Excel Data Analysis: NBA Team Performance Prediction Project
VerifiedAdded on 2023/01/18
|5
|1360
|76
Project
AI Summary
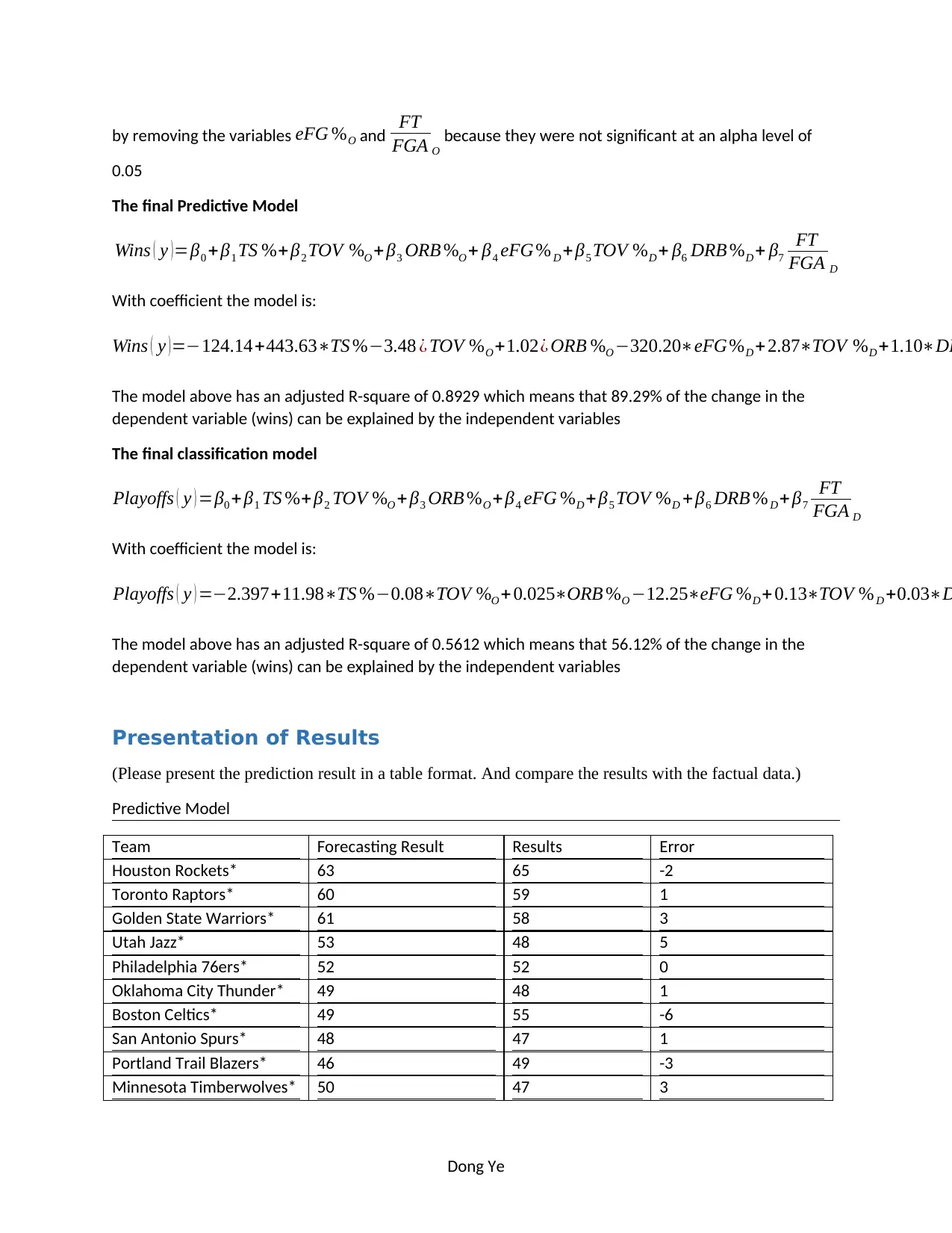
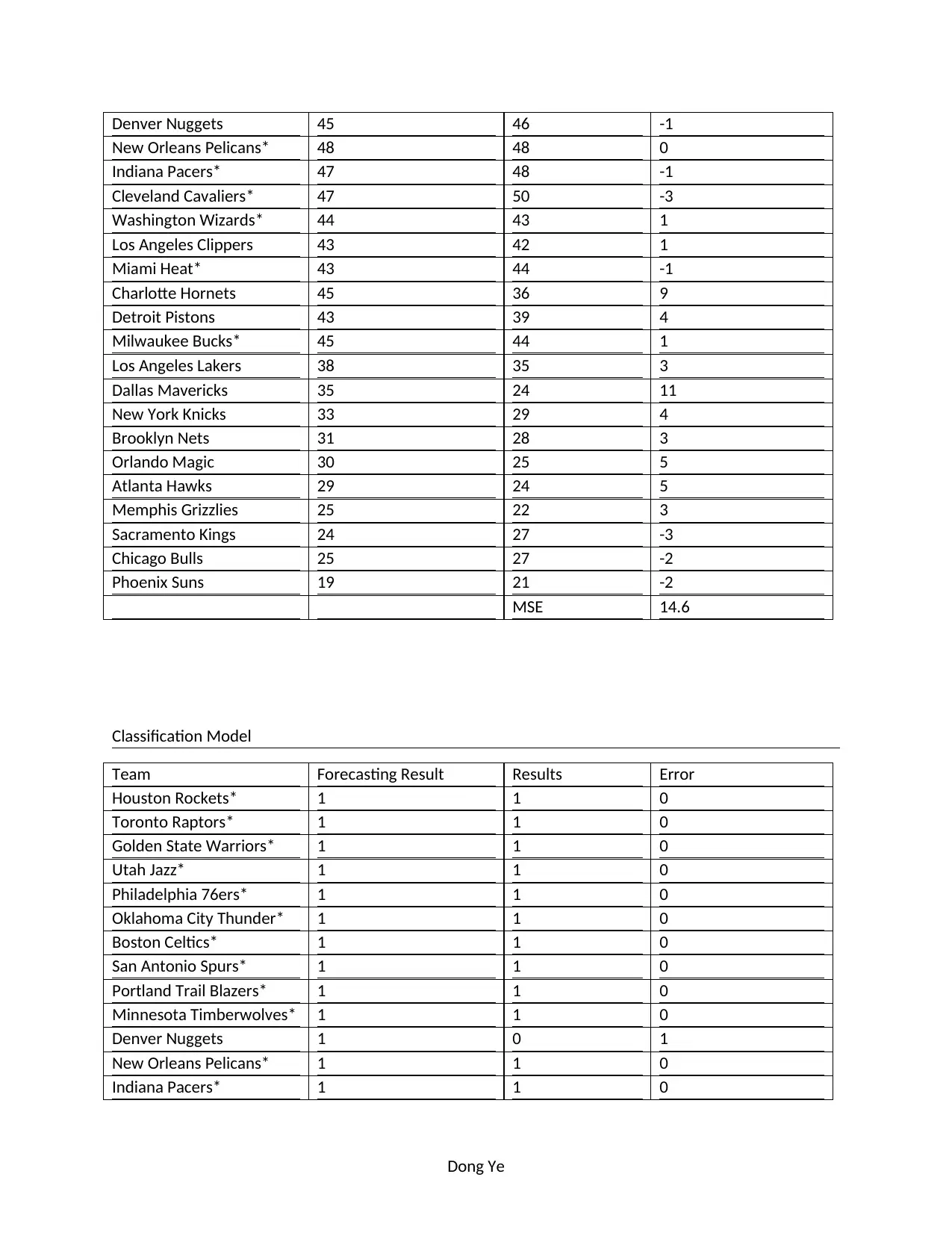
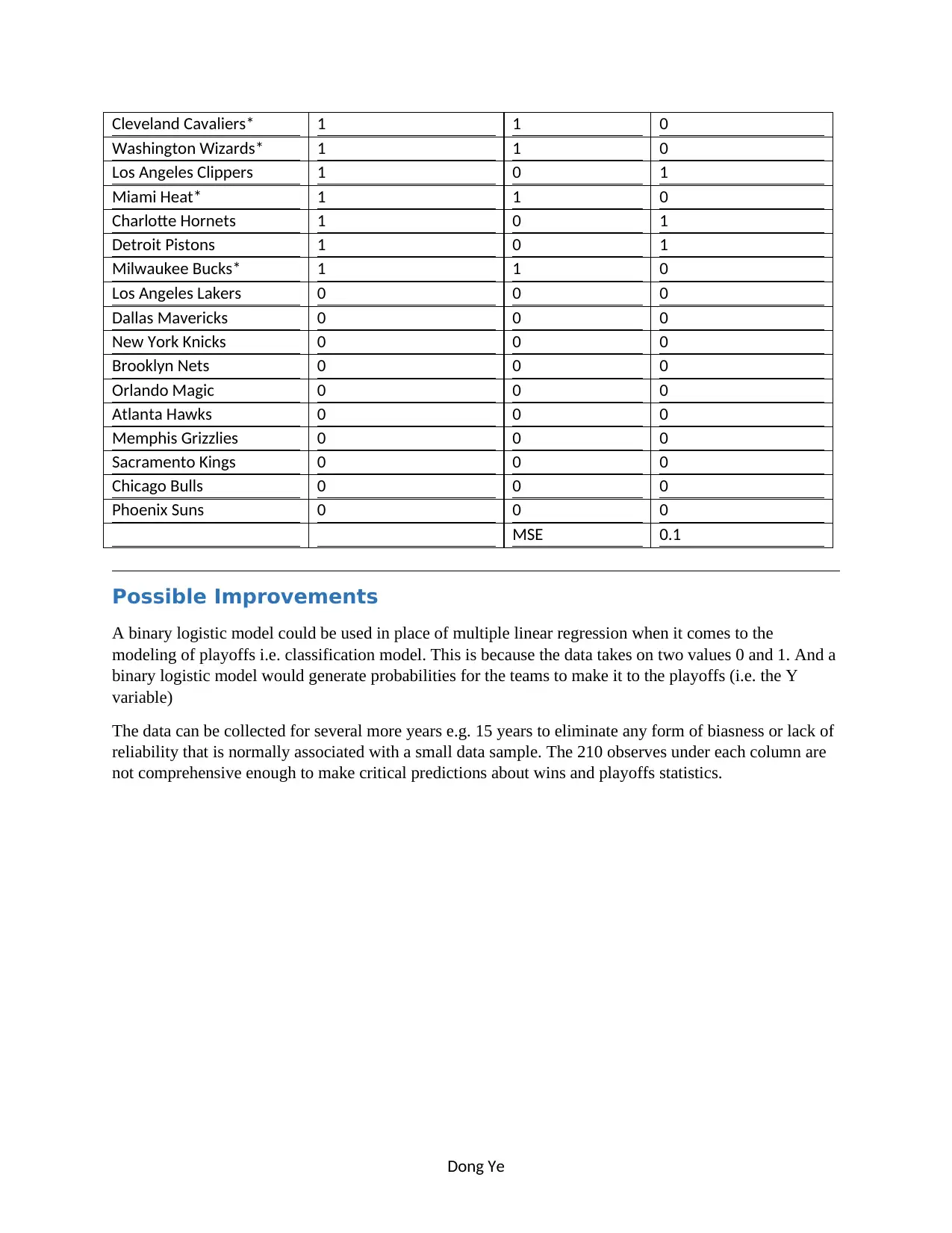
This project, prepared by Dong Ye for CMIS2250 at the Northern Alberta Institute of Technology, focuses on predicting NBA team performance. The project involves collecting and preparing data from 2010 to 2018, excluding 2017-2018 win-loss data, and building predictive and classification models using Excel. The process includes data cleaning, model selection (multiple linear regression), and result presentation, including a comparison of forecasted and actual results. The final models predict wins and playoff participation based on various offensive, defensive, and efficiency statistics. The project also includes a discussion of potential improvements, such as using a binary logistic model and expanding the data sample. The project demonstrates the application of data analysis techniques to forecast real-world outcomes.


1 out of 5


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.