Bank Marketing Case Study: Data Analysis, Methods, and Algorithms
VerifiedAdded on 2022/11/26
|5
|1380
|165
Case Study
AI Summary
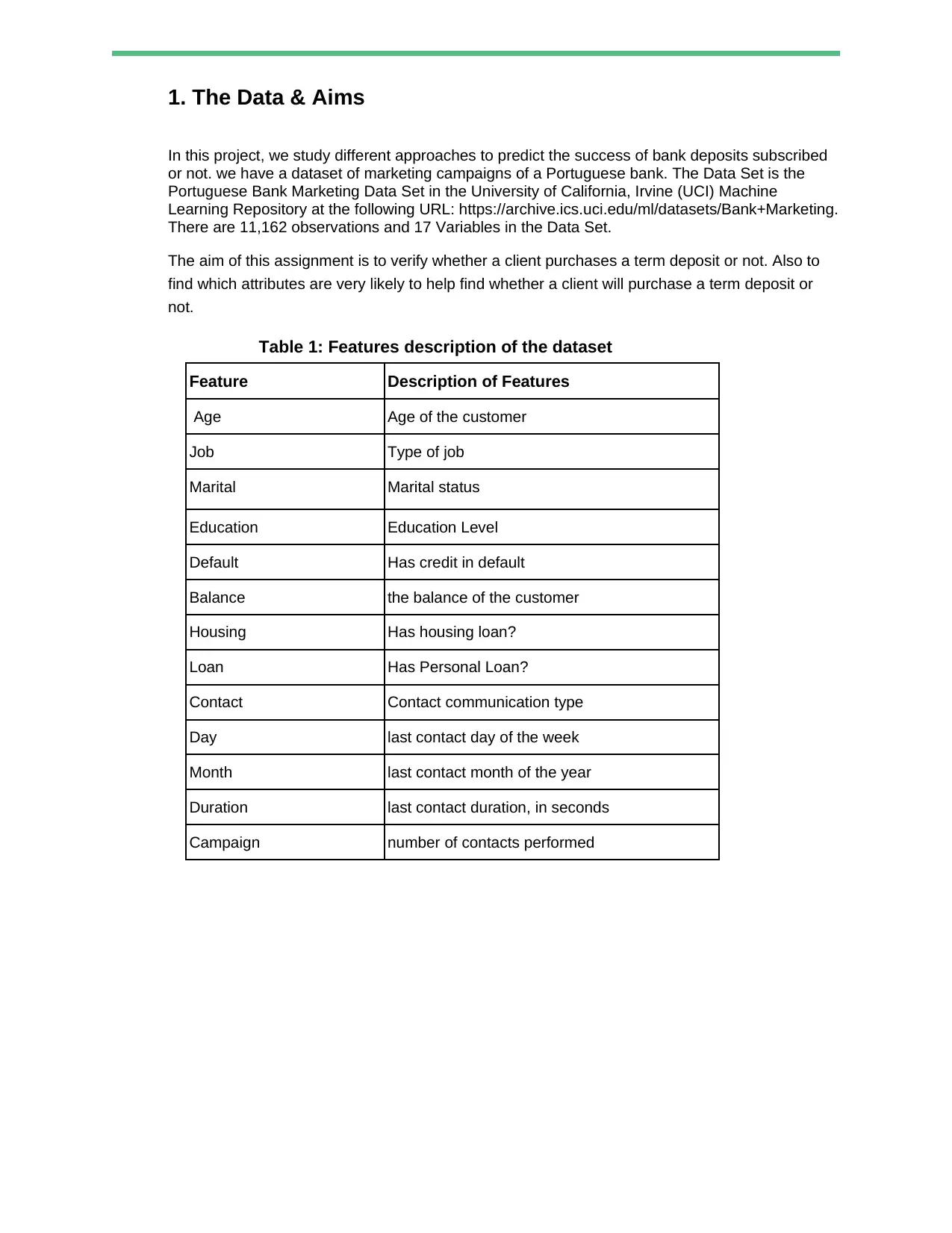
This case study analyzes a Portuguese bank's marketing campaigns to predict whether a client will subscribe to a term deposit. The study utilizes a dataset with 11,162 observations and 17 variables, employing various methods and algorithms, including one-hot encoding, min-max normalization, PCA, K-means clustering, logistic regression, decision trees, and Naive Bayes. The analysis identifies key features influencing term deposit purchases and discusses the performance of each model. The Naive Bayes algorithm achieved the highest accuracy. The study concludes by highlighting the importance of these variables for banks to target clients likely to purchase term deposits, offering insights into data analysis, machine learning, and practical applications in the banking sector.




1 out of 5


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.