Data Mining Assignment II: Analysis of PCA and Naive Bayes Classifier
VerifiedAdded on 2019/10/31
|7
|957
|208
Homework Assignment
AI Summary
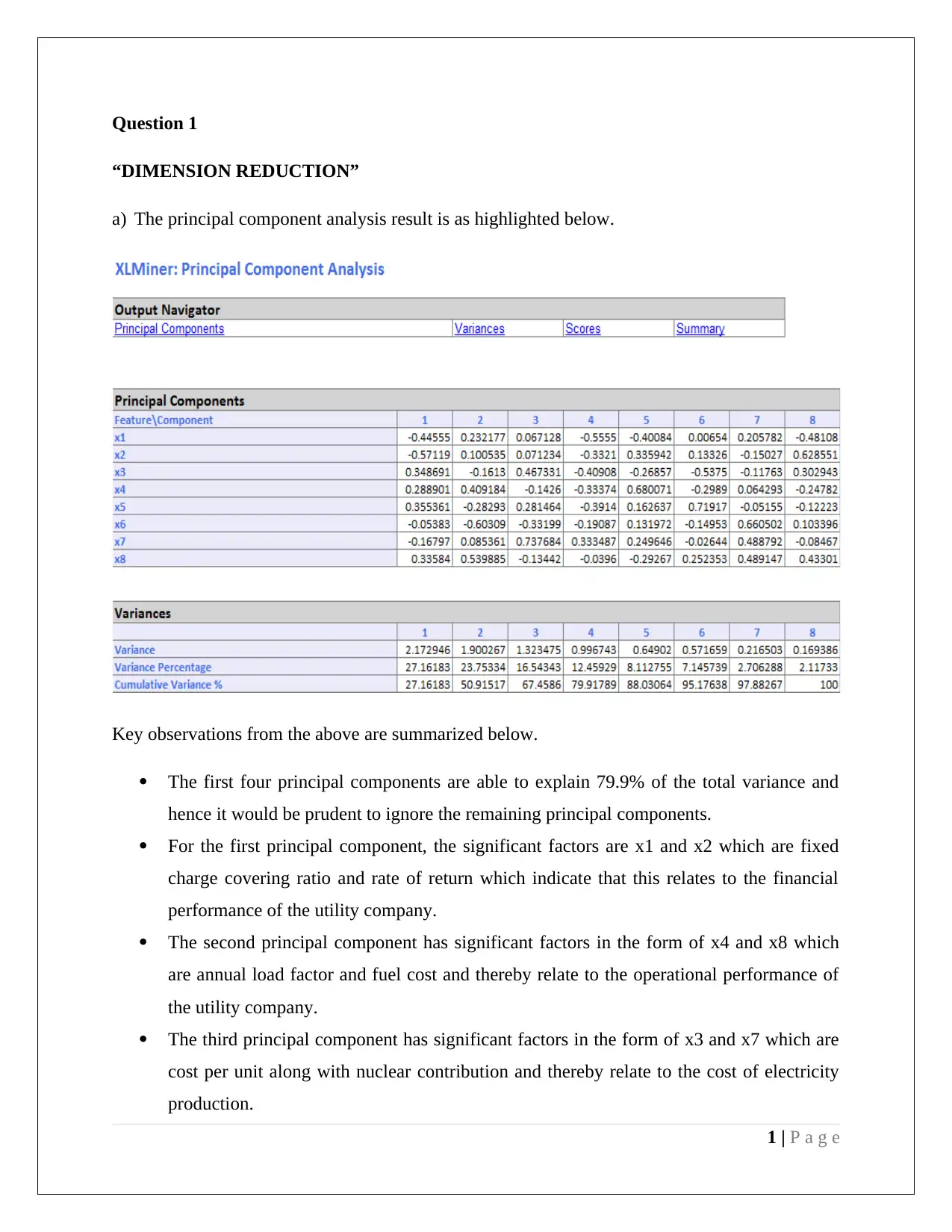
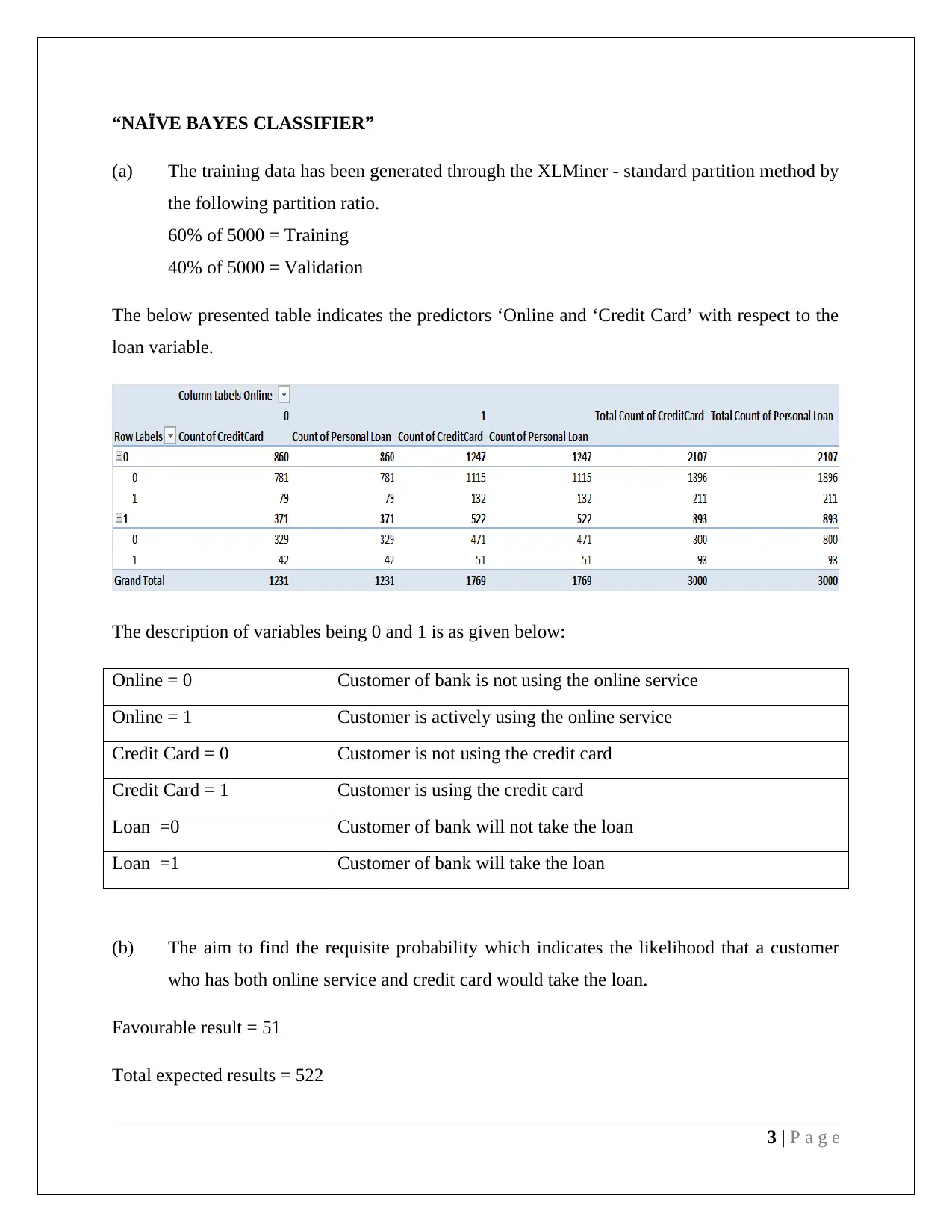
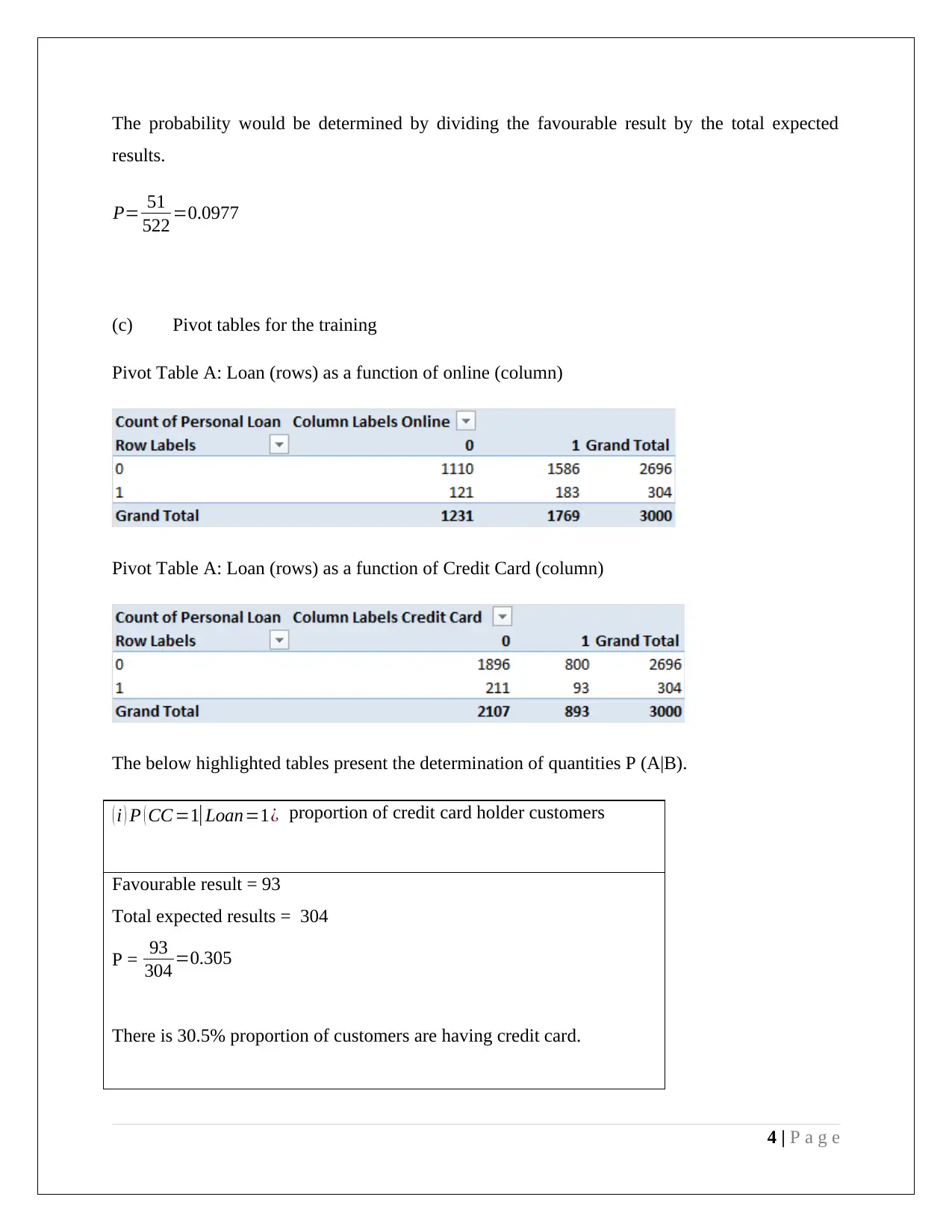
This assignment solution addresses two key concepts in data mining: dimension reduction using Principal Component Analysis (PCA) and classification using the Naive Bayes classifier. The PCA section analyzes the results of a PCA performed on utility company data, identifying significant factors for the first four principal components and discussing the need for data normalization. The Naive Bayes section focuses on predicting loan eligibility based on customer online service usage and credit card ownership, utilizing pivot tables to calculate probabilities and determine the likelihood of a customer taking a loan. The solution provides detailed calculations, interpretations, and recommendations for improving loan offering odds, emphasizing the importance of both online banking and credit card usage.




1 out of 7
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.