Statistical Analysis: Population, Samples, and Distribution of Means
VerifiedAdded on 2022/08/27
|9
|997
|18
Homework Assignment
AI Summary
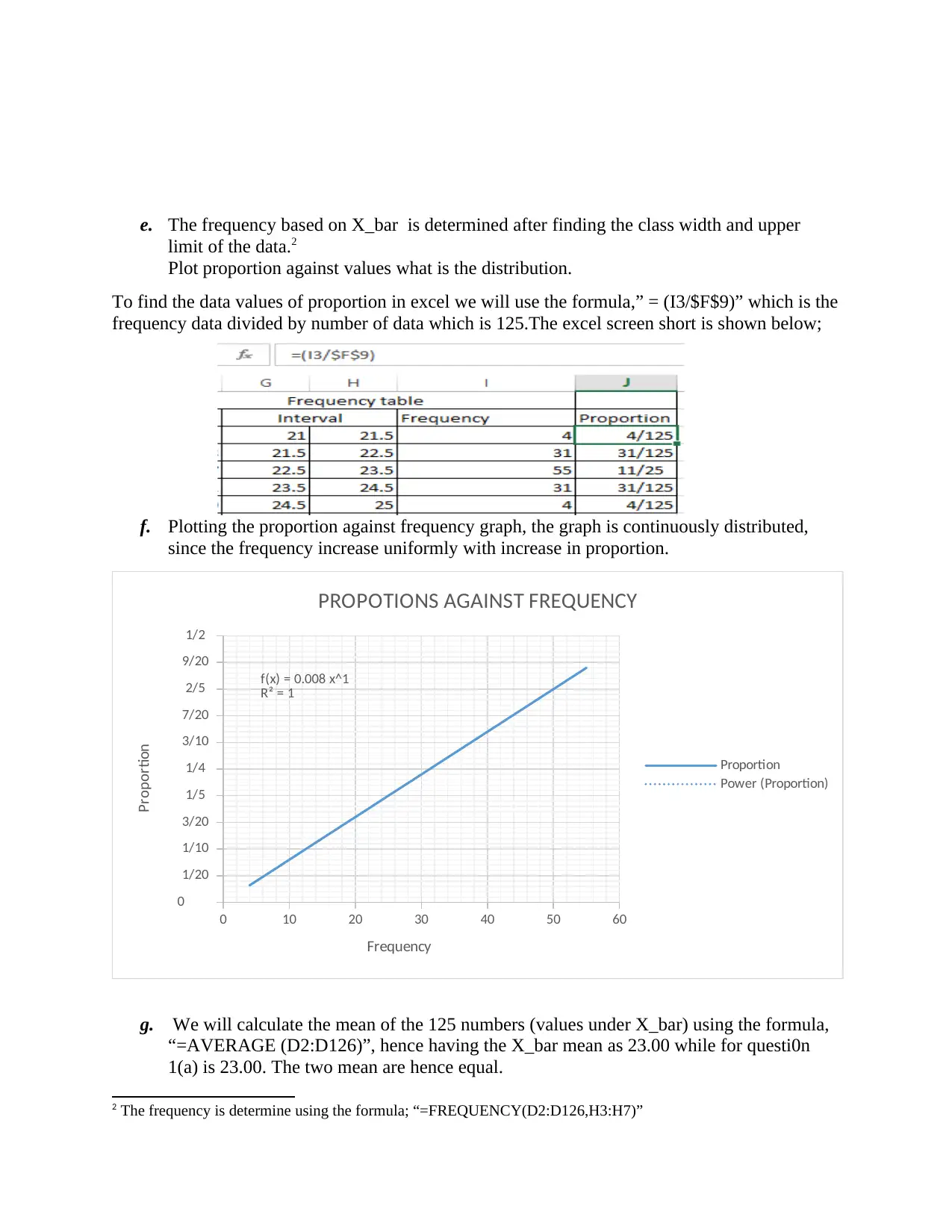
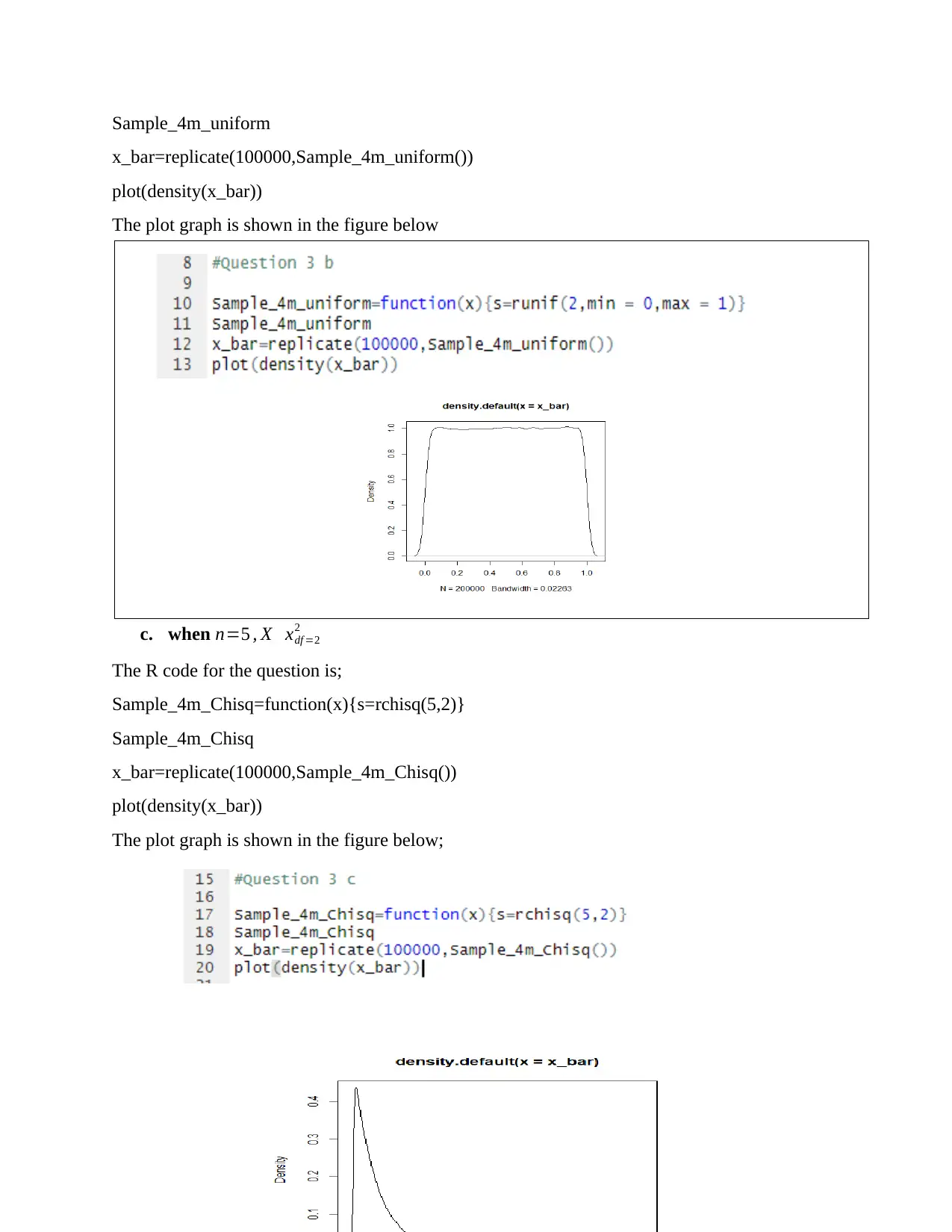
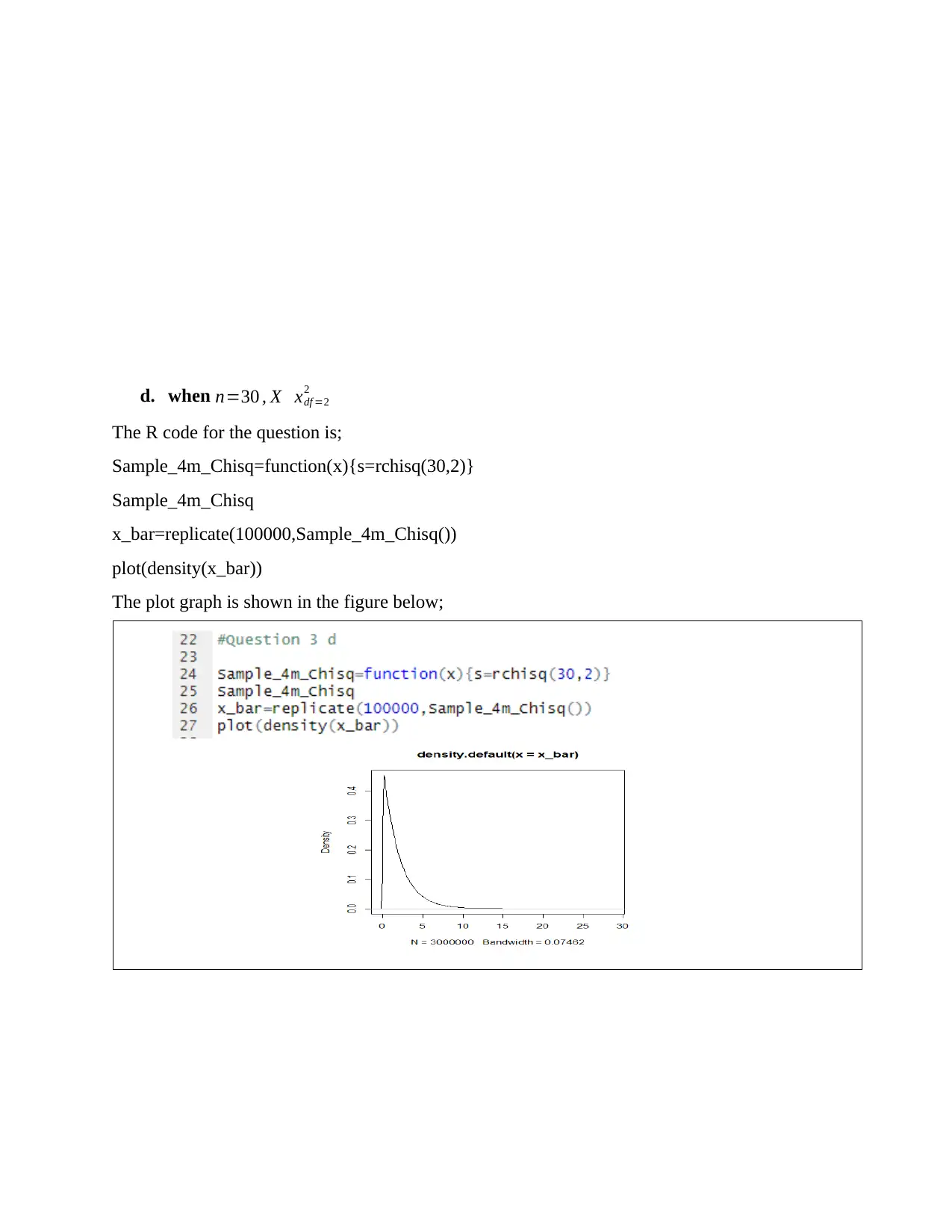
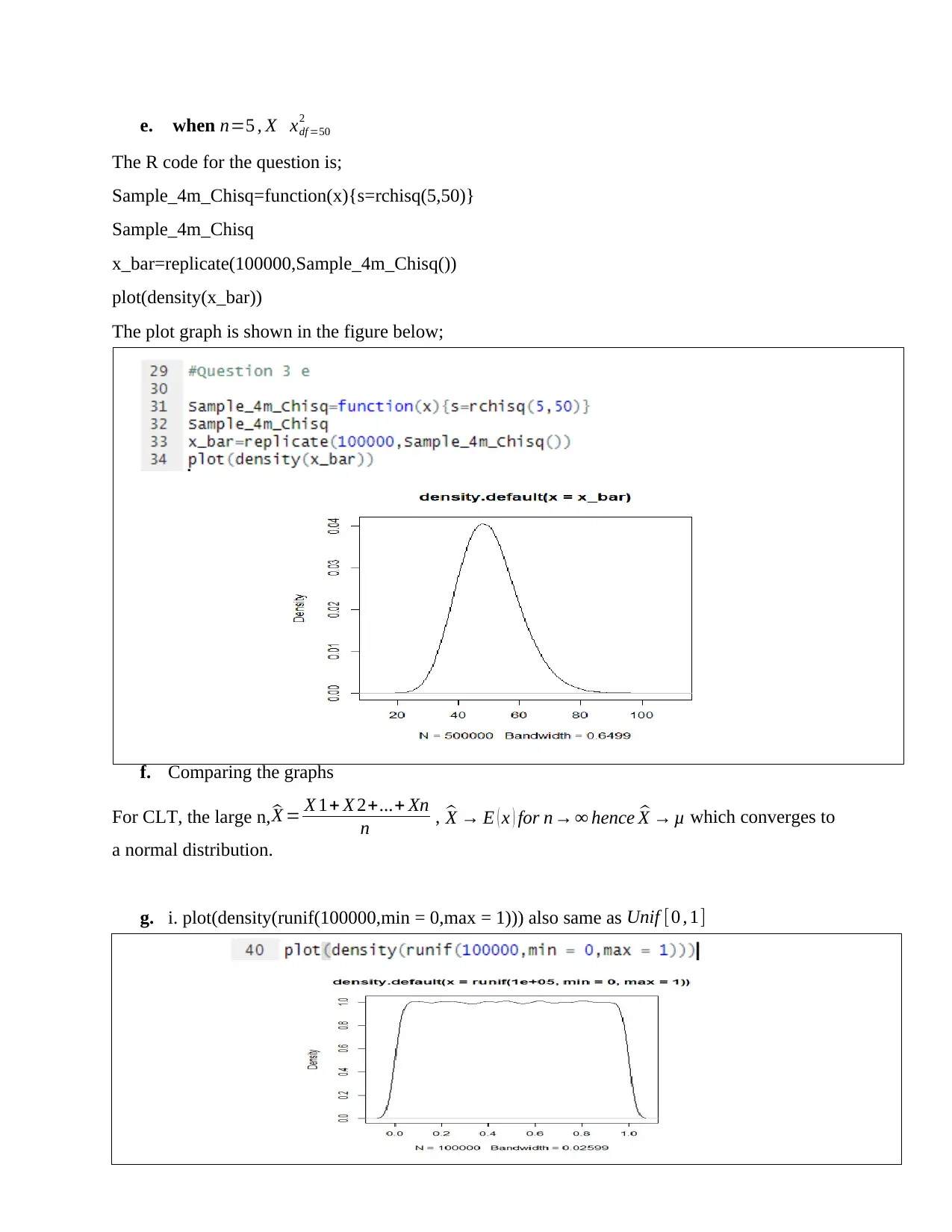
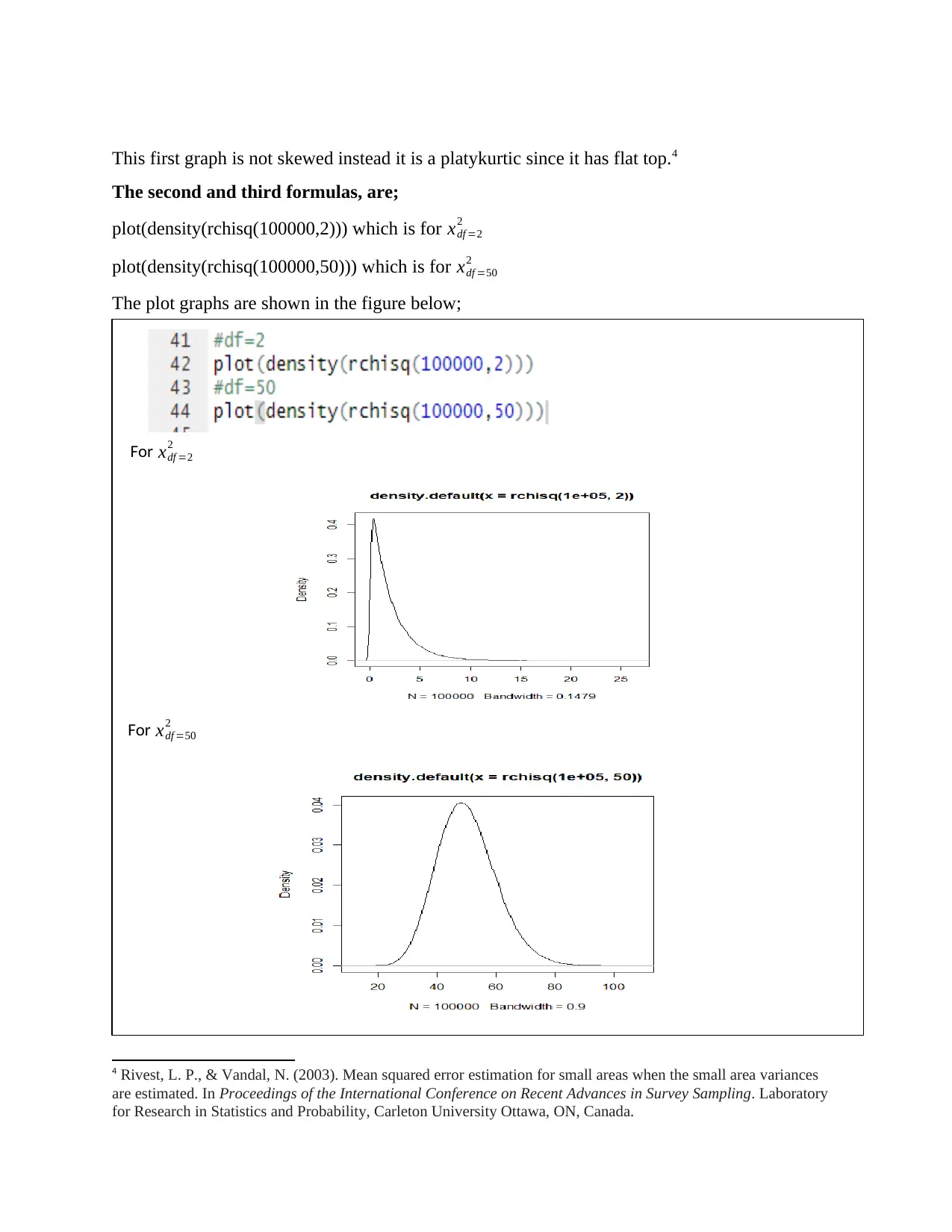
This assignment delves into statistical concepts, beginning with the calculation of population mean and variance. It then explores sampling with replacement, generating all possible combinations of samples of size 3 from a population of size 5. For each sample, the sample mean is calculated, and a frequency table is constructed. The assignment uses R software and Excel for data manipulation and analysis. The analysis includes plotting the proportion against frequency to determine the distribution and calculating the mean and variance of the sample means. Furthermore, it empirically demonstrates the central limit theorem and compares the variance of the sample means to the population variance. The assignment concludes with the production of density plots for different distributions using R code and comparing them to understand the central limit theorem. The analysis covers topics such as platykurtic distribution, skewed distribution and normal distribution.




1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.