifier Before tuning After Tuning
Decision Tree 0.808000 0.812709
Adaboost 0.799636 0.799345
KNN 0.786545 0.793162
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

While seeing the performance results we can identify that slight variations between
before and after tuning. For decision tree, and KNN the after results are higher than before
tuning, whereas for Adaboost the after tuning results are little bit lower than the before tuning
result.
Finalizing the classifier
Since, decision tree results are quite better than other two classifiers we decided to select
it as our final classifier.
Applying transfer learning
So, after finalising the classifier we have transferred the decision tree feature set to our test
dataset to validate.
Screenshot 3 Transfer learning to test dataset
Screenshot 3 shows the accuracy of decision tree classifier on our new test dataset, in this we can
see that the accuracy on new dataset is higher than previous results which indicates its better
performance.
Providing Input
Screenshot 4 Testing with Phishing URL
before and after tuning. For decision tree, and KNN the after results are higher than before
tuning, whereas for Adaboost the after tuning results are little bit lower than the before tuning
result.
Finalizing the classifier
Since, decision tree results are quite better than other two classifiers we decided to select
it as our final classifier.
Applying transfer learning
So, after finalising the classifier we have transferred the decision tree feature set to our test
dataset to validate.
Screenshot 3 Transfer learning to test dataset
Screenshot 3 shows the accuracy of decision tree classifier on our new test dataset, in this we can
see that the accuracy on new dataset is higher than previous results which indicates its better
performance.
Providing Input
Screenshot 4 Testing with Phishing URL
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Screenshot 5 Testing with Legitimate URL
Screenshot 4, and 5 shows testing the solution by providing the input. For the purpose of
screenshot 4 we have given the URL that is taken from a Phishing URL collection website called
as Phish tank (Phish Tank, N.d). As we expected the ML program displays 1 which indicates the
given URL is a phishing one. For the screenshot 5 we have given the input of our school
webpage URL and the ML program displays 0 which indicates the given URL is legitimate one.
Performance Evaluation
The training dataset and testing dataset are created in 2014 and publicly available to
download from Aalto University [9]. It is a simple CSV file that contains 96,018 URLs, 48,009
is legitimate URLs and the remaining 48,009 are phishing URLs. Technically, it only consists of
one label, which is 0 or 1. 0 represents legitimate URL, 1 represents phishing URL. The
screenshot below shows the amount of labelled data.
Screenshot 6 The amount of labelled data
Within 96,018 URLs, only 13,749 of training data are picked due to the computational limitation
of computer resources. It consists of 6251 legitimate URLs and 7498 phishing URLs. In order to
reduce bias and accuracy, the legitimate and phishing URLs have been balanced to 6251 URLs
only. The plot below shows the balanced classes.
Screenshot 4, and 5 shows testing the solution by providing the input. For the purpose of
screenshot 4 we have given the URL that is taken from a Phishing URL collection website called
as Phish tank (Phish Tank, N.d). As we expected the ML program displays 1 which indicates the
given URL is a phishing one. For the screenshot 5 we have given the input of our school
webpage URL and the ML program displays 0 which indicates the given URL is legitimate one.
Performance Evaluation
The training dataset and testing dataset are created in 2014 and publicly available to
download from Aalto University [9]. It is a simple CSV file that contains 96,018 URLs, 48,009
is legitimate URLs and the remaining 48,009 are phishing URLs. Technically, it only consists of
one label, which is 0 or 1. 0 represents legitimate URL, 1 represents phishing URL. The
screenshot below shows the amount of labelled data.
Screenshot 6 The amount of labelled data
Within 96,018 URLs, only 13,749 of training data are picked due to the computational limitation
of computer resources. It consists of 6251 legitimate URLs and 7498 phishing URLs. In order to
reduce bias and accuracy, the legitimate and phishing URLs have been balanced to 6251 URLs
only. The plot below shows the balanced classes.
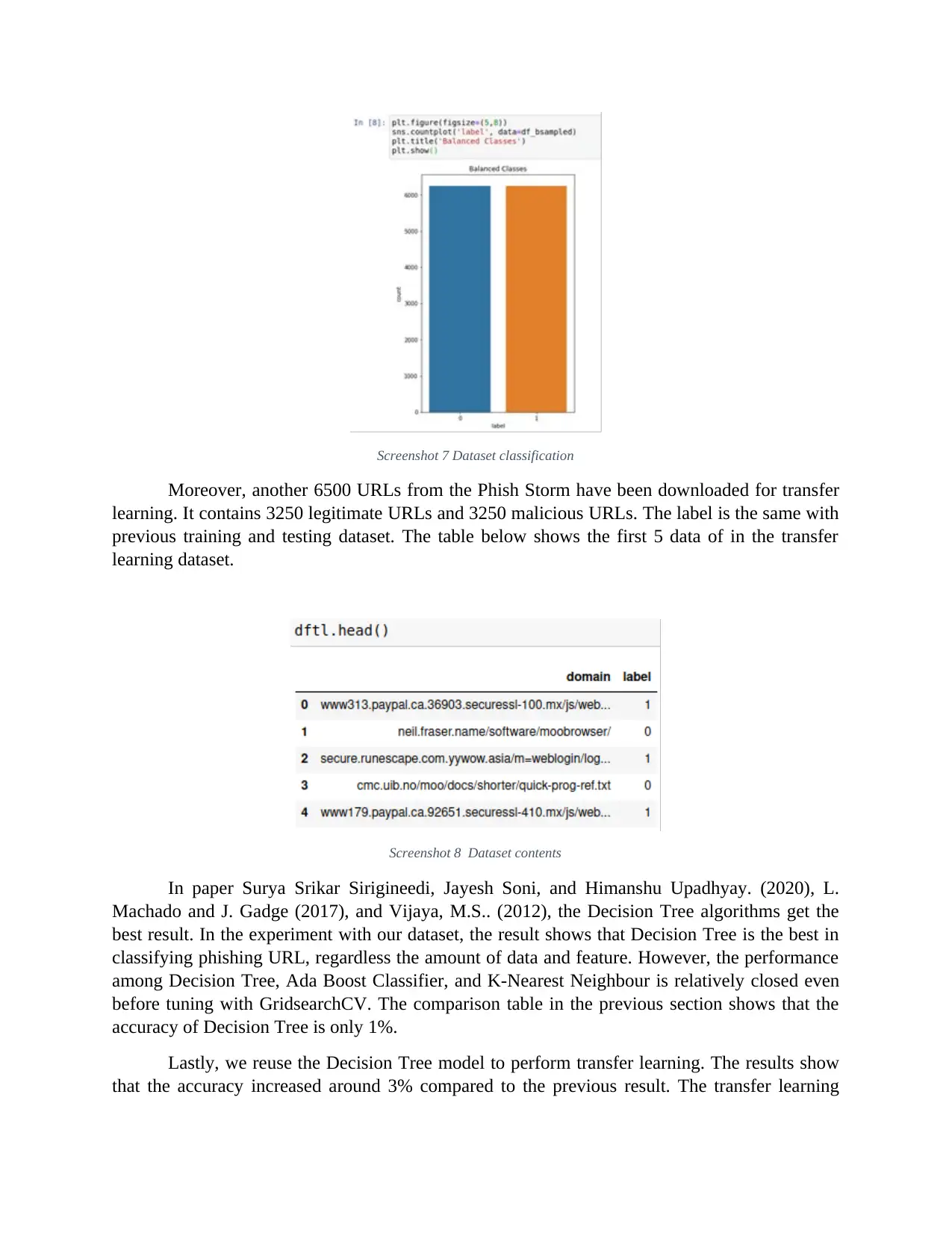
Screenshot 7 Dataset classification
Moreover, another 6500 URLs from the Phish Storm have been downloaded for transfer
learning. It contains 3250 legitimate URLs and 3250 malicious URLs. The label is the same with
previous training and testing dataset. The table below shows the first 5 data of in the transfer
learning dataset.
Screenshot 8 Dataset contents
In paper Surya Srikar Sirigineedi, Jayesh Soni, and Himanshu Upadhyay. (2020), L.
Machado and J. Gadge (2017), and Vijaya, M.S.. (2012), the Decision Tree algorithms get the
best result. In the experiment with our dataset, the result shows that Decision Tree is the best in
classifying phishing URL, regardless the amount of data and feature. However, the performance
among Decision Tree, Ada Boost Classifier, and K-Nearest Neighbour is relatively closed even
before tuning with GridsearchCV. The comparison table in the previous section shows that the
accuracy of Decision Tree is only 1%.
Lastly, we reuse the Decision Tree model to perform transfer learning. The results show
that the accuracy increased around 3% compared to the previous result. The transfer learning
Moreover, another 6500 URLs from the Phish Storm have been downloaded for transfer
learning. It contains 3250 legitimate URLs and 3250 malicious URLs. The label is the same with
previous training and testing dataset. The table below shows the first 5 data of in the transfer
learning dataset.
Screenshot 8 Dataset contents
In paper Surya Srikar Sirigineedi, Jayesh Soni, and Himanshu Upadhyay. (2020), L.
Machado and J. Gadge (2017), and Vijaya, M.S.. (2012), the Decision Tree algorithms get the
best result. In the experiment with our dataset, the result shows that Decision Tree is the best in
classifying phishing URL, regardless the amount of data and feature. However, the performance
among Decision Tree, Ada Boost Classifier, and K-Nearest Neighbour is relatively closed even
before tuning with GridsearchCV. The comparison table in the previous section shows that the
accuracy of Decision Tree is only 1%.
Lastly, we reuse the Decision Tree model to perform transfer learning. The results show
that the accuracy increased around 3% compared to the previous result. The transfer learning
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

optimises the progress and improve the performance at the same time. The final result and other
metrics can refer to the screenshots below.
Screenshot 9 Decision Tree Classifier Final Result
Specifications
Hardware – i5-7200U, 4 GB DDR4 RAM, 20 GB HDD Storage.
Software – Anaconda Individual Edition 4.8.3 (Python 3.8), Jupyter Notebook.
Future Work
In addition to this project, many enhancements can be done on top of it. One main
enhancement could be including more classifier algorithms like KNN classifier, etc... Also, for
the common use of this project front-end work can be done with Flask framework that utilises
our ML solution. With this a website can be created and people can place the URL then can get
the results whether the submitted URL is Phishing or Legitimate.
Contribution
Member Name Work Done
Phone Literature review, Documentation, Code debug
Tan Literature review, Data Set Preparation, Documentation,
Classifier Programming
Samson Literature review, Documentation, Feature extraction
programming.
Conclusion
In this paper, we illustrated the implementation concept flow diagram for the project. We
combined two popular machine learning approaches, feature extractions classification and
metrics can refer to the screenshots below.
Screenshot 9 Decision Tree Classifier Final Result
Specifications
Hardware – i5-7200U, 4 GB DDR4 RAM, 20 GB HDD Storage.
Software – Anaconda Individual Edition 4.8.3 (Python 3.8), Jupyter Notebook.
Future Work
In addition to this project, many enhancements can be done on top of it. One main
enhancement could be including more classifier algorithms like KNN classifier, etc... Also, for
the common use of this project front-end work can be done with Flask framework that utilises
our ML solution. With this a website can be created and people can place the URL then can get
the results whether the submitted URL is Phishing or Legitimate.
Contribution
Member Name Work Done
Phone Literature review, Documentation, Code debug
Tan Literature review, Data Set Preparation, Documentation,
Classifier Programming
Samson Literature review, Documentation, Feature extraction
programming.
Conclusion
In this paper, we illustrated the implementation concept flow diagram for the project. We
combined two popular machine learning approaches, feature extractions classification and
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

transfer learning. Applied the three popular classifiers and performed tuning by using
GridSearchCV. After comparing the results, Decision Tree was selected as the final classifier
and transferred its feature and set to our test dataset to validate. We described the performance
evaluation which include the dataset we used for the testing and compare performance of chosen
algorithm with another algorithm. We have learned that dataset is very important in Machine
Learning. Some phishing websites looks too closed to the legitimate websites and the properties
of the URLs are configured as same as to perform as legitimate website. To detect most all of
them, we more need to train the model with suitable features. Machine do not make decision and
we need to use dataset, feature extraction and algorithms in a proper way.
References
BAHARUDIN, H. (2020). Three times more phishing attacks in Singapore in 2019, twice as
many during Covid-19 pandemic. Retrieved 30 July 2020, from
https://www.straitstimes.com/singapore/three-times-more-phishing-attacks-in-singapore-in-
2019-twice-as-many-during-covid-19
GridSearchCV. After comparing the results, Decision Tree was selected as the final classifier
and transferred its feature and set to our test dataset to validate. We described the performance
evaluation which include the dataset we used for the testing and compare performance of chosen
algorithm with another algorithm. We have learned that dataset is very important in Machine
Learning. Some phishing websites looks too closed to the legitimate websites and the properties
of the URLs are configured as same as to perform as legitimate website. To detect most all of
them, we more need to train the model with suitable features. Machine do not make decision and
we need to use dataset, feature extraction and algorithms in a proper way.
References
BAHARUDIN, H. (2020). Three times more phishing attacks in Singapore in 2019, twice as
many during Covid-19 pandemic. Retrieved 30 July 2020, from
https://www.straitstimes.com/singapore/three-times-more-phishing-attacks-in-singapore-in-
2019-twice-as-many-during-covid-19

Singapore Govt. (2020). Watch out for fake govt websites and links by scammers taking
advantage of COVID-19 situation. Retrieved 30 July 2020, from
https://www.gov.sg/article/watch-out-for-fake-govt-websites-and-links-by-scammers-taking-
advantage-of-covid-19-situation
Singcert. (2020). Singapore Businesses Reportedly Among Targets of Global Phishing
Campaign. Retrieved 30 July 2020, from https://www.csa.gov.sg/singcert/advisories/ad-2020-
005
Oumaima El Kouari, Hafssa Benaboud, and Saiida Lazaar. (2020). Using machine learning to
deal with Phishing and Spam Detection: An overview. In Proceedings of the 3rd International
Conference on Networking, Information Systems & Security (NISS2020). Association for
Computing Machinery, New York, NY, USA, Article 72, 1–7.
DOI:https://doi.org/10.1145/3386723.3387891
Surya Srikar Sirigineedi, Jayesh Soni, and Himanshu Upadhyay. (2020). Learning-based models
to detect runtime phishing activities using URLs. In Proceedings of the 2020 the 4th
International Conference on Compute and Data Analysis (ICCDA 2020). Association for
Computing Machinery, New York, NY, USA, 102–106.
DOI:https://doi.org/10.1145/3388142.3388170
L. Machado and J. Gadge, "Phishing Sites Detection Based on C4.5 Decision Tree Algorithm,"
(2017) International Conference on Computing, Communication, Control and Automation
(ICCUBEA), Pune, 2017, pp. 1-5, doi: 10.1109/ICCUBEA.2017.8463818.
Vijaya, M.S.. (2012). Efficient prediction of phishing websites using supervised learning
algorithms. Procedia Engineering. 30. 798-805. 10.1016/j.proeng.2012.01.930.
Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir, Banu Diri, (2017) Machine learning
based phishing detection from URLs, Expert Systems with Applications, Volume 117, 2019,
Pages 345-357, ISSN 0957-4174, https://doi.org/10.1016/j.eswa.2018.09.029.
Marchal, S. (Creator) (2014). PhishStorm - phishing / legitimate URL dataset. Aalto University.
urlset(v.zip).
Figure 1 https://towardsdatascience.com/phishing-domain-detection-with-ml-5be9c99293e5
Phish Tank (N.d) https://www.phishtank.com/
advantage of COVID-19 situation. Retrieved 30 July 2020, from
https://www.gov.sg/article/watch-out-for-fake-govt-websites-and-links-by-scammers-taking-
advantage-of-covid-19-situation
Singcert. (2020). Singapore Businesses Reportedly Among Targets of Global Phishing
Campaign. Retrieved 30 July 2020, from https://www.csa.gov.sg/singcert/advisories/ad-2020-
005
Oumaima El Kouari, Hafssa Benaboud, and Saiida Lazaar. (2020). Using machine learning to
deal with Phishing and Spam Detection: An overview. In Proceedings of the 3rd International
Conference on Networking, Information Systems & Security (NISS2020). Association for
Computing Machinery, New York, NY, USA, Article 72, 1–7.
DOI:https://doi.org/10.1145/3386723.3387891
Surya Srikar Sirigineedi, Jayesh Soni, and Himanshu Upadhyay. (2020). Learning-based models
to detect runtime phishing activities using URLs. In Proceedings of the 2020 the 4th
International Conference on Compute and Data Analysis (ICCDA 2020). Association for
Computing Machinery, New York, NY, USA, 102–106.
DOI:https://doi.org/10.1145/3388142.3388170
L. Machado and J. Gadge, "Phishing Sites Detection Based on C4.5 Decision Tree Algorithm,"
(2017) International Conference on Computing, Communication, Control and Automation
(ICCUBEA), Pune, 2017, pp. 1-5, doi: 10.1109/ICCUBEA.2017.8463818.
Vijaya, M.S.. (2012). Efficient prediction of phishing websites using supervised learning
algorithms. Procedia Engineering. 30. 798-805. 10.1016/j.proeng.2012.01.930.
Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir, Banu Diri, (2017) Machine learning
based phishing detection from URLs, Expert Systems with Applications, Volume 117, 2019,
Pages 345-357, ISSN 0957-4174, https://doi.org/10.1016/j.eswa.2018.09.029.
Marchal, S. (Creator) (2014). PhishStorm - phishing / legitimate URL dataset. Aalto University.
urlset(v.zip).
Figure 1 https://towardsdatascience.com/phishing-domain-detection-with-ml-5be9c99293e5
Phish Tank (N.d) https://www.phishtank.com/
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 16



Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.