Analyzing Movie Data with MongoDB: Queries, Indexing, and DB Overview
VerifiedAdded on 2019/09/30
|11
|2420
|437
Homework Assignment
AI Summary
This assignment delves into the practical application of MongoDB for managing and querying movie data. Part A focuses on executing various queries to retrieve specific information from a 'movies' and 'rating' database, demonstrating the use of indexing to optimize data retrieval. The queries cover tasks such as finding movie names, filtering by country, extracting director and movie names, counting records, and retrieving data based on Oscar wins and average ratings. Part B provides a detailed database description, outlining the structure of the movie and rating datasets, including fields like movie name, director, country, and rating details. The document then explores the advantages and disadvantages of using MongoDB, and compares it to other database technologies like Cassandra, Redis, CouchDB, HBase, and MySQL, highlighting their strengths and weaknesses in different use cases. Finally, the document recommends the use of MongoDB for storing and retrieving movie information and suggests its application in retail for logging high-volume client movement data and performing data analysis, including recommendations and personalization for users.

Part A
Queries
Queries
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
insert
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Indexs
use movie
db.createCollections("movies")
db.createColection("rating")
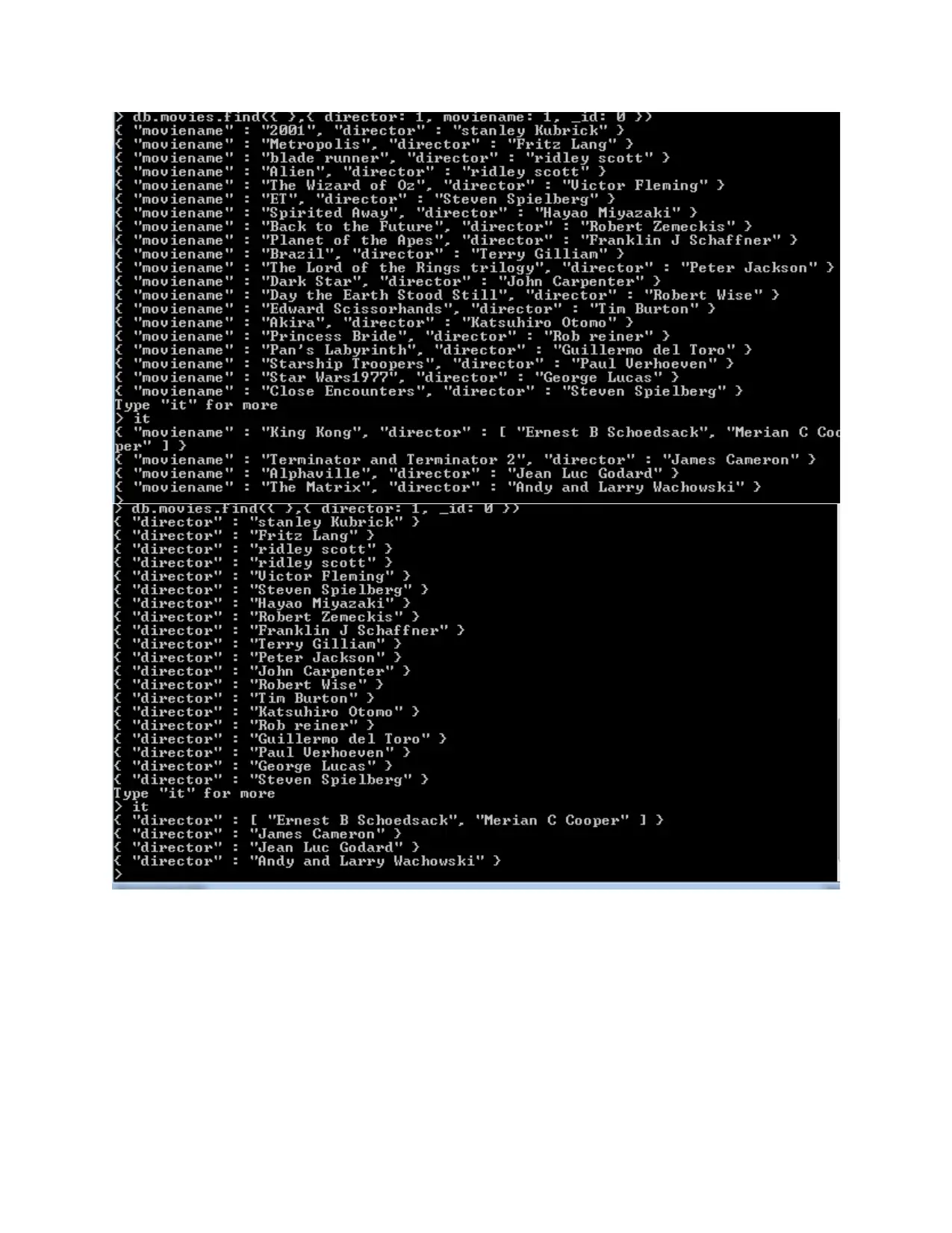
db.movies.find({ },{ moviename: 1, _id: 0 })
db.movies.find({ country: "japan" },{ moviename: 1, country: 1, _id: 0 })
db.movies.find({ },{ director: 1, moviename: 1, _id: 0 })
db.movies.find().count()
db.movies.find({ oscarwon: 1 },{ moviename: 1, oscarwon: 1, _id: 0 })
db.rating.find({},{"avg(rating)": 1,"movieid": 1});
db.rating.find({},{"avg(rating)": 1})
db.rating.find({"rating" : "" },{"movieid": 1,"rating": 1,"comments": 1})
db.ATEmovies SET moviename ="E.T." .find({ "director" : "Steven Spielberg",{" ":1} } )
use movie
db.createCollections("movies")
db.createColection("rating")
db.movies.find({ },{ moviename: 1, _id: 0 })
db.movies.find({ country: "japan" },{ moviename: 1, country: 1, _id: 0 })
db.movies.find({ },{ director: 1, moviename: 1, _id: 0 })
db.movies.find().count()
db.movies.find({ oscarwon: 1 },{ moviename: 1, oscarwon: 1, _id: 0 })
db.rating.find({},{"avg(rating)": 1,"movieid": 1});
db.rating.find({},{"avg(rating)": 1})
db.rating.find({"rating" : "" },{"movieid": 1,"rating": 1,"comments": 1})
db.ATEmovies SET moviename ="E.T." .find({ "director" : "Steven Spielberg",{" ":1} } )
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Part B
Database description :
Give information to mongoDB Database dealing with have two kind of informational
index like Movie and rating set. Motion picture dataset are given the insights about the motion
picture like motion picture name , film's executives, motion picture's driving job and discharged
date , discharged nation and how much time motion picture have gotten the Award . furthermore,
evaluating dataset inform that regarding the rating of the films by the Movie id and who give the
rating his name , what will be the remarks and rating set by the 1 to 10 all appraising will be
recorded by the date.
Ingestion of a huge number of composes every second: Normally MongoDB performs irregular
access composes. In our utilization case this could prompt an unsuitable measure of circle
fracture, so we utilized HVDF (more on this in a later) to store the information consecutively in
an affix just mold.
Adaptable pattern: To limit the measure of storage room required, the blueprint of every
movement being logged is put away in indistinguishable configuration and size from it is gotten.
Quick questioning and arranging on differed fields: Secondary Btree files guarantee that our
most normal queries and sorts will be performed in milliseconds.
Simple erases of old information: Typically, erasing substantial quantities of archives is a
generally costly task in MongoDB. By time parceling our information into accumulations
utilizing HVDF we can drop whole accumulations as a free activity.
Alternative modeling
MongoDB
Masters MongoDB reports can be utilized to store the unstructured information in a way that is
moderately clear to refresh should you have a circumstance where you are de-normalizing your
Database description :
Give information to mongoDB Database dealing with have two kind of informational
index like Movie and rating set. Motion picture dataset are given the insights about the motion
picture like motion picture name , film's executives, motion picture's driving job and discharged
date , discharged nation and how much time motion picture have gotten the Award . furthermore,
evaluating dataset inform that regarding the rating of the films by the Movie id and who give the
rating his name , what will be the remarks and rating set by the 1 to 10 all appraising will be
recorded by the date.
Ingestion of a huge number of composes every second: Normally MongoDB performs irregular
access composes. In our utilization case this could prompt an unsuitable measure of circle
fracture, so we utilized HVDF (more on this in a later) to store the information consecutively in
an affix just mold.
Adaptable pattern: To limit the measure of storage room required, the blueprint of every
movement being logged is put away in indistinguishable configuration and size from it is gotten.
Quick questioning and arranging on differed fields: Secondary Btree files guarantee that our
most normal queries and sorts will be performed in milliseconds.
Simple erases of old information: Typically, erasing substantial quantities of archives is a
generally costly task in MongoDB. By time parceling our information into accumulations
utilizing HVDF we can drop whole accumulations as a free activity.
Alternative modeling
MongoDB
Masters MongoDB reports can be utilized to store the unstructured information in a way that is
moderately clear to refresh should you have a circumstance where you are de-normalizing your

database diagram. Additionally, It offers a high embed rate which is helpful in a circumstance
where the compose stack is high.
Cons - It isn't worked for value-based information, (for example, bookkeeping frameworks). No
capacity or put away technique exists where you can tie the rationale. As in all NoSQL, most
arrangements are not firmly ACID-consistent. While MongoDB does not give toughness
naturally, it lets you tune the design of a copy set should you will forfeit enough execution.
Best for - Mobile applications, content administration, ongoing investigation, and applications
including IoT.
Cassandra
Apache Cassandra is a hugely versatile open source non-social database. It's qualities incorporate
persistent accessibility, direct scale execution, operational effortlessness and simple information
conveyance over various server farms and cloud accessibility zones. Cassandra was initially
created at Facebook (note: intended for gigantic adaptability). Cassandra was composed in Java
and can be sent on BSD, Linux, OS X, and Windows.
Masters – Cassandra can scale while as yet being dependable. It is conceivable to convey
Cassandra over different servers effortlessly. Some portion of this is because of the way that
Cassandra handles replication with negligible setup, making it direct to set up. Another element
called Lightweight Transactions (LWT) was discharged in Cassandra 2.0 that conveys ACID
capacities to your information display when required. .
Cons – No specially appointed inquiries, implying that you should demonstrate your information
around the questions you need to surface, as opposed to around the structure of the information
itself. On the off chance that doing specially appointed examination is a necessity for your
application then Cassandra may not be for you. While fresher forms of Cassandra have restricted
help for accumulations with a solitary parcel, collections are asset concentrated notwithstanding
when conceivable.
Best for - If you require substantial and adaptable compose framework and you require a
responsive announcing framework based over that put away information, e.g as progressively
investigation.
Profound Dive Cassandra versus MongoDB >
where the compose stack is high.
Cons - It isn't worked for value-based information, (for example, bookkeeping frameworks). No
capacity or put away technique exists where you can tie the rationale. As in all NoSQL, most
arrangements are not firmly ACID-consistent. While MongoDB does not give toughness
naturally, it lets you tune the design of a copy set should you will forfeit enough execution.
Best for - Mobile applications, content administration, ongoing investigation, and applications
including IoT.
Cassandra
Apache Cassandra is a hugely versatile open source non-social database. It's qualities incorporate
persistent accessibility, direct scale execution, operational effortlessness and simple information
conveyance over various server farms and cloud accessibility zones. Cassandra was initially
created at Facebook (note: intended for gigantic adaptability). Cassandra was composed in Java
and can be sent on BSD, Linux, OS X, and Windows.
Masters – Cassandra can scale while as yet being dependable. It is conceivable to convey
Cassandra over different servers effortlessly. Some portion of this is because of the way that
Cassandra handles replication with negligible setup, making it direct to set up. Another element
called Lightweight Transactions (LWT) was discharged in Cassandra 2.0 that conveys ACID
capacities to your information display when required. .
Cons – No specially appointed inquiries, implying that you should demonstrate your information
around the questions you need to surface, as opposed to around the structure of the information
itself. On the off chance that doing specially appointed examination is a necessity for your
application then Cassandra may not be for you. While fresher forms of Cassandra have restricted
help for accumulations with a solitary parcel, collections are asset concentrated notwithstanding
when conceivable.
Best for - If you require substantial and adaptable compose framework and you require a
responsive announcing framework based over that put away information, e.g as progressively
investigation.
Profound Dive Cassandra versus MongoDB >
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Redis
On the off chance that you require an elite, rapid database, Redis is difficult to beat (however
there are some vital admonitions). It underpins information structures, for example, strings,
hashes, records, sets, arranged sets with run inquiries, bitmaps, hyperloglogs and geospatial lists
with sweep questions. You can run nuclear tasks on these sorts. Redis' expedient execution
depends on its working with an in-memory dataset.
Furthermore, there's the rub. It works best with plainly characterized—and constrained—
datasets. It is normally not an independent database (Craigslist conveys Redis nearby an essential
database). It is best utilized when you have quickly changing information with a predictable
database estimate (that can—or for the most part can- - fit in memory). Models incorporate
putting away continuous stock costs, investigation, correspondence and Leaderboards.
Experts - An elite, wonderfully quick database. Redis can be a decent method to expand the
speed of a current application, incorporating those in which snappy access to particular keys is a
need.
Cons - You need to design your plan and choose ahead of time how you need to store and
afterward compose your information. Redis isn't appropriate for prototyping. Because of its
working with in-memory datasets, it doesn't scale well. There is no official help for Windows
manufactures, in spite of the fact that Microsoft creates and keeps up a Win-64 port of Redis.
Best for - Redis is the best approach in the event that you require an exceedingly adaptable
information store shared by numerous procedures, various applications, or different servers.
CouchDB
Written in Erlang, CouchDB is a record arranged database that can be conveyed as an
independent application structure or with high-volume, circulated applications. It is particularly
helpful for web applications that handle enormous measures of inexactly organized information
because of its straightforward model for putting away, preparing, and getting to information. It is
particularly suited to CRM, CMS frameworks. Its ability for ace replication takes into
consideration simple multi-site organizations.
Masters - Database consistency that depends on bi-directional replication. Additionally, as
CouchDB works as a web server, which means, in the expressions of one of its makers, J. Chris
On the off chance that you require an elite, rapid database, Redis is difficult to beat (however
there are some vital admonitions). It underpins information structures, for example, strings,
hashes, records, sets, arranged sets with run inquiries, bitmaps, hyperloglogs and geospatial lists
with sweep questions. You can run nuclear tasks on these sorts. Redis' expedient execution
depends on its working with an in-memory dataset.
Furthermore, there's the rub. It works best with plainly characterized—and constrained—
datasets. It is normally not an independent database (Craigslist conveys Redis nearby an essential
database). It is best utilized when you have quickly changing information with a predictable
database estimate (that can—or for the most part can- - fit in memory). Models incorporate
putting away continuous stock costs, investigation, correspondence and Leaderboards.
Experts - An elite, wonderfully quick database. Redis can be a decent method to expand the
speed of a current application, incorporating those in which snappy access to particular keys is a
need.
Cons - You need to design your plan and choose ahead of time how you need to store and
afterward compose your information. Redis isn't appropriate for prototyping. Because of its
working with in-memory datasets, it doesn't scale well. There is no official help for Windows
manufactures, in spite of the fact that Microsoft creates and keeps up a Win-64 port of Redis.
Best for - Redis is the best approach in the event that you require an exceedingly adaptable
information store shared by numerous procedures, various applications, or different servers.
CouchDB
Written in Erlang, CouchDB is a record arranged database that can be conveyed as an
independent application structure or with high-volume, circulated applications. It is particularly
helpful for web applications that handle enormous measures of inexactly organized information
because of its straightforward model for putting away, preparing, and getting to information. It is
particularly suited to CRM, CMS frameworks. Its ability for ace replication takes into
consideration simple multi-site organizations.
Masters - Database consistency that depends on bi-directional replication. Additionally, as
CouchDB works as a web server, which means, in the expressions of one of its makers, J. Chris
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Anderson, "you can serve applications specifically to the program with no center level." So
generally, you can start up a couchdb server and begin serving site pages consequently. It talks
the dialects of the web (HTTP, JSON, HTML) s you can begin stating "CouchApps" without
another layer over the database.
Cons – Needs intermittent compacting. Best for-Web applications that handle colossal measures
of approximately organized information because of its straightforward model for putting away,
preparing, and getting to information.
HBase
Made in Java for facilitating substantial tables, Apache HBase gives arbitrary, ongoing access to
information in Hadoop. It is particularly appropriate for putting away multi-organized or scanty
information. HBase is an extraordinary choice "for putting away semi-organized information like
log information and afterward giving that information rapidly to clients or applications
coordinated with HBase." It is particularly valuable for any utilization case in which examining
enormous, two-dimensional join-less tables are a necessity.
Experts - Users can inquiry HBase for a specific point in time, making "flashback" inquiries
conceivable.
Cons - Not enhanced for great value-based applications or even social examination.
Best for-appropriate for putting away multi-organized or inadequate information.
MySQL
MySQL has set up itself as "the main database decision for electronic applications, utilized by
prominent web properties including Facebook, Twitter, YouTube, and every one of the five of
the best five sites. Moreover, it is a to a great degree prominent decision as installed database,
dispersed by a huge number of ISVs and OEMs." MySQL is a focal segment of the LAMP open-
source web application programming stack (and other "AMP" stacks; LAMP being an acronym
for "Linux, Apache, MySQL, Perl/PHP/Python").
Geniuses – Optimized for Web applications, turning into the "go to" stage for web designers and
the default database for electronic applications. Appropriate to little to medium website pages
and is ordinarily sent "for php and java based web applications that require a DV stockpiling
backend." It stays open source, in spite of the fact that with exclusive highlights that can be
generally, you can start up a couchdb server and begin serving site pages consequently. It talks
the dialects of the web (HTTP, JSON, HTML) s you can begin stating "CouchApps" without
another layer over the database.
Cons – Needs intermittent compacting. Best for-Web applications that handle colossal measures
of approximately organized information because of its straightforward model for putting away,
preparing, and getting to information.
HBase
Made in Java for facilitating substantial tables, Apache HBase gives arbitrary, ongoing access to
information in Hadoop. It is particularly appropriate for putting away multi-organized or scanty
information. HBase is an extraordinary choice "for putting away semi-organized information like
log information and afterward giving that information rapidly to clients or applications
coordinated with HBase." It is particularly valuable for any utilization case in which examining
enormous, two-dimensional join-less tables are a necessity.
Experts - Users can inquiry HBase for a specific point in time, making "flashback" inquiries
conceivable.
Cons - Not enhanced for great value-based applications or even social examination.
Best for-appropriate for putting away multi-organized or inadequate information.
MySQL
MySQL has set up itself as "the main database decision for electronic applications, utilized by
prominent web properties including Facebook, Twitter, YouTube, and every one of the five of
the best five sites. Moreover, it is a to a great degree prominent decision as installed database,
dispersed by a huge number of ISVs and OEMs." MySQL is a focal segment of the LAMP open-
source web application programming stack (and other "AMP" stacks; LAMP being an acronym
for "Linux, Apache, MySQL, Perl/PHP/Python").
Geniuses – Optimized for Web applications, turning into the "go to" stage for web designers and
the default database for electronic applications. Appropriate to little to medium website pages
and is ordinarily sent "for php and java based web applications that require a DV stockpiling
backend." It stays open source, in spite of the fact that with exclusive highlights that can be

bought from Oracle. It has an exceptionally well and faithful after among engineers who sing its
commendations.
Cons - Some issues with steadiness and grouping. With the general form, it very well may
challenge introduce a reliable database bunch with MySQL. Contingent upon the database
stockpiling, MySQL will bolster exchanges or not.
Most appropriate for - concentrated basically in OLTP exchanges and if it's architectured
legitimately, MySQL can be scaled to a large number of inquiries every second.
Justification of indexes
Files bolster the effective execution of questions in MongoDB. Without files, MongoDB must
play out a gathering filter, i.e. examine each record in an accumulation, to choose those reports
that match the inquiry proclamation. On the off chance that a fitting list exists for an inquiry,
MongoDB can utilize the list to restrain the quantity of archives it must review.
Records are unique information structures that store a little segment of the gathering's
informational collection in a simple to cross frame. The list stores the estimation of a particular
field or set of fields, requested by the estimation of the field. The requesting of the file passages
bolsters productive uniformity matches and range-based inquiry tasks. Likewise, MongoDB can
return arranged outcomes by utilizing the requesting in the file.
db.createCollections("movies")
create table for insert the data As a name of movies
db.createColection("rating")
create table for insert the data As a name of rating
{"comments":"" }
this index value show that define the comments field where value is emplty.
{"movieid": 1,"rating": 1,"comments": 1}
select All data to the dataset by this index it means fetch the value by this movieid, rating,
and comments terms
{"avg(rating)": 1}
Retrieve the average value of mathematics parts like rating
commendations.
Cons - Some issues with steadiness and grouping. With the general form, it very well may
challenge introduce a reliable database bunch with MySQL. Contingent upon the database
stockpiling, MySQL will bolster exchanges or not.
Most appropriate for - concentrated basically in OLTP exchanges and if it's architectured
legitimately, MySQL can be scaled to a large number of inquiries every second.
Justification of indexes
Files bolster the effective execution of questions in MongoDB. Without files, MongoDB must
play out a gathering filter, i.e. examine each record in an accumulation, to choose those reports
that match the inquiry proclamation. On the off chance that a fitting list exists for an inquiry,
MongoDB can utilize the list to restrain the quantity of archives it must review.
Records are unique information structures that store a little segment of the gathering's
informational collection in a simple to cross frame. The list stores the estimation of a particular
field or set of fields, requested by the estimation of the field. The requesting of the file passages
bolsters productive uniformity matches and range-based inquiry tasks. Likewise, MongoDB can
return arranged outcomes by utilizing the requesting in the file.
db.createCollections("movies")
create table for insert the data As a name of movies
db.createColection("rating")
create table for insert the data As a name of rating
{"comments":"" }
this index value show that define the comments field where value is emplty.
{"movieid": 1,"rating": 1,"comments": 1}
select All data to the dataset by this index it means fetch the value by this movieid, rating,
and comments terms
{"avg(rating)": 1}
Retrieve the average value of mathematics parts like rating
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

{"avgrating)": 1,"movieid": 1}
select All data to the dataset by this index it means fetch the value by this movieid,
avgrating field terms
{ oscarwon: 1 }
this index value show that define the oscaraward where its value will be atleast 1.
{ moviename: 1, oscarwon: 1, _id: 0 }
select All data to the dataset by this index it means fetch the value by this moviename,
oscarwon and objectID terms
count()
It’s a functions for database handling in mongoDB, like count the total number of the
movies
{ director: 1, moviename: 1, _id: 0 }
select All data to the dataset by this index it means fetch the value by this moviename,
directorname and objectID in terms of objectID
{ country: "japan" }
this index value show that define the country field where value is japan.
{ moviename: 1, country: 1, _id: 0 }
select All data to the dataset by this index it means fetch the value by this moviename,
countryname and objectID in terms of objectID
{ moviename: 1, _id: 0 }
select All data to the dataset by this index it means fetch the value by this moviename,
objectID in terms of objectID
Recommendations :
We concentrated on two useful Data for MongoDB in Excel sheet like Movies and rating of the
motion pictures. Both of these are genuinely regular utilize situations where MongoDB goes
about as an arrangement of record for a moderately static and clear gathering of information. For
instance, to some extent one of our arrangement where we concentrated on the Movie index, we
utilized MongoDB to store and recover a Movie information and its rating and both's variation
field.
select All data to the dataset by this index it means fetch the value by this movieid,
avgrating field terms
{ oscarwon: 1 }
this index value show that define the oscaraward where its value will be atleast 1.
{ moviename: 1, oscarwon: 1, _id: 0 }
select All data to the dataset by this index it means fetch the value by this moviename,
oscarwon and objectID terms
count()
It’s a functions for database handling in mongoDB, like count the total number of the
movies
{ director: 1, moviename: 1, _id: 0 }
select All data to the dataset by this index it means fetch the value by this moviename,
directorname and objectID in terms of objectID
{ country: "japan" }
this index value show that define the country field where value is japan.
{ moviename: 1, country: 1, _id: 0 }
select All data to the dataset by this index it means fetch the value by this moviename,
countryname and objectID in terms of objectID
{ moviename: 1, _id: 0 }
select All data to the dataset by this index it means fetch the value by this moviename,
objectID in terms of objectID
Recommendations :
We concentrated on two useful Data for MongoDB in Excel sheet like Movies and rating of the
motion pictures. Both of these are genuinely regular utilize situations where MongoDB goes
about as an arrangement of record for a moderately static and clear gathering of information. For
instance, to some extent one of our arrangement where we concentrated on the Movie index, we
utilized MongoDB to store and recover a Movie information and its rating and both's variation
field.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Today we'll be taking a gander at an altogether different use of MongoDB in the retail
space, one that even those comfortable with MongoDB probably won't think it is appropriate for:
logging a high volume of client movement information and performing information examination.
This last utilize case shows how MongoDB can empower adaptable bits of knowledge, including
proposals and personalization for your clients.
space, one that even those comfortable with MongoDB probably won't think it is appropriate for:
logging a high volume of client movement information and performing information examination.
This last utilize case shows how MongoDB can empower adaptable bits of knowledge, including
proposals and personalization for your clients.
1 out of 11
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.