Financial Econometrics: Pricing Factor Models and Diagnostic Tests
VerifiedAdded on 2020/02/05
|12
|2016
|34
Homework Assignment
AI Summary
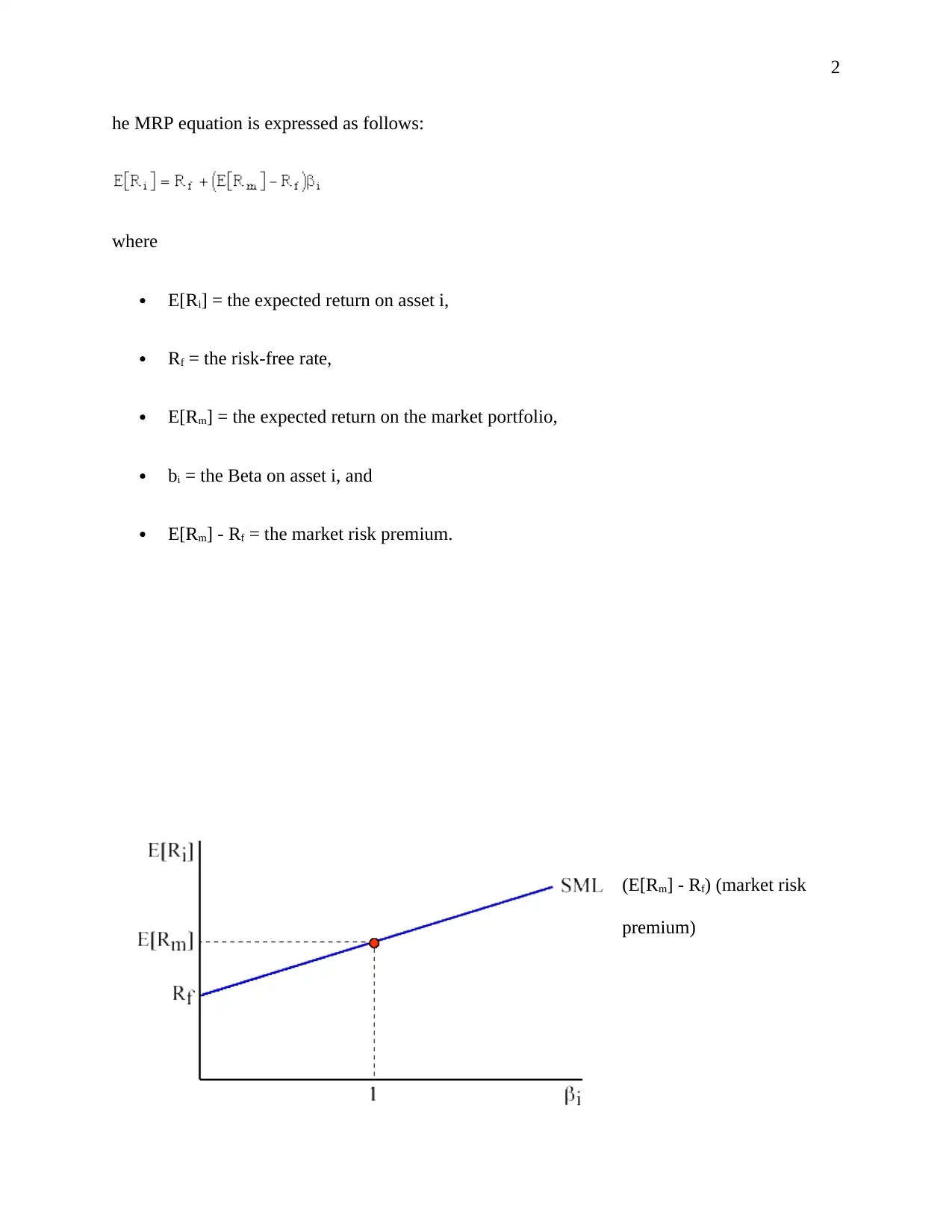
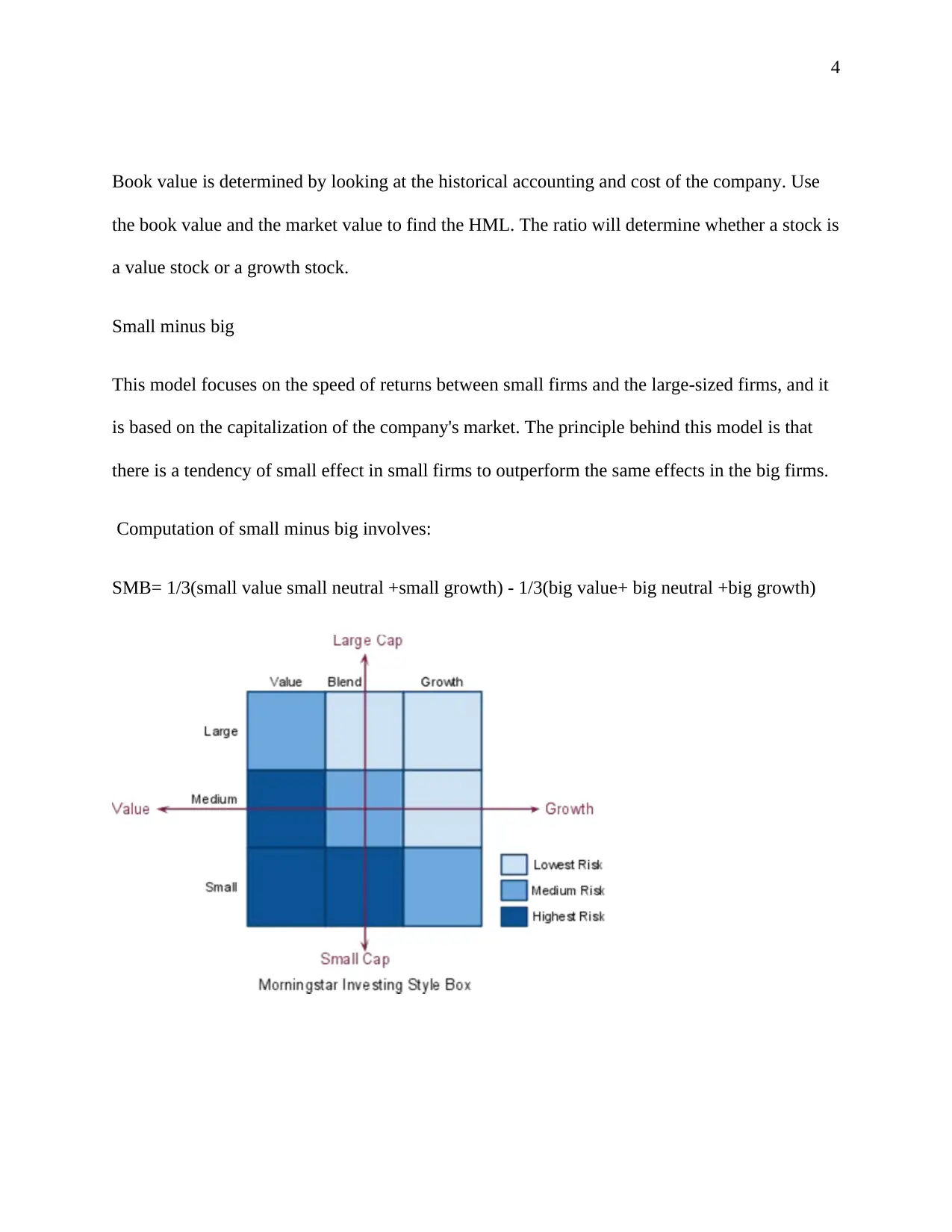
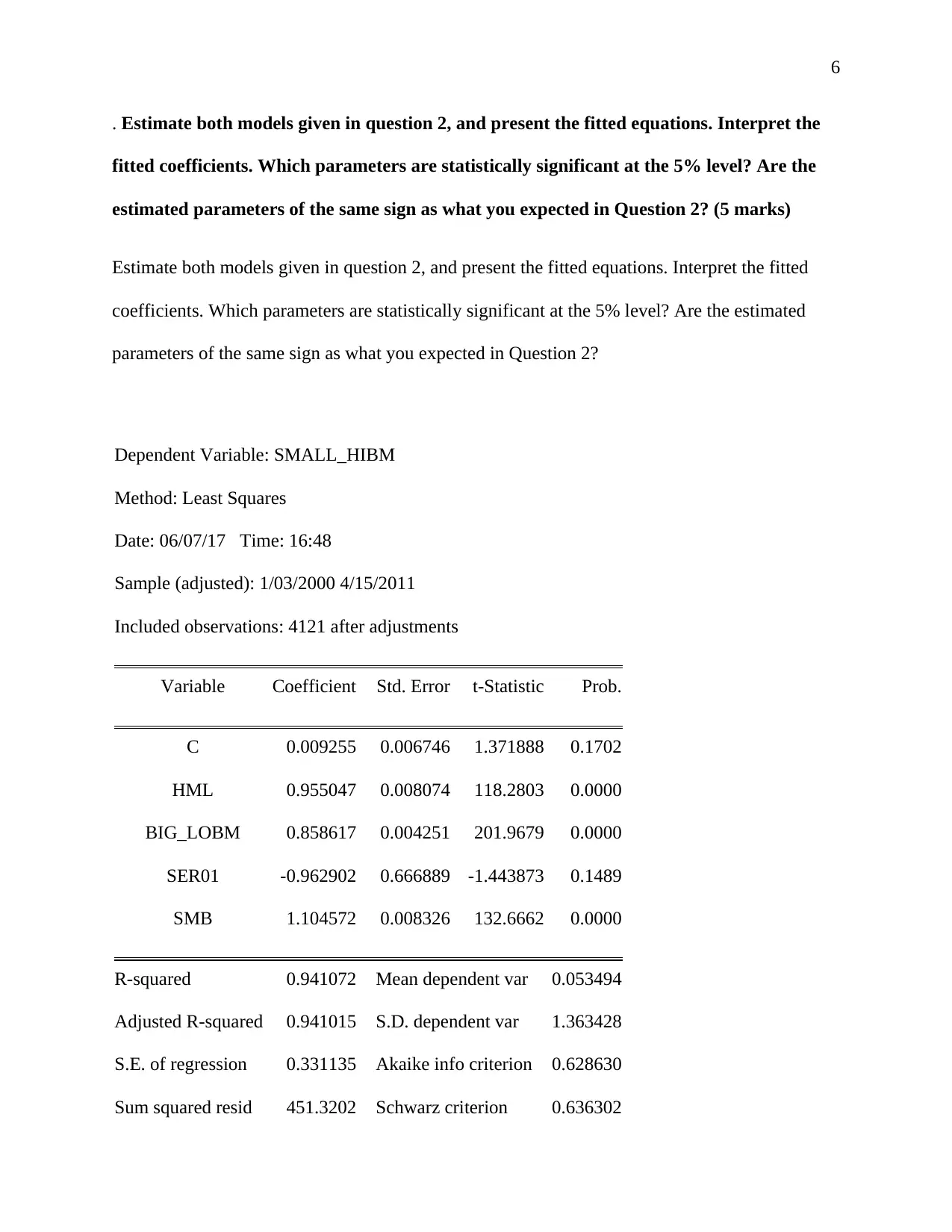
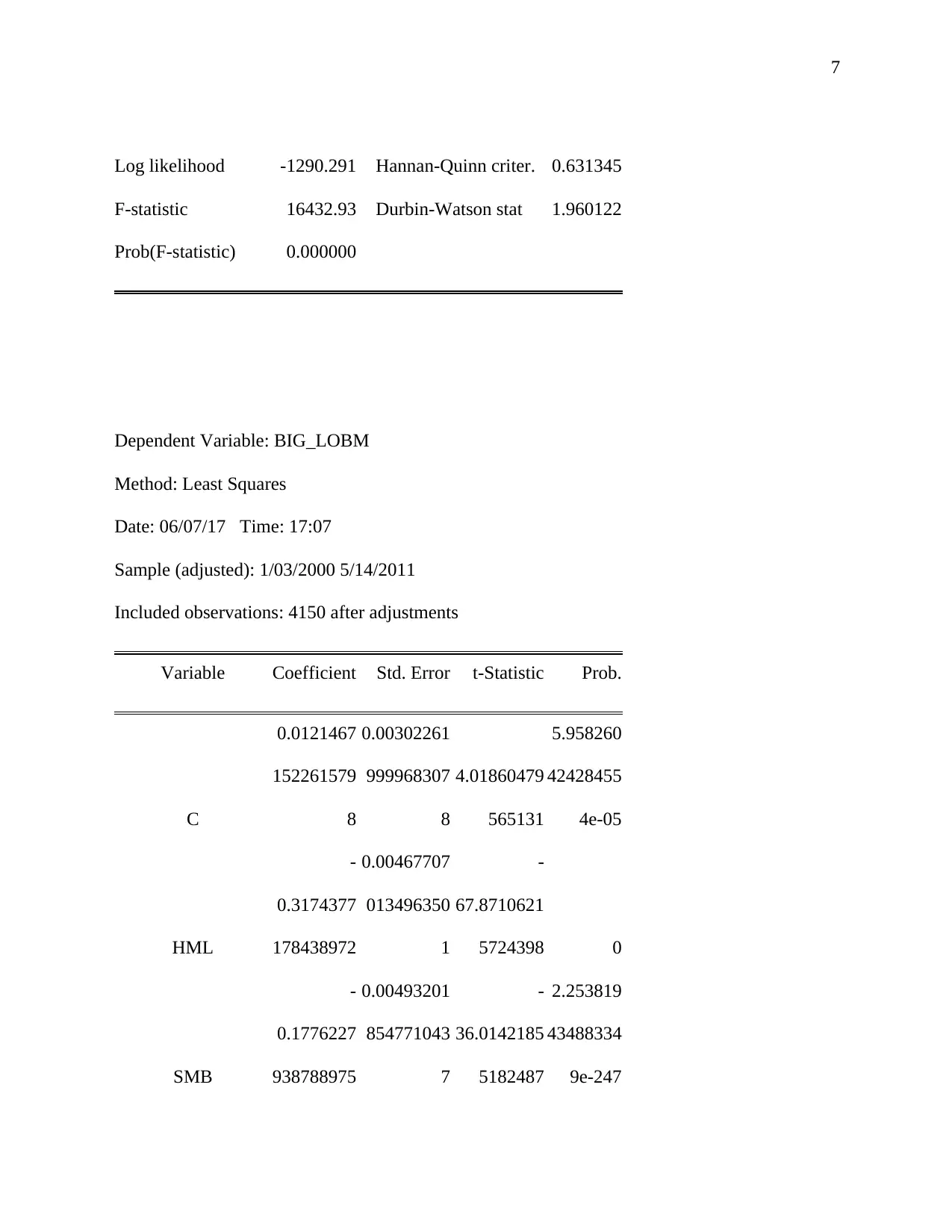
This assignment analyzes financial pricing factors based on the Fama and French (1996) model, focusing on market risk premium, high minus low (value premium), and small minus big factors. It involves computing these factors, providing descriptive statistics and graphs for SMALL_HiBM and BIG_LoBM portfolios, and interpreting their characteristics. The assignment further explores the expected signs of coefficients in the pricing equations and estimates the models, interpreting the fitted coefficients and assessing their statistical significance. The solution then tests the validity of the CAPM relative to the three-factor model and conducts diagnostic tests, including auto-collinearity, heteroskedasticity, and non-normality, to assess the reliability of the estimated models. Finally, the assignment discusses potential solutions to address any identified issues in the data analysis process.






1 out of 12
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.