A Study on Text Classification Using Naïve Bayes in Natural Language
VerifiedAdded on 2023/04/22
|15
|1230
|324
Report
AI Summary
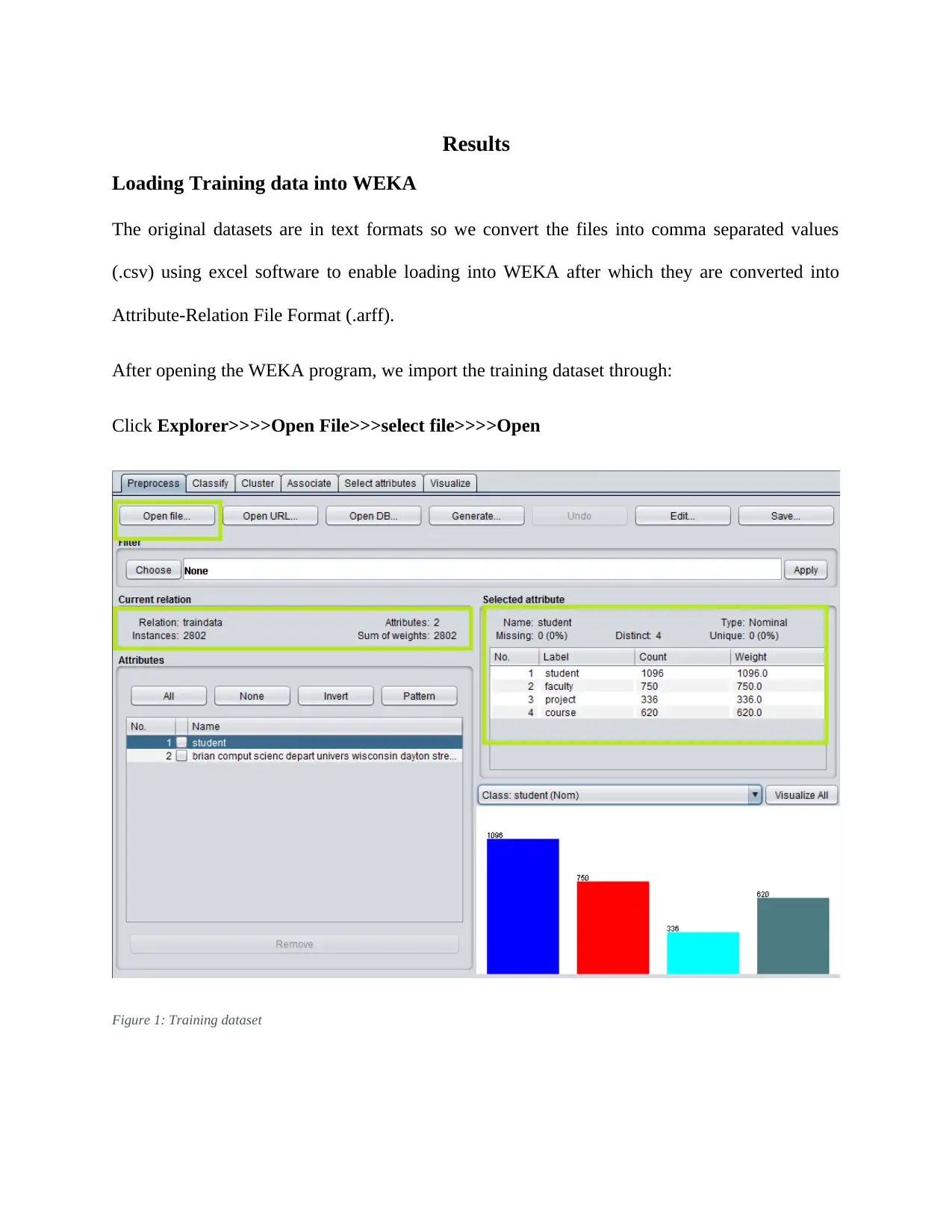
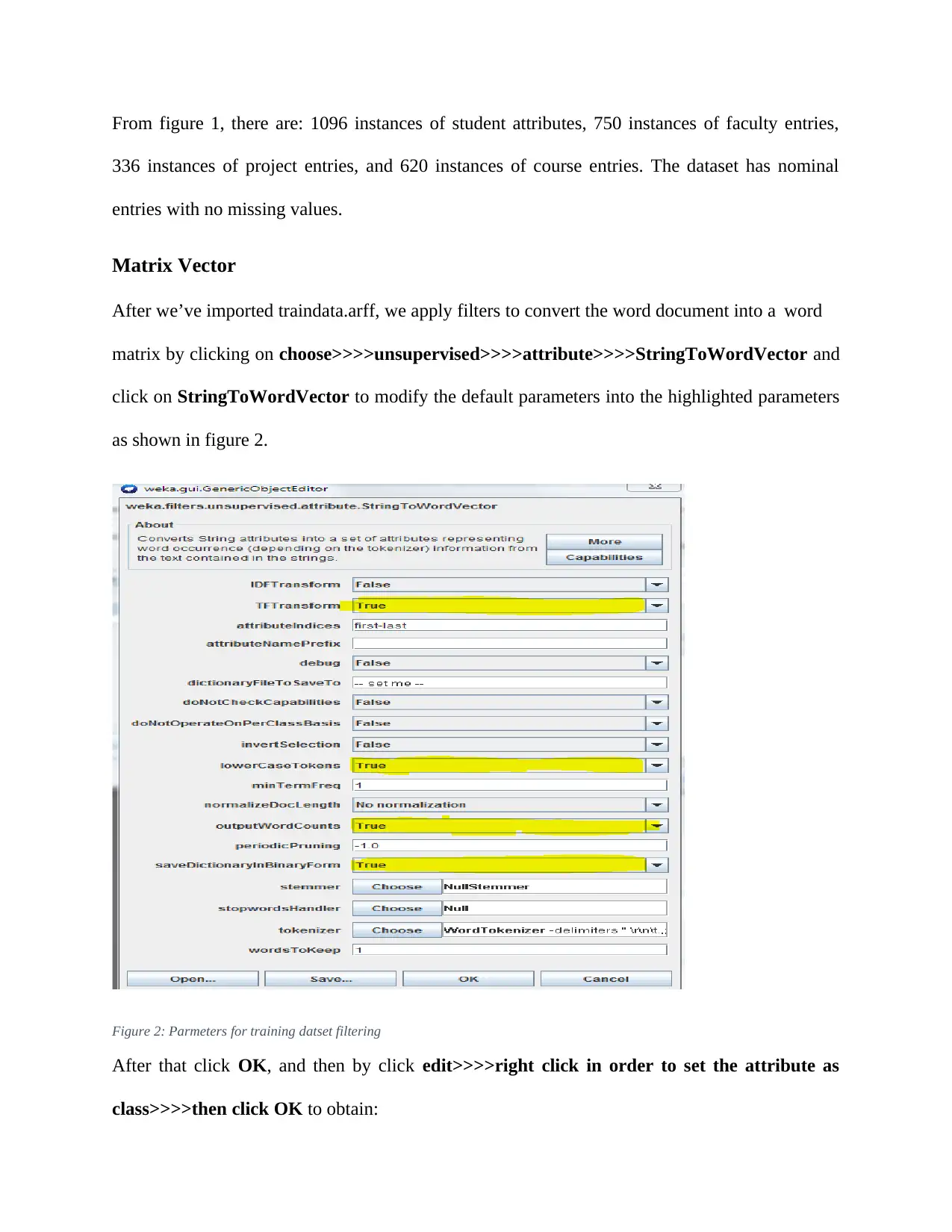
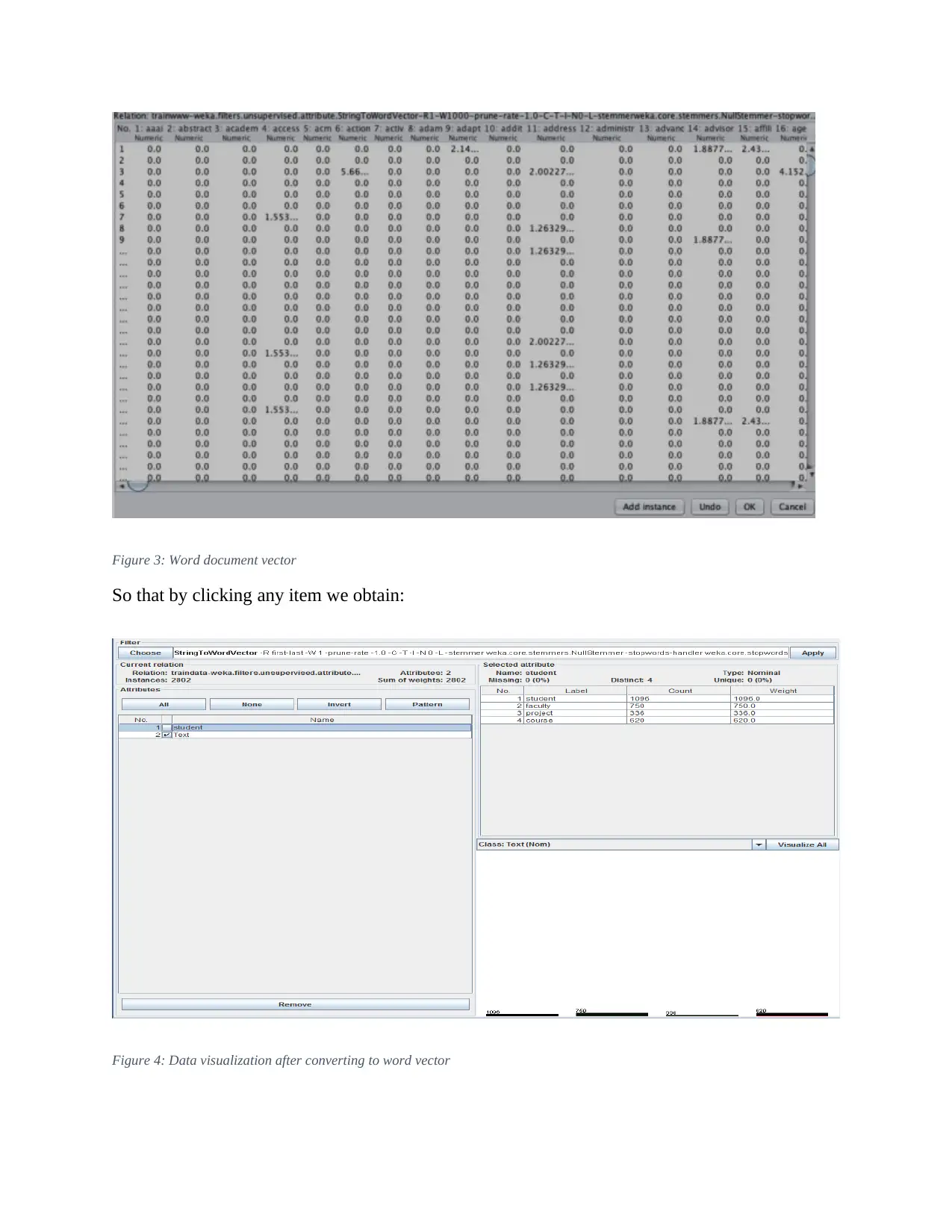
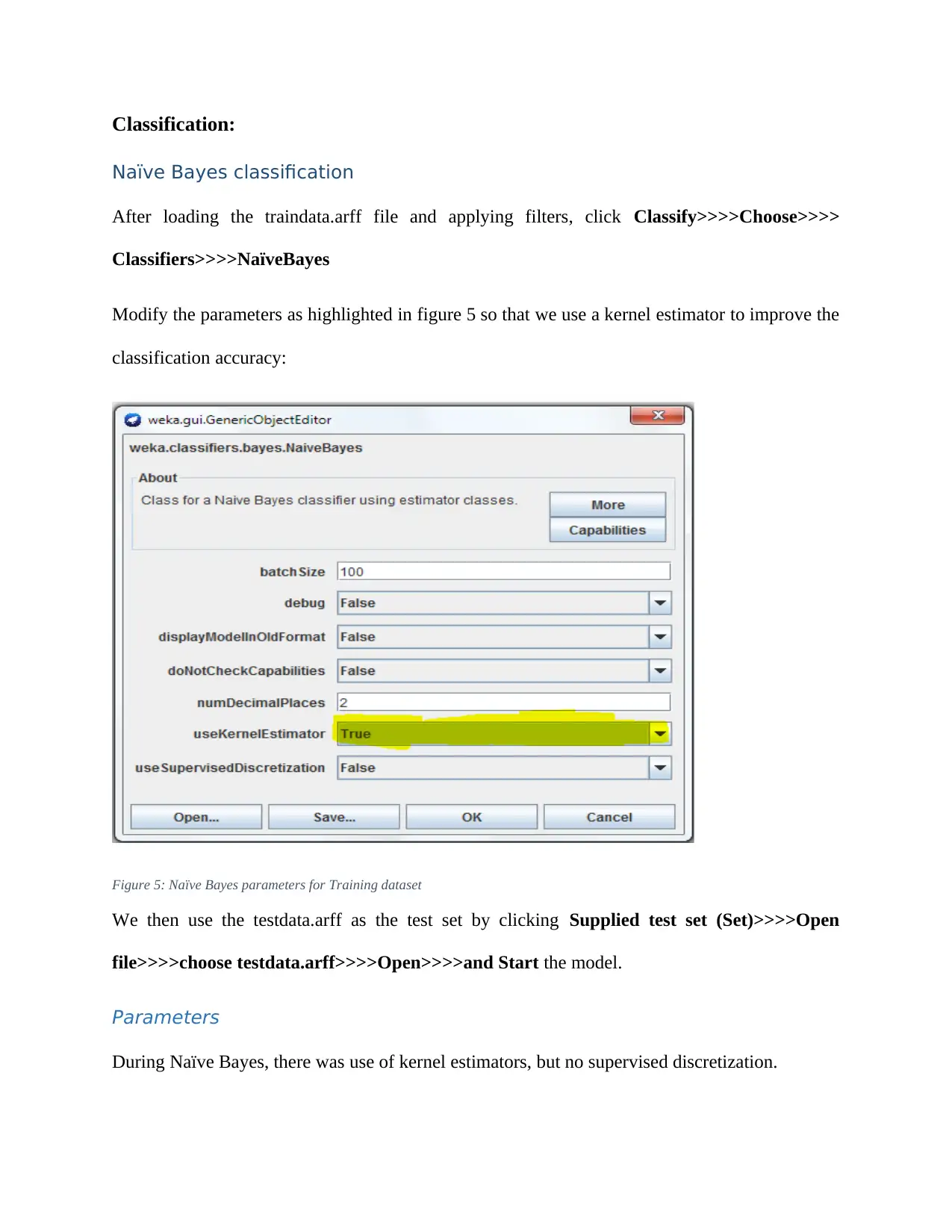
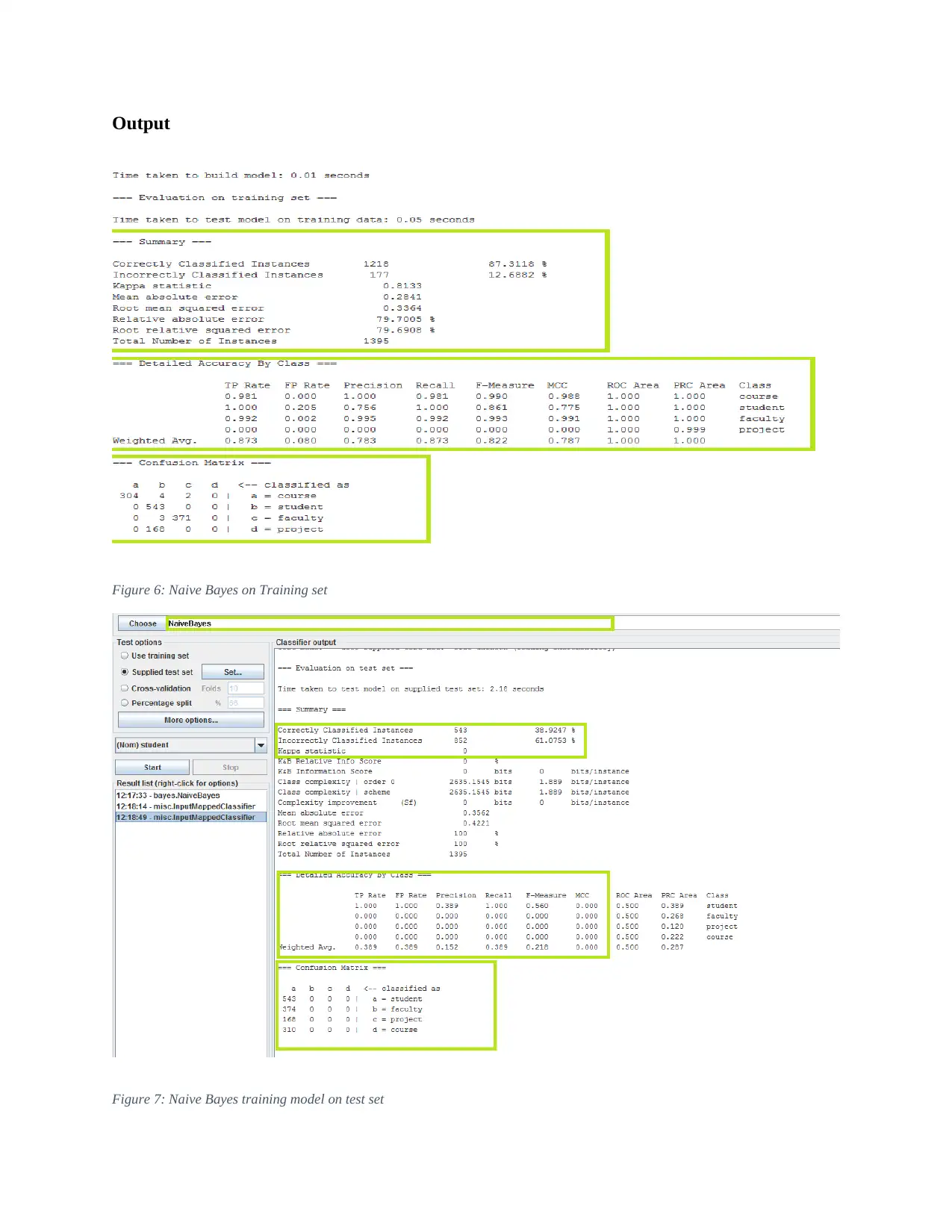
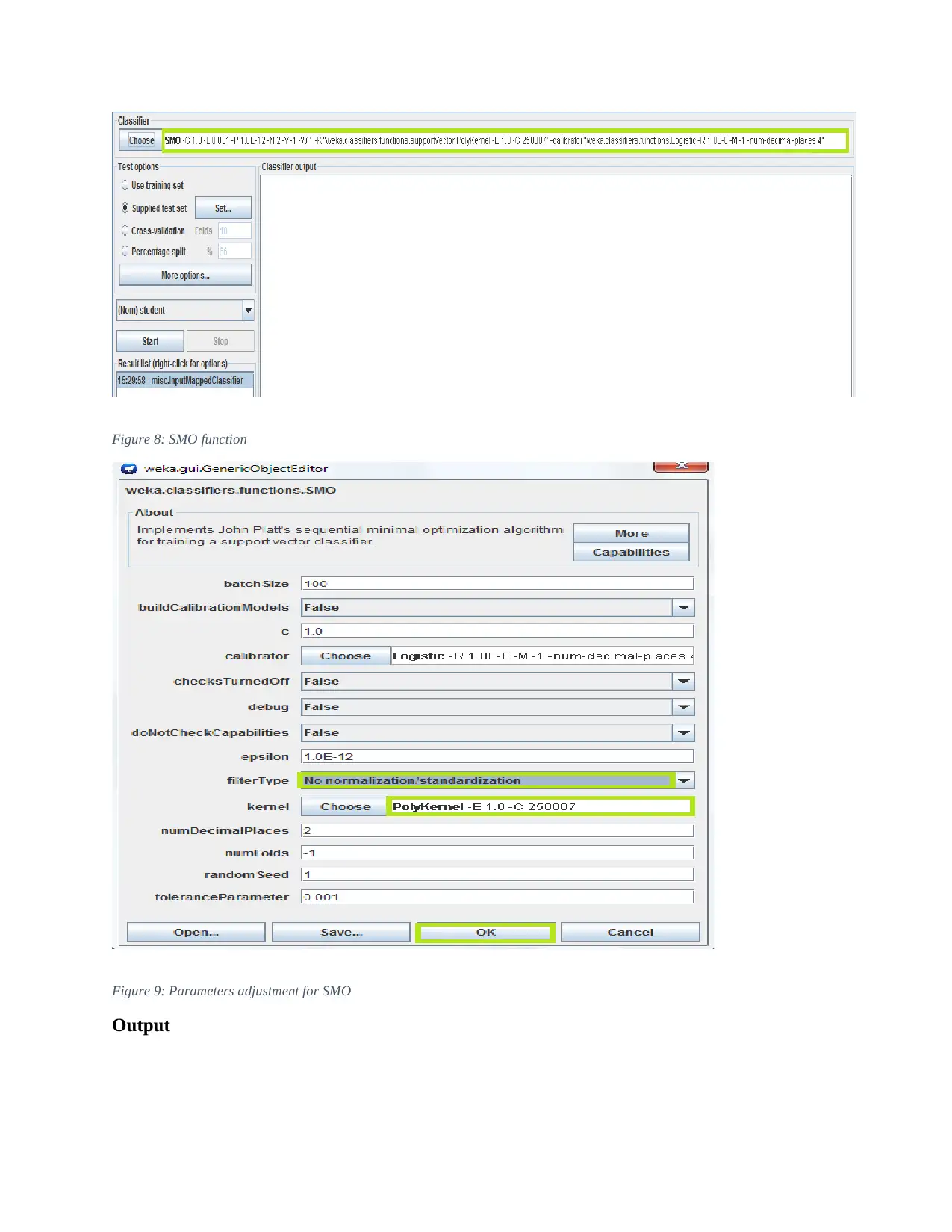
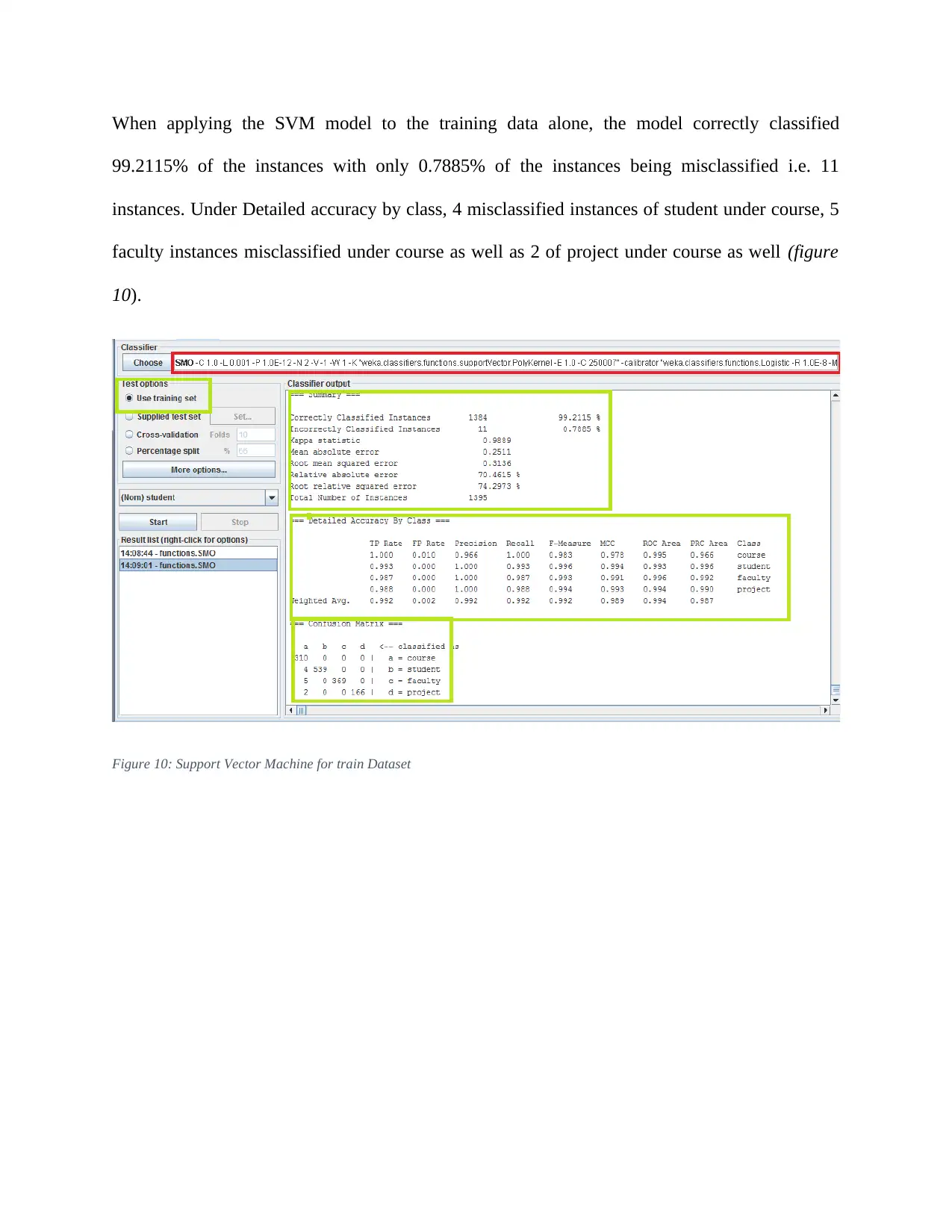
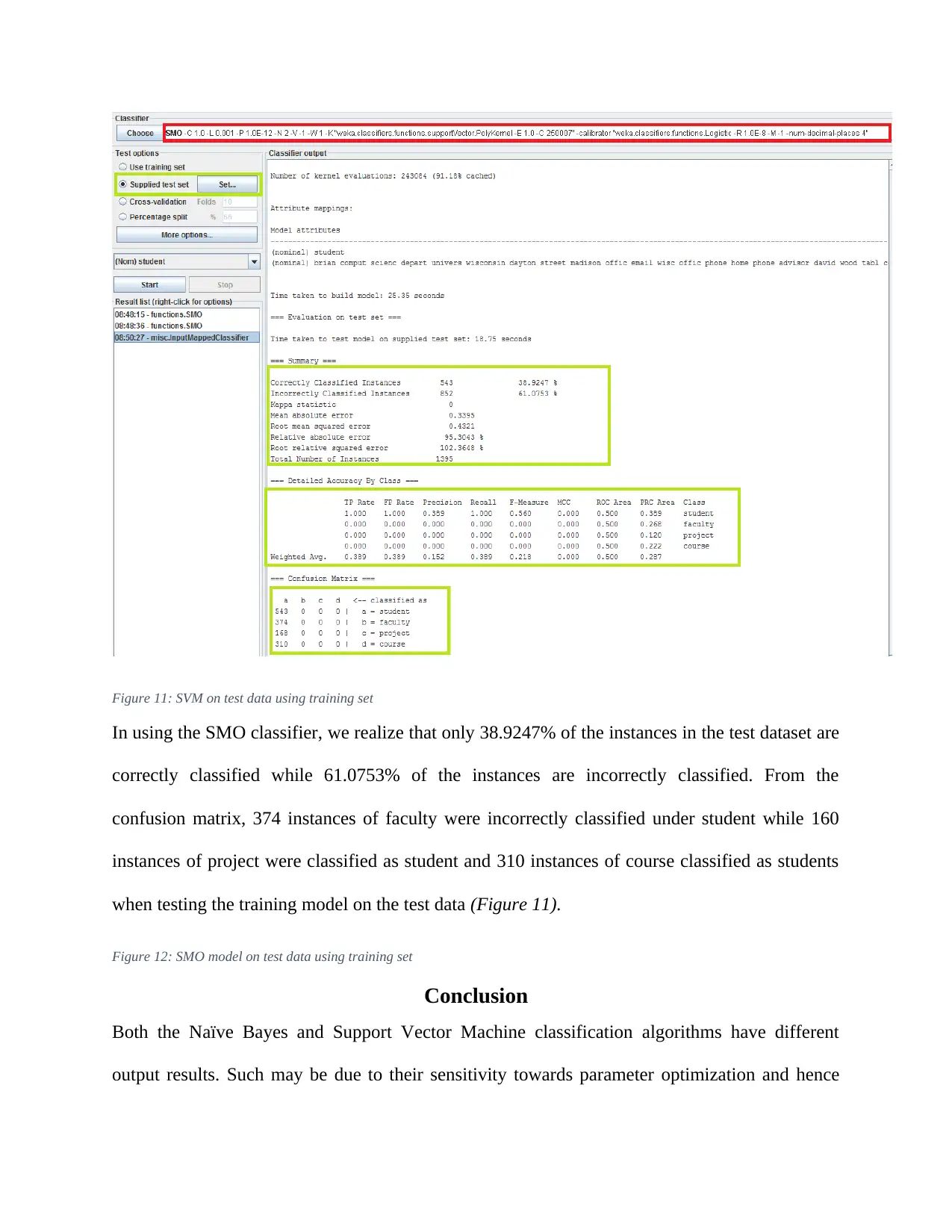
This report details an experiment in text classification using the Naïve Bayes algorithm and Support Vector Machines (SVM) within the context of Natural Language Processing (NLP). The study involves converting text-based datasets into a suitable format for WEKA, a data mining tool, and then applying both Naïve Bayes and SVM classifiers. The report outlines the data preprocessing steps, including converting files to CSV format, loading them into WEKA, and transforming them into Attribute-Relation File Format (ARFF). It also covers the configuration of parameters for both classifiers, emphasizing the use of kernel estimators in Naïve Bayes and Sequential Minimal Optimization (SMO) in SVM. The results indicate that while SVM performed better on the training data, both classifiers achieved similar accuracy on the test data. The report concludes by discussing the potential reasons for the observed differences and highlighting the strengths and weaknesses of each algorithm for text classification.




1 out of 15
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.