MongoDB Database Analysis Project for Big Data - MIT-BDS-02
VerifiedAdded on 2022/12/23
|15
|689
|24
Project
AI Summary
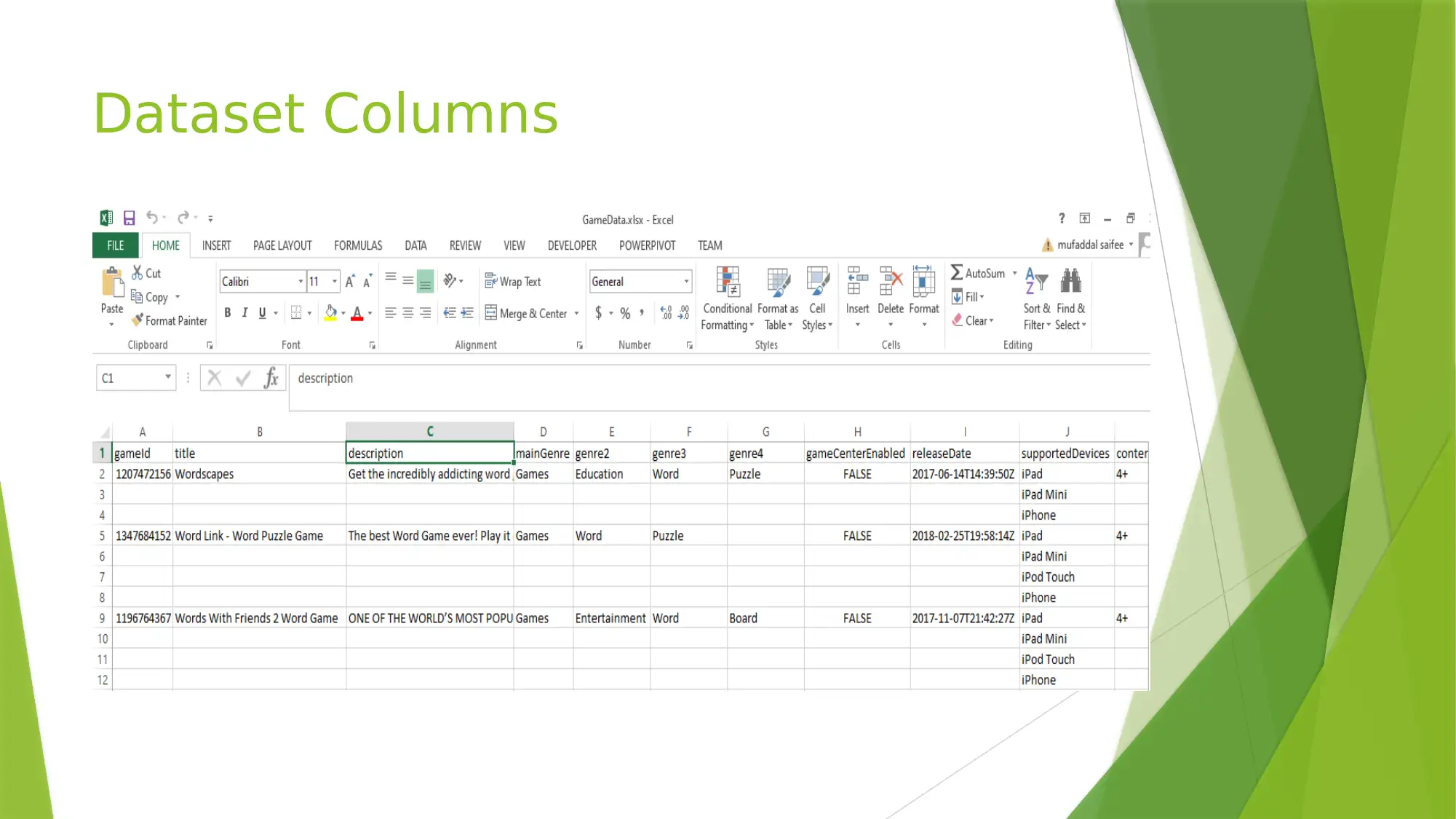
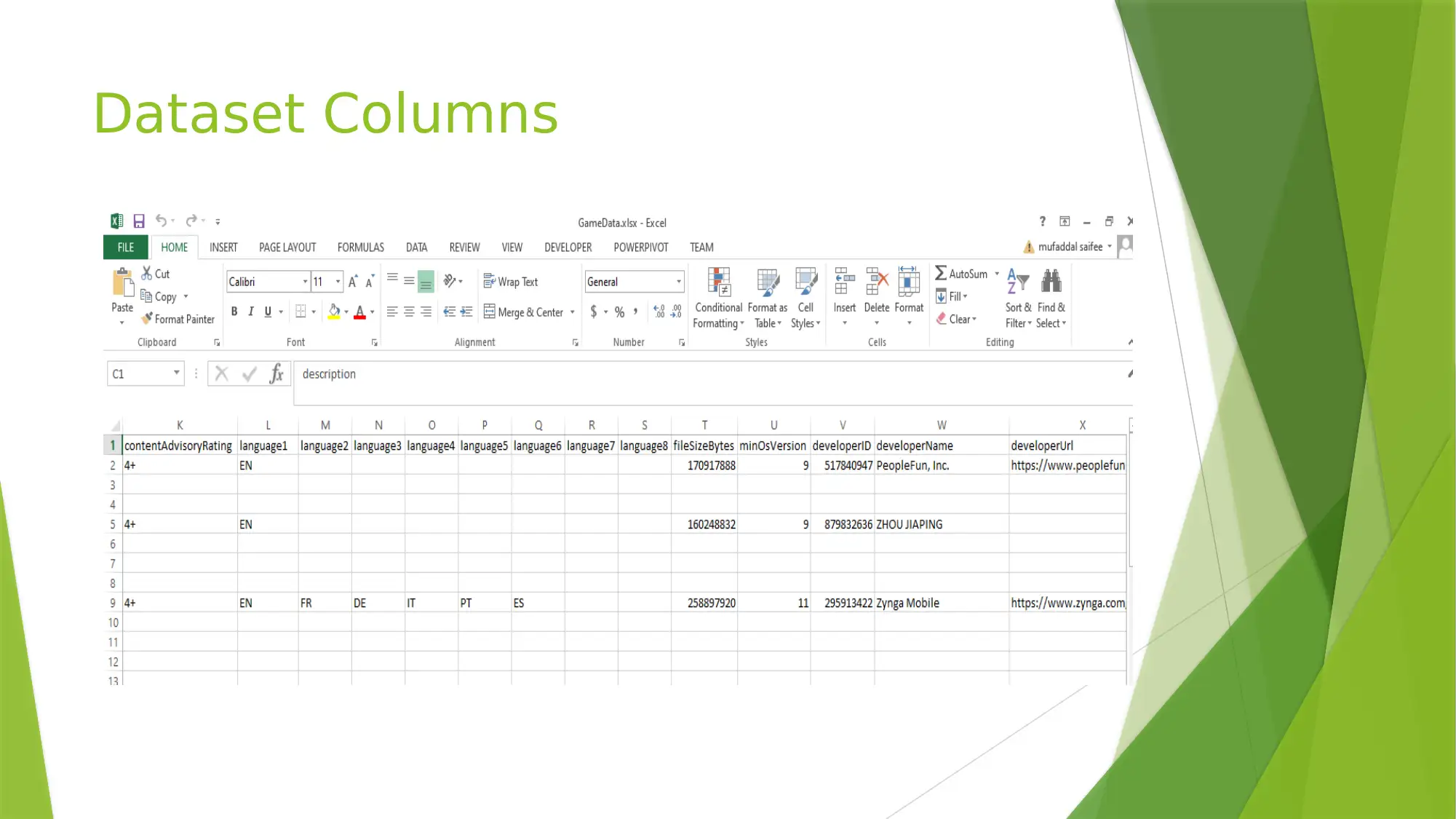
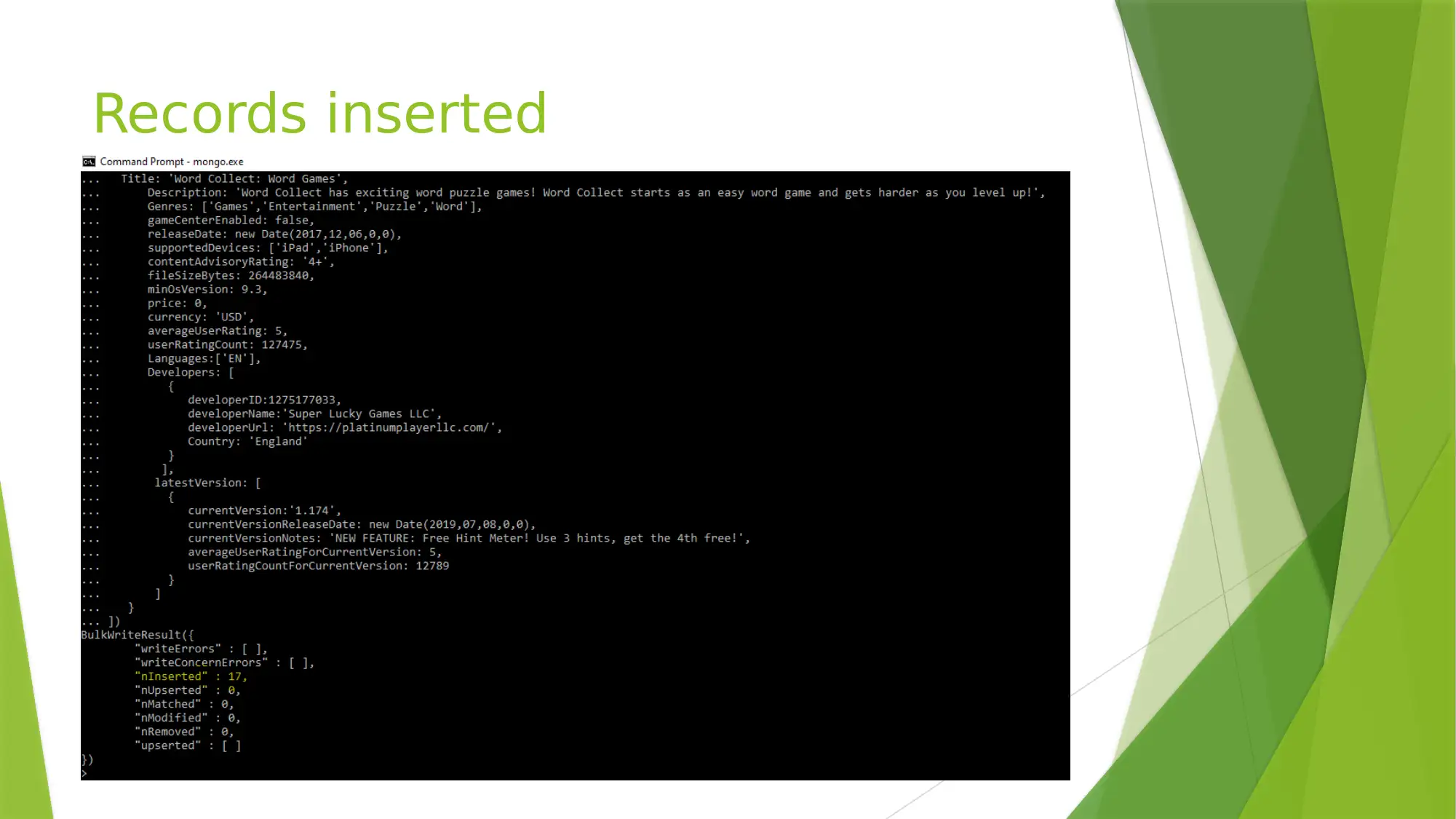
This project explores the use of MongoDB, a NoSQL database, for analyzing a 'GameData.xlsx' dataset. The project details the structure of MongoDB, including databases, collections, and documents, and demonstrates how to import and query the dataset. It covers creating a database named 'dbase_games', inserting records, and performing various queries to gain insights into the dataset, such as finding free games, calculating average prices for different age groups, and identifying games not supported on Apple devices. The reflection highlights the flexibility of MongoDB, the ease of querying, and the differences between SQL and NoSQL databases. This assignment helped in understanding the issues with SQL and features present in NoSQL and how the schema can be defined and changed at runtime in NoSQL.









1 out of 15
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.