BUS130 Statistics Assignment: Analyzing Normal Distribution and Data
VerifiedAdded on 2020/05/11
|14
|1659
|182
Homework Assignment
AI Summary
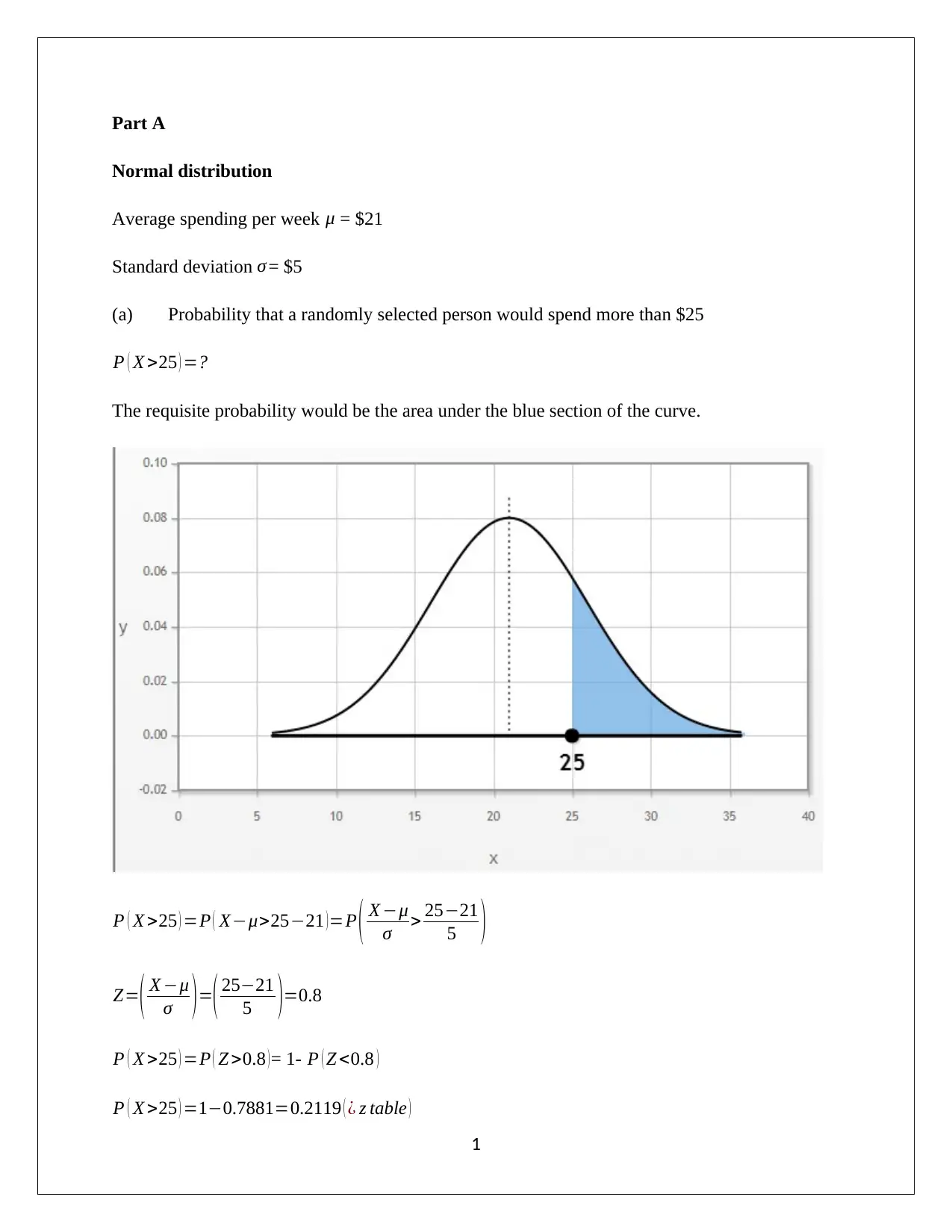
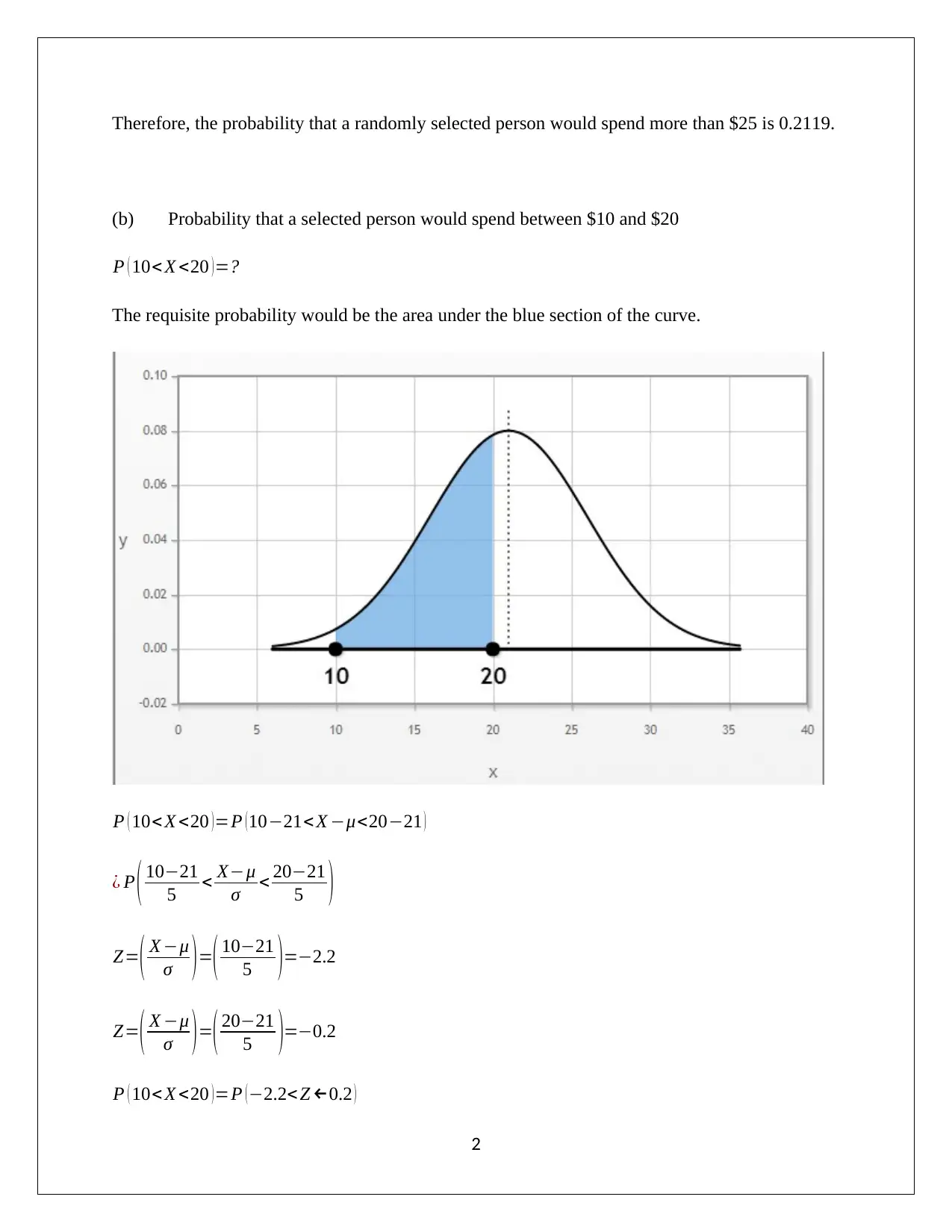
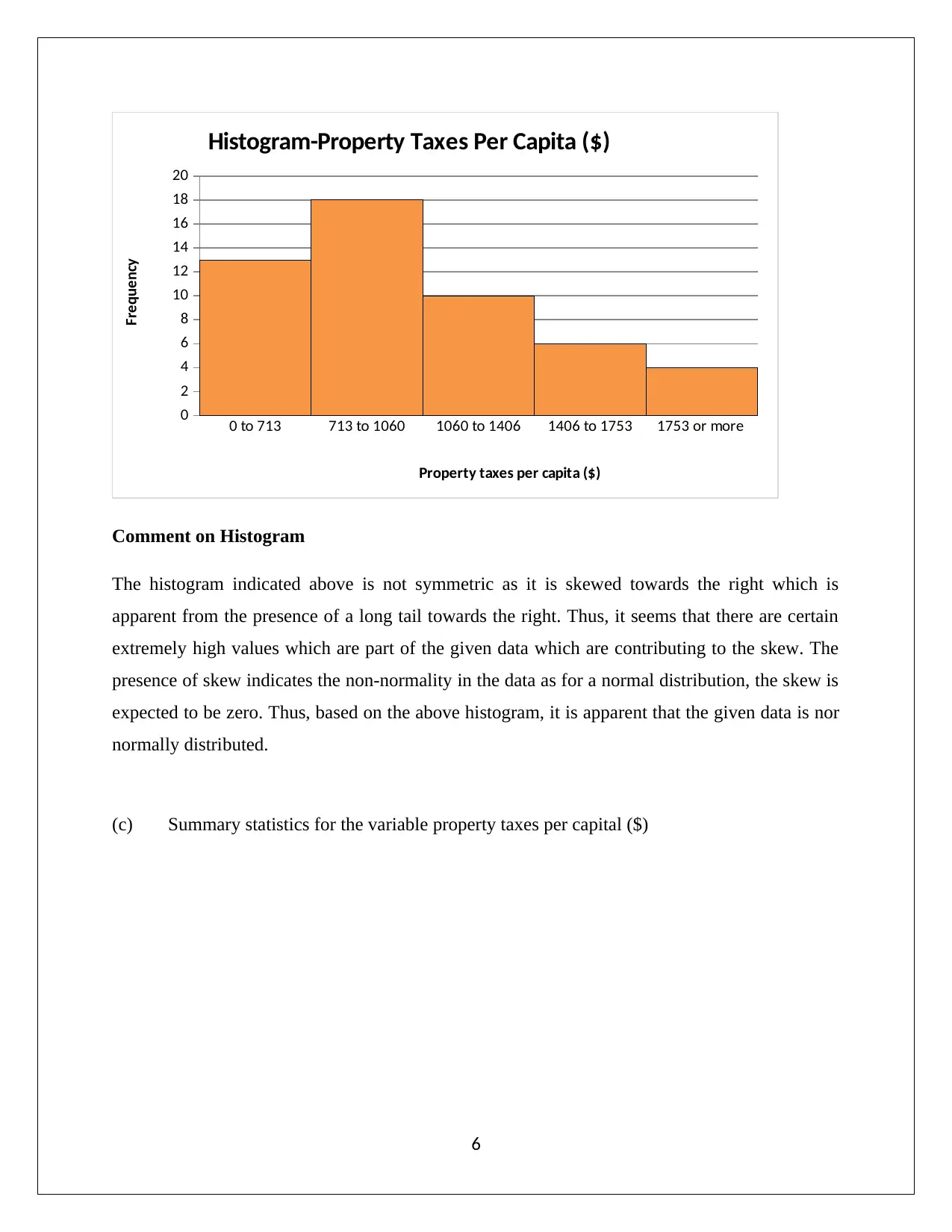
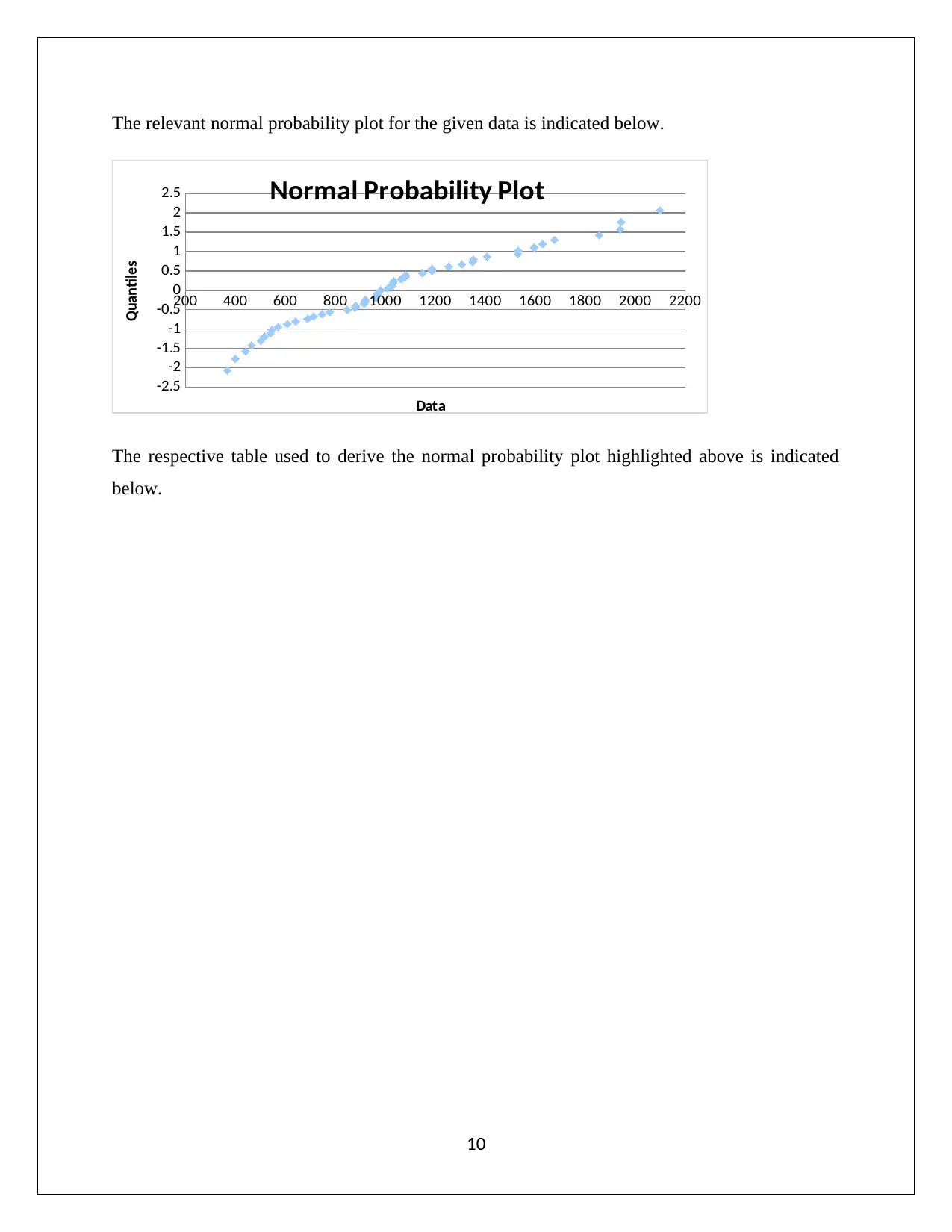
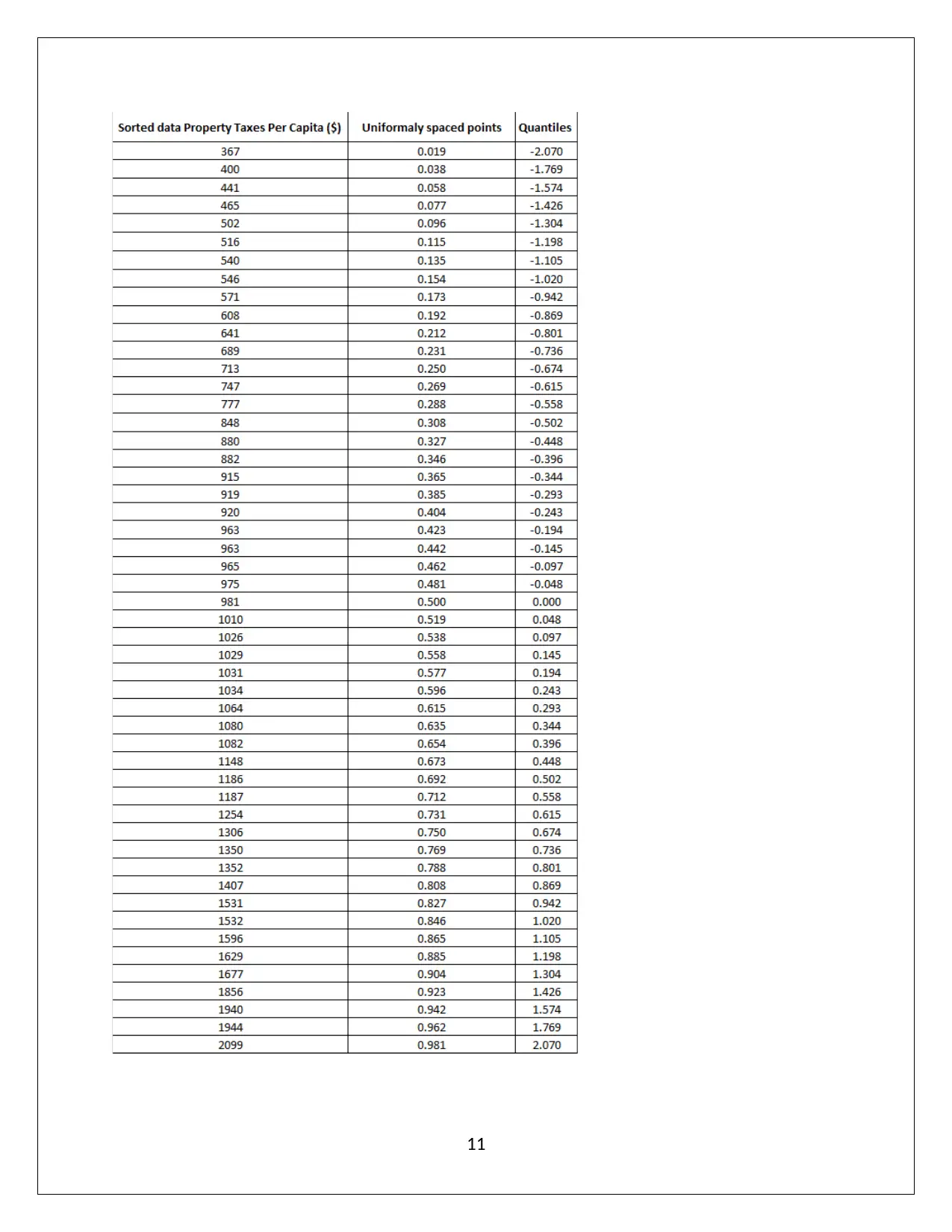
This assignment analyzes normal distribution using statistical methods. Part A focuses on calculating probabilities based on a normal distribution, determining probabilities for spending more than a certain amount, and calculating probabilities for spending within a certain range, and determining the range for the middle 95%. Part B analyzes a dataset of property taxes per capita, assessing whether the data follows a normal distribution. The analysis includes constructing and interpreting box plots, histograms, and calculating summary statistics such as mean, median, skewness, and kurtosis. The assignment also examines theoretical properties of normal distributions, including the percentage of data within one and two standard deviations of the mean, and utilizes a normal probability plot to assess normality. The conclusion determines whether the data is normally distributed based on the various analytical techniques deployed.







1 out of 14
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.