COMP 3450 Lab Assignment 2: Parallel Matrix-Vector Product with MPI
VerifiedAdded on 2022/12/29
|8
|1472
|64
Practical Assignment
AI Summary
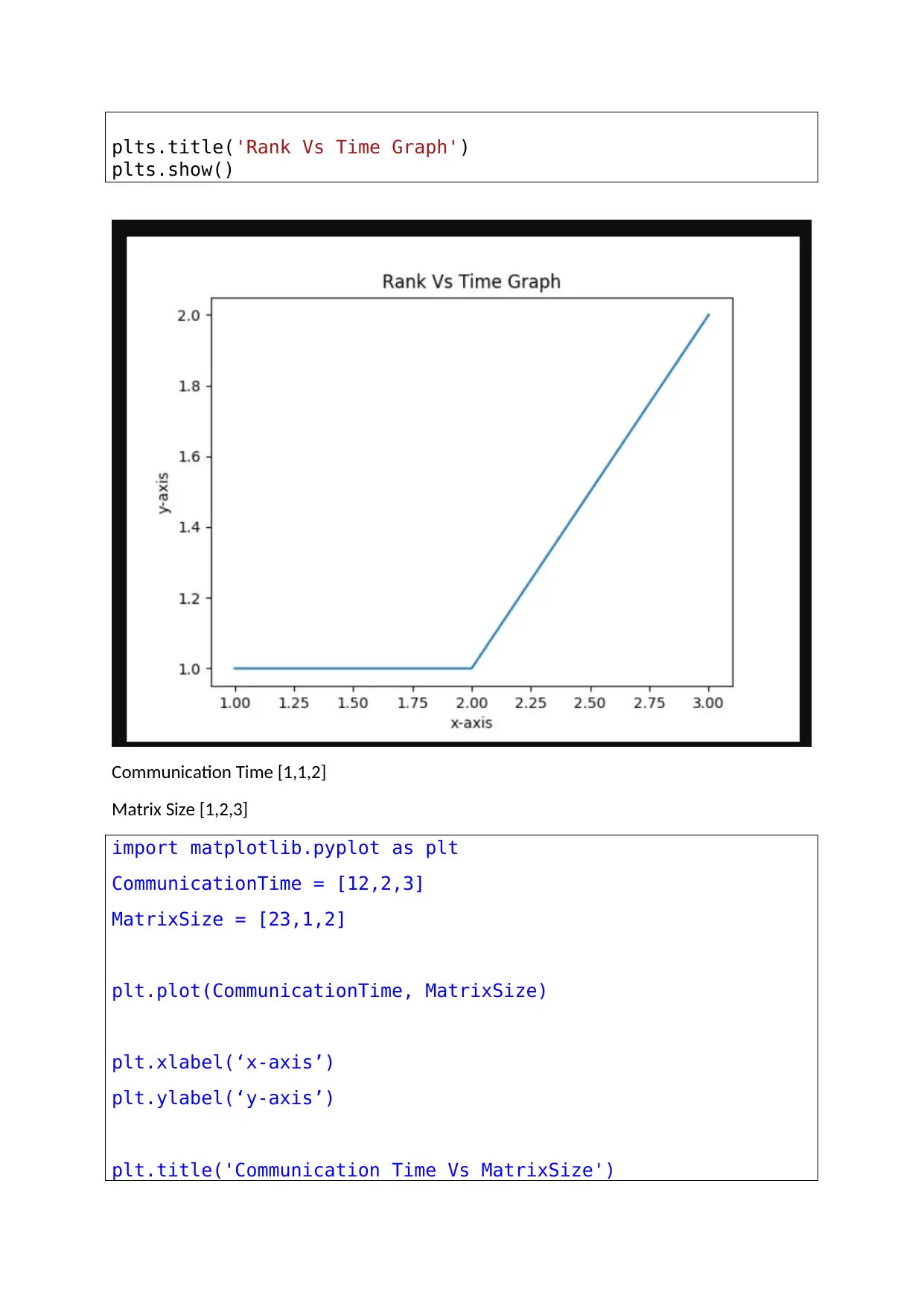
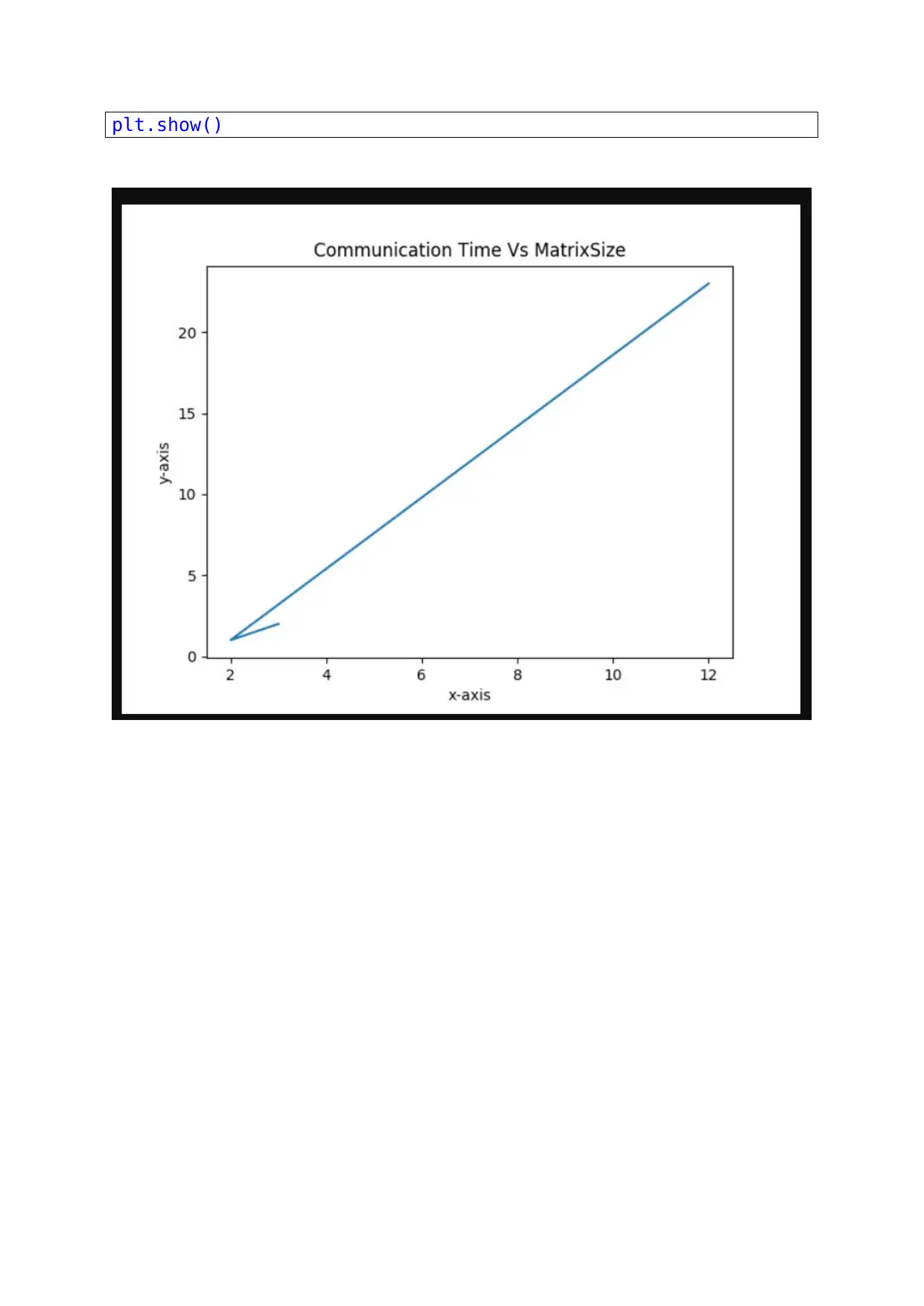
This assignment involves developing a C program to perform a parallel matrix-vector product using the Message Passing Interface (MPI). The solution begins by including necessary header files such as stdio.h and mpi.h, and then proceeds with initializing MPI and determining the rank and size of the communicator. The core functionality includes reading matrix and vector data from files, distributing matrix rows among processes using MPI_Scatterv, performing the matrix-vector multiplication, and gathering the results using MPI_Gatherv. The program includes timing analysis and graphical representations of performance metrics, comparing the time taken for the computation with different numbers of ranks and matrix sizes. The code also includes error handling for dimension mismatches and demonstrates the use of dynamic memory allocation for efficient handling of large matrices. The assignment aligns with the course requirements of COMP 3450 at Wentworth Institute of Technology, focusing on parallel and distributed computing concepts.






1 out of 8
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.