NIT6130 - Cloud Computing: Experiment Design & Result Analysis
VerifiedAdded on 2023/06/04
|14
|2733
|200
Report
AI Summary
This report details the experiment design and result analysis conducted to evaluate methodologies for enhancing privacy and security in cloud computing, based on a previous assignment. The process includes data collection from organizations using cloud services, data pre-processing, feature selection, experiment design using qualitative methodology, and implementation using appropriate software and tools. The research aimed to improve data security measures by modifying existing cloud computing techniques to address challenges such as data breaches and malware. The expected results included enhanced data control and management, ultimately leading to improved organizational performance through better data protection schemes. The report also includes tables for data collection, storage, feature selection, and experiment design, providing a comprehensive overview of the research process and expected outcomes.

1
Introduction to Research
Student’s Name
Course
Professor’s Name
Institution’s Name
Institution’s Location
Date
Introduction to Research
Student’s Name
Course
Professor’s Name
Institution’s Name
Institution’s Location
Date
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

2
1.0 Assignment 4 – Experiment Design & Result Analysis
1.1 The main objective
The major objective of our paper is to help us to become familiar with the research or
experimental processes. We conduct different types of researches or experiments in our lives,
and therefore, this paper will be very important us it will enhance our understanding on how we
can conduct these researches or experiments effectively (Babbie, 2015). This paper will be based
on the previous assignment which discussed privacy and security in cloud computing. As we
know, for effective storage, management, and processing of data in cloud computing, the privacy
and the security of the data must be highly considered and given the required attention to avoid
leakage of the data to the unauthorized persons who can access the data and end up interfering
with or messing the entire network system for their personal gains (Hauer, 2015, pp.2554-2565).
To achieve our objective in this paper, we shall do a detailed review, conduct an analysis, do a
design, and finally implement experiments which will help us to evaluate the methodology in the
previous in the previous assignment, and thus report the findings and the results of the previous
experiment.
1.2 Data collection
1.2.1 Data sources
There are various sources where we shall collect the data required in our research. These
sources will be organizations involved in various operations and use cloud computing in their
1.0 Assignment 4 – Experiment Design & Result Analysis
1.1 The main objective
The major objective of our paper is to help us to become familiar with the research or
experimental processes. We conduct different types of researches or experiments in our lives,
and therefore, this paper will be very important us it will enhance our understanding on how we
can conduct these researches or experiments effectively (Babbie, 2015). This paper will be based
on the previous assignment which discussed privacy and security in cloud computing. As we
know, for effective storage, management, and processing of data in cloud computing, the privacy
and the security of the data must be highly considered and given the required attention to avoid
leakage of the data to the unauthorized persons who can access the data and end up interfering
with or messing the entire network system for their personal gains (Hauer, 2015, pp.2554-2565).
To achieve our objective in this paper, we shall do a detailed review, conduct an analysis, do a
design, and finally implement experiments which will help us to evaluate the methodology in the
previous in the previous assignment, and thus report the findings and the results of the previous
experiment.
1.2 Data collection
1.2.1 Data sources
There are various sources where we shall collect the data required in our research. These
sources will be organizations involved in various operations and use cloud computing in their

3
operations. As we know, cloud computing is a technique which involves using a large network of
some remote servers which are normally hosted over the internet for them to store, to manage,
and to process data, rather than using the local servers or some personal computers for storing,
managing, and processing the data (Rittinghouse and Ransome, 2016). Therefore, the
organizations which use cloud computing technology in their operations will be suitable sources
of data for our research. In our case, we shall visit three organizations which have cloud
computing services in their operations. These organizations will be a systems maintenance
organization, a computer producing/selling organization, and a sports organization. All these
three organization deal with bulk amounts of data and have cloud computing departments which
are concerned with the privacy and the security of their data.
1.2.2 Data collection record
After collecting our desired data in the sources discussed above, we shall record the data
in a table which will enhance its presentation and its security (Sun et al., 2014, pp.3601-3604).
The table will also give more descriptions of the data which is very important especially to the
people who might need to use our report in the future. The data collected will be stored in the
sample table shown below:
1.2.2.1 Data collection table
Data
source
name
Source
organization
Data description File
data
format
URL (if
available
online)
Charge
fee
Target
data
source
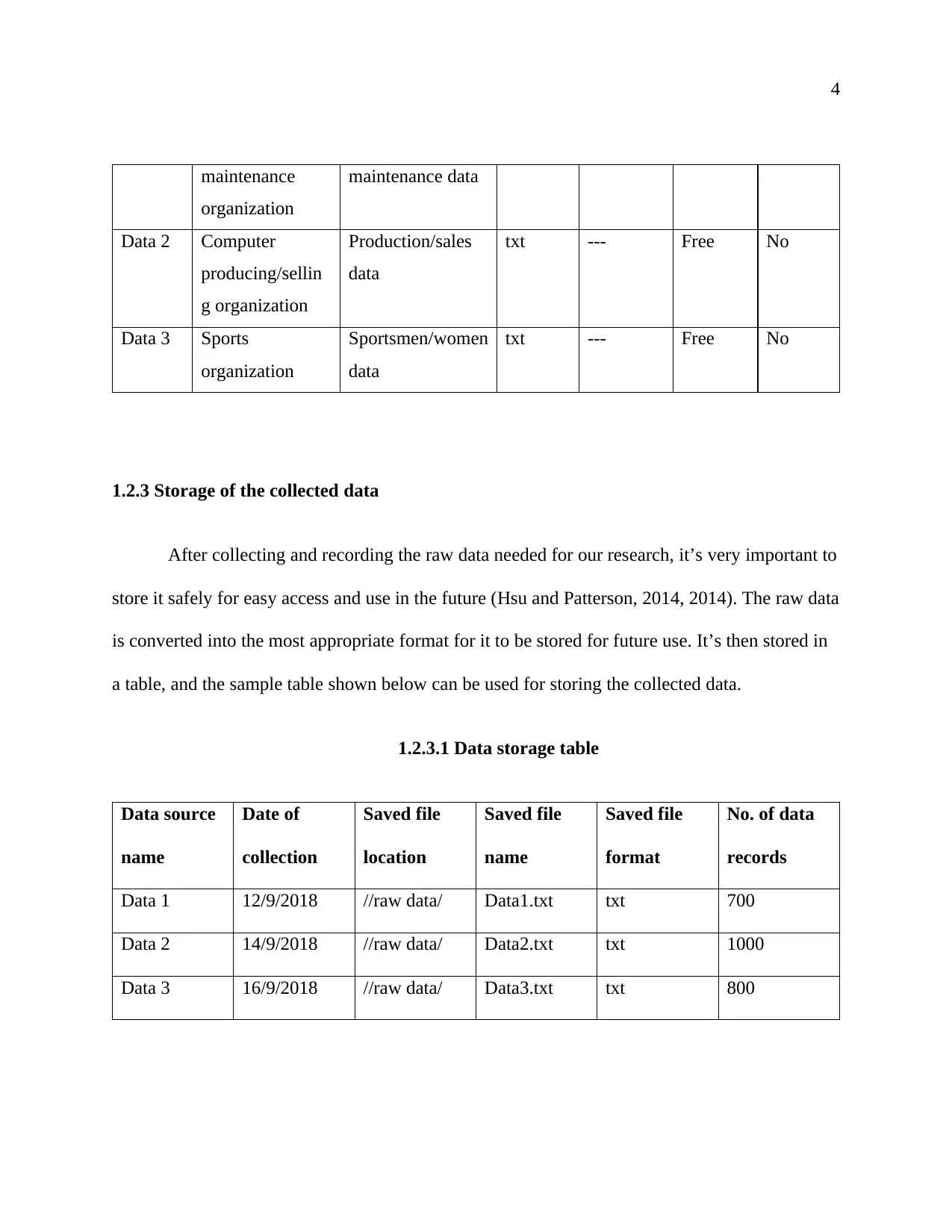
Data 1 Systems Systems txt --- Free No
operations. As we know, cloud computing is a technique which involves using a large network of
some remote servers which are normally hosted over the internet for them to store, to manage,
and to process data, rather than using the local servers or some personal computers for storing,
managing, and processing the data (Rittinghouse and Ransome, 2016). Therefore, the
organizations which use cloud computing technology in their operations will be suitable sources
of data for our research. In our case, we shall visit three organizations which have cloud
computing services in their operations. These organizations will be a systems maintenance
organization, a computer producing/selling organization, and a sports organization. All these
three organization deal with bulk amounts of data and have cloud computing departments which
are concerned with the privacy and the security of their data.
1.2.2 Data collection record
After collecting our desired data in the sources discussed above, we shall record the data
in a table which will enhance its presentation and its security (Sun et al., 2014, pp.3601-3604).
The table will also give more descriptions of the data which is very important especially to the
people who might need to use our report in the future. The data collected will be stored in the
sample table shown below:
1.2.2.1 Data collection table
Data
source
name
Source
organization
Data description File
data
format
URL (if
available
online)
Charge
fee
Target
data
source
Data 1 Systems Systems txt --- Free No
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
4
maintenance
organization
maintenance data
Data 2 Computer
producing/sellin
g organization
Production/sales
data
txt --- Free No
Data 3 Sports
organization
Sportsmen/women
data
txt --- Free No
1.2.3 Storage of the collected data
After collecting and recording the raw data needed for our research, it’s very important to
store it safely for easy access and use in the future (Hsu and Patterson, 2014, 2014). The raw data
is converted into the most appropriate format for it to be stored for future use. It’s then stored in
a table, and the sample table shown below can be used for storing the collected data.
1.2.3.1 Data storage table
Data source
name
Date of
collection
Saved file
location
Saved file
name
Saved file
format
No. of data
records
Data 1 12/9/2018 //raw data/ Data1.txt txt 700
Data 2 14/9/2018 //raw data/ Data2.txt txt 1000
Data 3 16/9/2018 //raw data/ Data3.txt txt 800
maintenance
organization
maintenance data
Data 2 Computer
producing/sellin
g organization
Production/sales
data
txt --- Free No
Data 3 Sports
organization
Sportsmen/women
data
txt --- Free No
1.2.3 Storage of the collected data
After collecting and recording the raw data needed for our research, it’s very important to
store it safely for easy access and use in the future (Hsu and Patterson, 2014, 2014). The raw data
is converted into the most appropriate format for it to be stored for future use. It’s then stored in
a table, and the sample table shown below can be used for storing the collected data.
1.2.3.1 Data storage table
Data source
name
Date of
collection
Saved file
location
Saved file
name
Saved file
format
No. of data
records
Data 1 12/9/2018 //raw data/ Data1.txt txt 700
Data 2 14/9/2018 //raw data/ Data2.txt txt 1000
Data 3 16/9/2018 //raw data/ Data3.txt txt 800
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

5
1.3 Experiment design and implementation
1.3.1 Data pre-processing
After collecting any raw data to be used in an experiment or research, it’s good to do
some pre-processing of the data, but it can be used in the experiment. In data pre-processing, the
collected raw data is modified and transformed into the appropriate formats which are required in
the experiment (García, Ramírez-Gallego, Luengo, Benítez, and Herrera, 2016, pp.9-11). There
are several common data pre-processing techniques which are used in modifying and
transforming the data into the required format. Some of the most common data pre-processing
techniques include data cleaning, data integration, data reduction, and data transformation (Zhao,
Wang, and Sheng, 2018, pp.13-52). Data cleaning is done to remove noise and inconsistency in
the raw data. Data reduction is done to remove redundancy and the unwanted data from the
collected raw data. Data integration is done to combine the data from several sources to come up
with a coherent and reasonable data which can be used together in the experiment (Gomez-
Cabrero et al., 2014). Lastly, data transformation is the last step in data pre-processing and is
done to transform the collected data to the final and the most appropriate format which will be
used in the experiment or research (Heer, Hellerstein, and Kandel, 2015). Good and effective
data pre-processing is very important in experiments or research as it simplifies the process of
data analysis.
1.3 Experiment design and implementation
1.3.1 Data pre-processing
After collecting any raw data to be used in an experiment or research, it’s good to do
some pre-processing of the data, but it can be used in the experiment. In data pre-processing, the
collected raw data is modified and transformed into the appropriate formats which are required in
the experiment (García, Ramírez-Gallego, Luengo, Benítez, and Herrera, 2016, pp.9-11). There
are several common data pre-processing techniques which are used in modifying and
transforming the data into the required format. Some of the most common data pre-processing
techniques include data cleaning, data integration, data reduction, and data transformation (Zhao,
Wang, and Sheng, 2018, pp.13-52). Data cleaning is done to remove noise and inconsistency in
the raw data. Data reduction is done to remove redundancy and the unwanted data from the
collected raw data. Data integration is done to combine the data from several sources to come up
with a coherent and reasonable data which can be used together in the experiment (Gomez-
Cabrero et al., 2014). Lastly, data transformation is the last step in data pre-processing and is
done to transform the collected data to the final and the most appropriate format which will be
used in the experiment or research (Heer, Hellerstein, and Kandel, 2015). Good and effective
data pre-processing is very important in experiments or research as it simplifies the process of
data analysis.
6
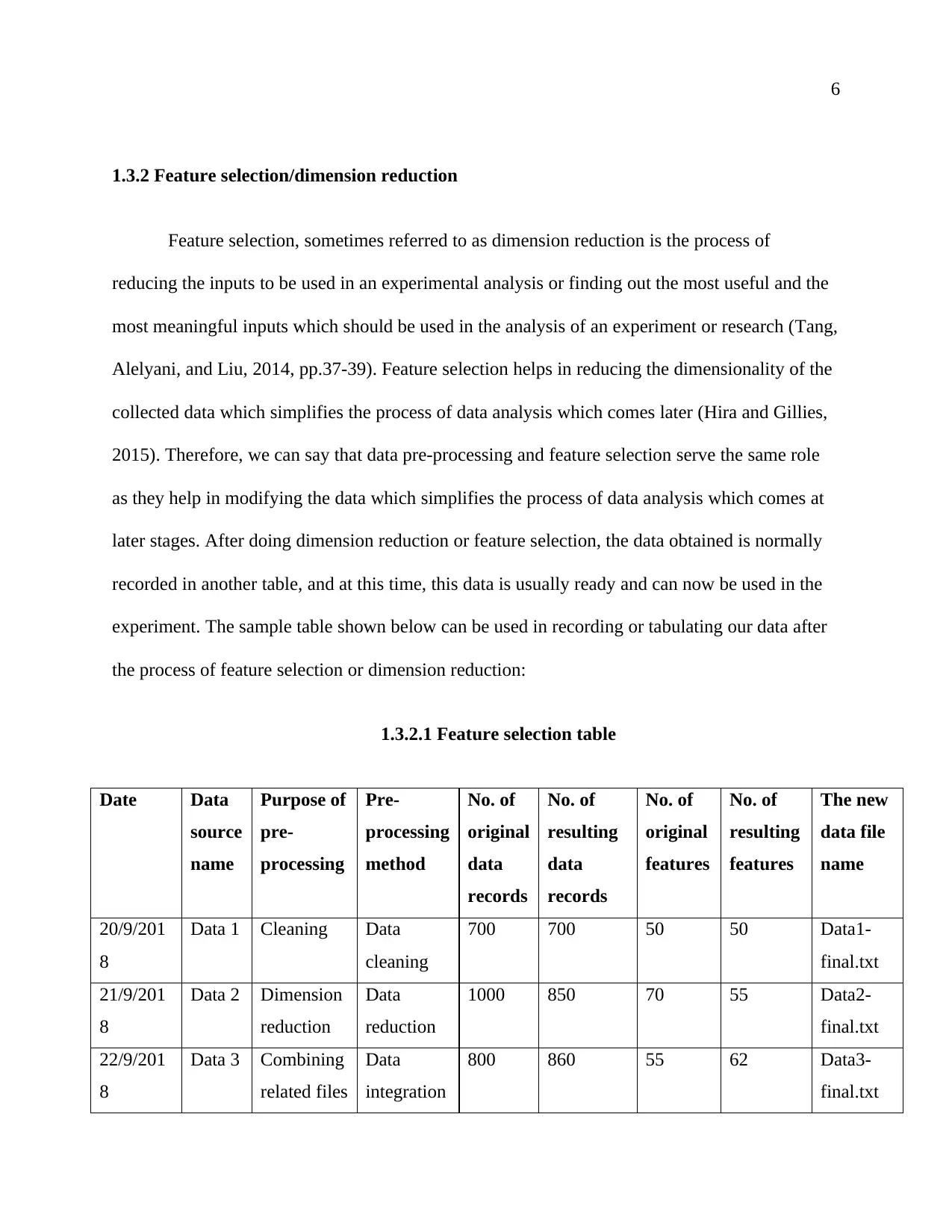
1.3.2 Feature selection/dimension reduction
Feature selection, sometimes referred to as dimension reduction is the process of
reducing the inputs to be used in an experimental analysis or finding out the most useful and the
most meaningful inputs which should be used in the analysis of an experiment or research (Tang,
Alelyani, and Liu, 2014, pp.37-39). Feature selection helps in reducing the dimensionality of the
collected data which simplifies the process of data analysis which comes later (Hira and Gillies,
2015). Therefore, we can say that data pre-processing and feature selection serve the same role
as they help in modifying the data which simplifies the process of data analysis which comes at
later stages. After doing dimension reduction or feature selection, the data obtained is normally
recorded in another table, and at this time, this data is usually ready and can now be used in the
experiment. The sample table shown below can be used in recording or tabulating our data after
the process of feature selection or dimension reduction:
1.3.2.1 Feature selection table
Date Data
source
name
Purpose of
pre-
processing
Pre-
processing
method
No. of
original
data
records
No. of
resulting
data
records
No. of
original
features
No. of
resulting
features
The new
data file
name
20/9/201
8
Data 1 Cleaning Data
cleaning
700 700 50 50 Data1-
final.txt
21/9/201
8
Data 2 Dimension
reduction
Data
reduction
1000 850 70 55 Data2-
final.txt
22/9/201
8
Data 3 Combining
related files
Data
integration
800 860 55 62 Data3-
final.txt
1.3.2 Feature selection/dimension reduction
Feature selection, sometimes referred to as dimension reduction is the process of
reducing the inputs to be used in an experimental analysis or finding out the most useful and the
most meaningful inputs which should be used in the analysis of an experiment or research (Tang,
Alelyani, and Liu, 2014, pp.37-39). Feature selection helps in reducing the dimensionality of the
collected data which simplifies the process of data analysis which comes later (Hira and Gillies,
2015). Therefore, we can say that data pre-processing and feature selection serve the same role
as they help in modifying the data which simplifies the process of data analysis which comes at
later stages. After doing dimension reduction or feature selection, the data obtained is normally
recorded in another table, and at this time, this data is usually ready and can now be used in the
experiment. The sample table shown below can be used in recording or tabulating our data after
the process of feature selection or dimension reduction:
1.3.2.1 Feature selection table
Date Data
source
name
Purpose of
pre-
processing
Pre-
processing
method
No. of
original
data
records
No. of
resulting
data
records
No. of
original
features
No. of
resulting
features
The new
data file
name
20/9/201
8
Data 1 Cleaning Data
cleaning
700 700 50 50 Data1-
final.txt
21/9/201
8
Data 2 Dimension
reduction
Data
reduction
1000 850 70 55 Data2-
final.txt
22/9/201
8
Data 3 Combining
related files
Data
integration
800 860 55 62 Data3-
final.txt
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
7
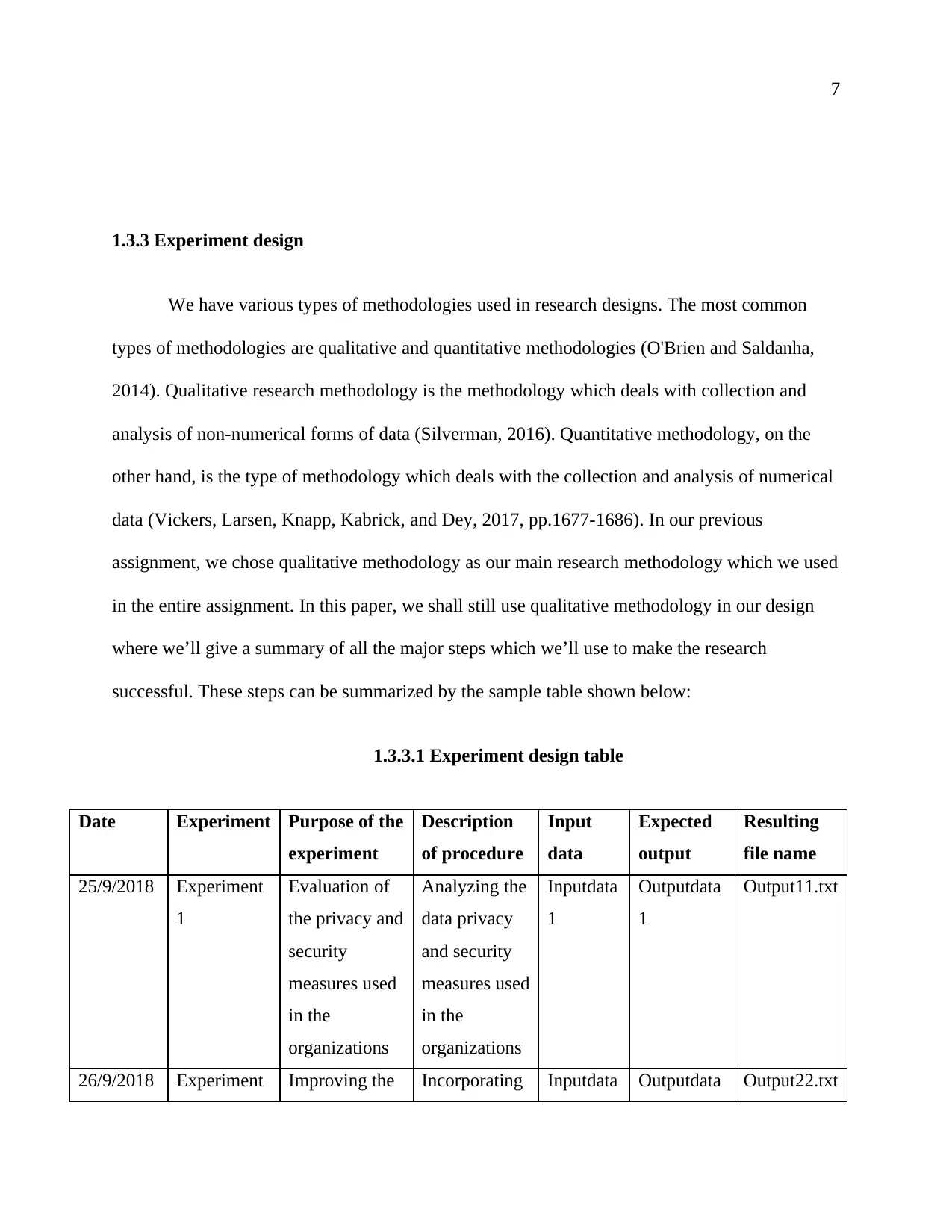
1.3.3 Experiment design
We have various types of methodologies used in research designs. The most common
types of methodologies are qualitative and quantitative methodologies (O'Brien and Saldanha,
2014). Qualitative research methodology is the methodology which deals with collection and
analysis of non-numerical forms of data (Silverman, 2016). Quantitative methodology, on the
other hand, is the type of methodology which deals with the collection and analysis of numerical
data (Vickers, Larsen, Knapp, Kabrick, and Dey, 2017, pp.1677-1686). In our previous
assignment, we chose qualitative methodology as our main research methodology which we used
in the entire assignment. In this paper, we shall still use qualitative methodology in our design
where we’ll give a summary of all the major steps which we’ll use to make the research
successful. These steps can be summarized by the sample table shown below:
1.3.3.1 Experiment design table
Date Experiment Purpose of the
experiment
Description
of procedure
Input
data
Expected
output
Resulting
file name
25/9/2018 Experiment
1
Evaluation of
the privacy and
security
measures used
in the
organizations
Analyzing the
data privacy
and security
measures used
in the
organizations
Inputdata
1
Outputdata
1
Output11.txt
26/9/2018 Experiment Improving the Incorporating Inputdata Outputdata Output22.txt
1.3.3 Experiment design
We have various types of methodologies used in research designs. The most common
types of methodologies are qualitative and quantitative methodologies (O'Brien and Saldanha,
2014). Qualitative research methodology is the methodology which deals with collection and
analysis of non-numerical forms of data (Silverman, 2016). Quantitative methodology, on the
other hand, is the type of methodology which deals with the collection and analysis of numerical
data (Vickers, Larsen, Knapp, Kabrick, and Dey, 2017, pp.1677-1686). In our previous
assignment, we chose qualitative methodology as our main research methodology which we used
in the entire assignment. In this paper, we shall still use qualitative methodology in our design
where we’ll give a summary of all the major steps which we’ll use to make the research
successful. These steps can be summarized by the sample table shown below:
1.3.3.1 Experiment design table
Date Experiment Purpose of the
experiment
Description
of procedure
Input
data
Expected
output
Resulting
file name
25/9/2018 Experiment
1
Evaluation of
the privacy and
security
measures used
in the
organizations
Analyzing the
data privacy
and security
measures used
in the
organizations
Inputdata
1
Outputdata
1
Output11.txt
26/9/2018 Experiment Improving the Incorporating Inputdata Outputdata Output22.txt
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

8
2 privacy and
security of the
data in the
organizations
better and
more secure
techniques of
data
protection
2 2
1.3.4 Experiment implementation
To effectively implement our research or experiment, we used the appropriate software
and tools in the analysis of the collected information. Some tables and graphs were used to
tabulate the results obtained after analyzing the collected data (Chambers, 2017). In this case, the
research was dealing with the analysis of the cloud computing techniques used to enhance the
privacy and the security of the data in our three organizations of our concern. To implement our
research, we first analyzed and sorted the major privacy and security issues which were affecting
the cloud computing techniques used by the organizations. We found that the main cloud
computing used by these organizations were highly affected by many security challenges where
the main challenges which affected these techniques included data breaches, account hijacking,
malware addition, and internal threats. After analyzing the major challenges which affected the
cloud computing techniques used in the organizations, we were able to make good modifications
to the existing cloud computing techniques and came up with some other better techniques which
helped to address the major challenges which faced the previous techniques. So, we can say that
our research or experiment implementation was successful since we were able to modify the
existing cloud computing techniques and came up with other better techniques which helped to
2 privacy and
security of the
data in the
organizations
better and
more secure
techniques of
data
protection
2 2
1.3.4 Experiment implementation
To effectively implement our research or experiment, we used the appropriate software
and tools in the analysis of the collected information. Some tables and graphs were used to
tabulate the results obtained after analyzing the collected data (Chambers, 2017). In this case, the
research was dealing with the analysis of the cloud computing techniques used to enhance the
privacy and the security of the data in our three organizations of our concern. To implement our
research, we first analyzed and sorted the major privacy and security issues which were affecting
the cloud computing techniques used by the organizations. We found that the main cloud
computing used by these organizations were highly affected by many security challenges where
the main challenges which affected these techniques included data breaches, account hijacking,
malware addition, and internal threats. After analyzing the major challenges which affected the
cloud computing techniques used in the organizations, we were able to make good modifications
to the existing cloud computing techniques and came up with some other better techniques which
helped to address the major challenges which faced the previous techniques. So, we can say that
our research or experiment implementation was successful since we were able to modify the
existing cloud computing techniques and came up with other better techniques which helped to

9
solve many of the security challenges which faced the previous cloud computing techniques used
in the organizations.
1.4 Experiment result analysis and summary
1.4.1 The expected results
Our experiment was aimed at improving the privacy and the security of the private data
of the organizations of our research. All the organizations should always be very careful about
the security of their data. Many organizations have ended up in great losses due to leakage of
their private data to the unauthorized malicious people who end up harming the organizations for
their own gains. To avoid experiencing such cases, organizations must make sure they are
equipped with the best and the strongest data protection techniques which won’t in any way
allow the private data of the organizations to leak to the unauthorized people operating in or out
of the organizations (Mehmood, Natgunanathan, Xiang, Hua, and Guo, 2016, pp.1821-1834).
When doing our research, we aimed at improving the privacy and the security of the
organizations’ data by coming up with modified and other better cloud computing and protection
techniques which would help to enhance the security of the data of these organizations. The
results expected from the research were improved security measures which could mean that the
organizations would have better control and management of their data which could improve their
overall performance. The performance of organizations is usually dependent on how the
organizations control and manage their data to harness the best from the data.
solve many of the security challenges which faced the previous cloud computing techniques used
in the organizations.
1.4 Experiment result analysis and summary
1.4.1 The expected results
Our experiment was aimed at improving the privacy and the security of the private data
of the organizations of our research. All the organizations should always be very careful about
the security of their data. Many organizations have ended up in great losses due to leakage of
their private data to the unauthorized malicious people who end up harming the organizations for
their own gains. To avoid experiencing such cases, organizations must make sure they are
equipped with the best and the strongest data protection techniques which won’t in any way
allow the private data of the organizations to leak to the unauthorized people operating in or out
of the organizations (Mehmood, Natgunanathan, Xiang, Hua, and Guo, 2016, pp.1821-1834).
When doing our research, we aimed at improving the privacy and the security of the
organizations’ data by coming up with modified and other better cloud computing and protection
techniques which would help to enhance the security of the data of these organizations. The
results expected from the research were improved security measures which could mean that the
organizations would have better control and management of their data which could improve their
overall performance. The performance of organizations is usually dependent on how the
organizations control and manage their data to harness the best from the data.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

10
1.4.2 The summary of the expected results
As already stated above, the results expected from our research were improved data
security measures which could help the organizations to have good control and management of
their data. Our research question sought to address how the security of organizations’ data can be
improved by using cloud computing techniques and other useful data protection schemes. The
results expected in our research are relevant and helps to address the research question
effectively as they aim to improve the security of the organizations’ data which will
consequently improve the overall performance of organizations as discussed above.
1.4.2 The summary of the expected results
As already stated above, the results expected from our research were improved data
security measures which could help the organizations to have good control and management of
their data. Our research question sought to address how the security of organizations’ data can be
improved by using cloud computing techniques and other useful data protection schemes. The
results expected in our research are relevant and helps to address the research question
effectively as they aim to improve the security of the organizations’ data which will
consequently improve the overall performance of organizations as discussed above.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

11
Outline of experiment and result analysis chapter
1.0 Assignment 4 – Experiment Design & Result Analysis............................................................2
1.1 The main objective.......................................................................................................2
1.2 Data collection.............................................................................................................2
1.2.1 Data sources..........................................................................................................2
1.2.2 Data collection record...........................................................................................3
1.2.3 Storage of the collected data.................................................................................4
1.3 Experiment design and implementation.......................................................................5
1.3.1 Data pre-processing...............................................................................................5
1.3.2 Feature selection/dimension reduction..................................................................5
1.3.3 Experiment design.................................................................................................6
1.3.4 Experiment implementation..................................................................................8
1.4 Experiment result analysis and summary.....................................................................9
Outline of experiment and result analysis chapter
1.0 Assignment 4 – Experiment Design & Result Analysis............................................................2
1.1 The main objective.......................................................................................................2
1.2 Data collection.............................................................................................................2
1.2.1 Data sources..........................................................................................................2
1.2.2 Data collection record...........................................................................................3
1.2.3 Storage of the collected data.................................................................................4
1.3 Experiment design and implementation.......................................................................5
1.3.1 Data pre-processing...............................................................................................5
1.3.2 Feature selection/dimension reduction..................................................................5
1.3.3 Experiment design.................................................................................................6
1.3.4 Experiment implementation..................................................................................8
1.4 Experiment result analysis and summary.....................................................................9

12
1.4.1 The expected results..............................................................................................9
1.4.2 The summary of the expected results....................................................................9
References
Babbie, E.R., 2015. The practice of social research. Nelson Education.
Chambers, J.M., 2017. Graphical Methods for Data Analysis: 0. Chapman and Hall/CRC.
García, S., Ramírez-Gallego, S., Luengo, J., Benítez, J.M. and Herrera, F., 2016. Big data
preprocessing: methods and prospects. Big Data Analytics, 1(1), pp.9-11.
Gomez-Cabrero, D., Abugessaisa, I., Maier, D., Teschendorff, A., Merkenschlager, M., Gisel,
A., Ballestar, E., Bongcam-Rudloff, E., Conesa, A. and Tegnér, J., 2014. Data integration in the
era of omics: current and future challenges.
Hauer, B., 2015. Data and information leakage prevention within the scope of information
security. IEEE Access, 3 (1), pp.2554-2565.
Heer, J., Hellerstein, J.M. and Kandel, S., 2015. Predictive Interaction for Data Transformation.
In CIDR.
1.4.1 The expected results..............................................................................................9
1.4.2 The summary of the expected results....................................................................9
References
Babbie, E.R., 2015. The practice of social research. Nelson Education.
Chambers, J.M., 2017. Graphical Methods for Data Analysis: 0. Chapman and Hall/CRC.
García, S., Ramírez-Gallego, S., Luengo, J., Benítez, J.M. and Herrera, F., 2016. Big data
preprocessing: methods and prospects. Big Data Analytics, 1(1), pp.9-11.
Gomez-Cabrero, D., Abugessaisa, I., Maier, D., Teschendorff, A., Merkenschlager, M., Gisel,
A., Ballestar, E., Bongcam-Rudloff, E., Conesa, A. and Tegnér, J., 2014. Data integration in the
era of omics: current and future challenges.
Hauer, B., 2015. Data and information leakage prevention within the scope of information
security. IEEE Access, 3 (1), pp.2554-2565.
Heer, J., Hellerstein, J.M. and Kandel, S., 2015. Predictive Interaction for Data Transformation.
In CIDR.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 14
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.