Psychological Well-being: Psy2530 Descriptive Statistics Problem Set 1
VerifiedAdded on 2023/04/21
|19
|3583
|441
Homework Assignment
AI Summary
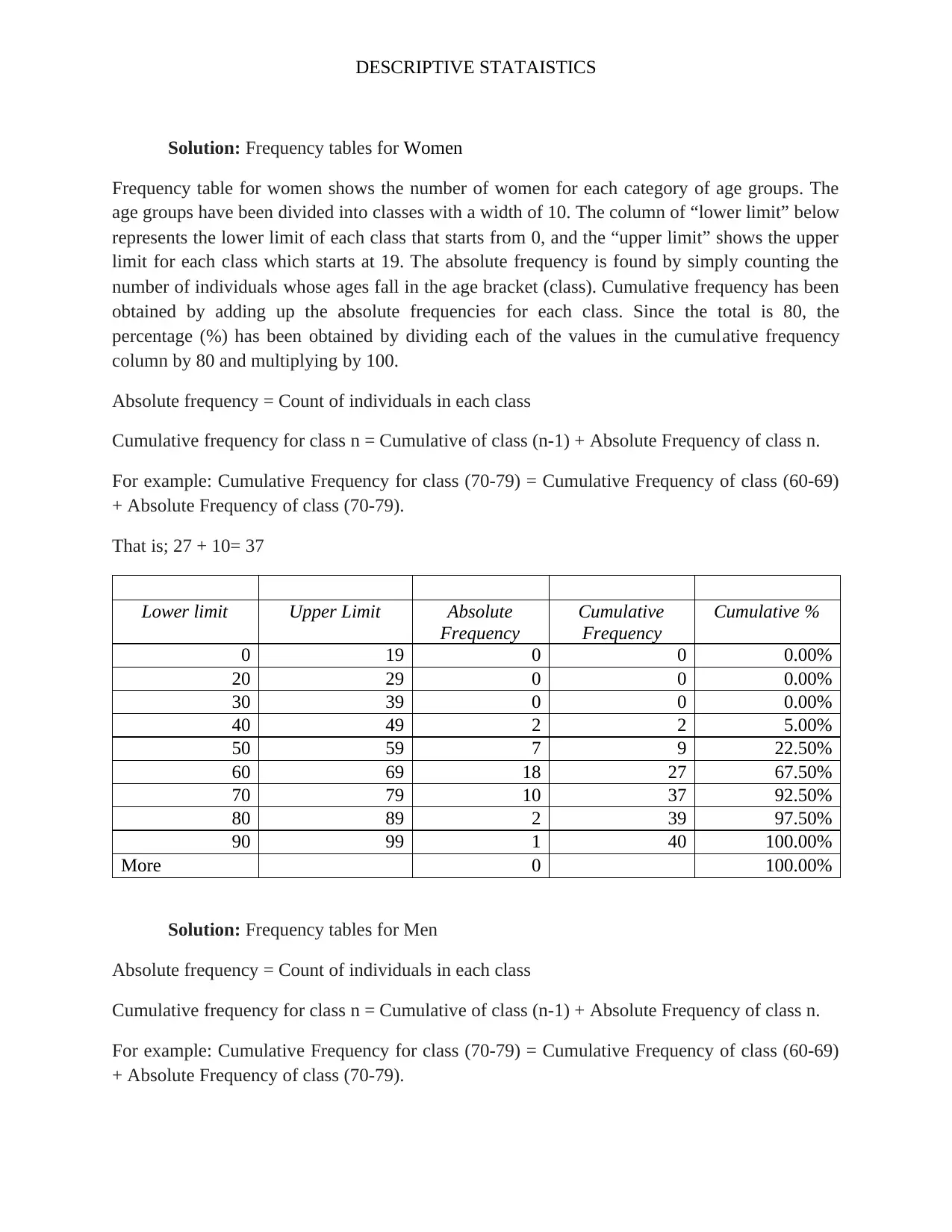
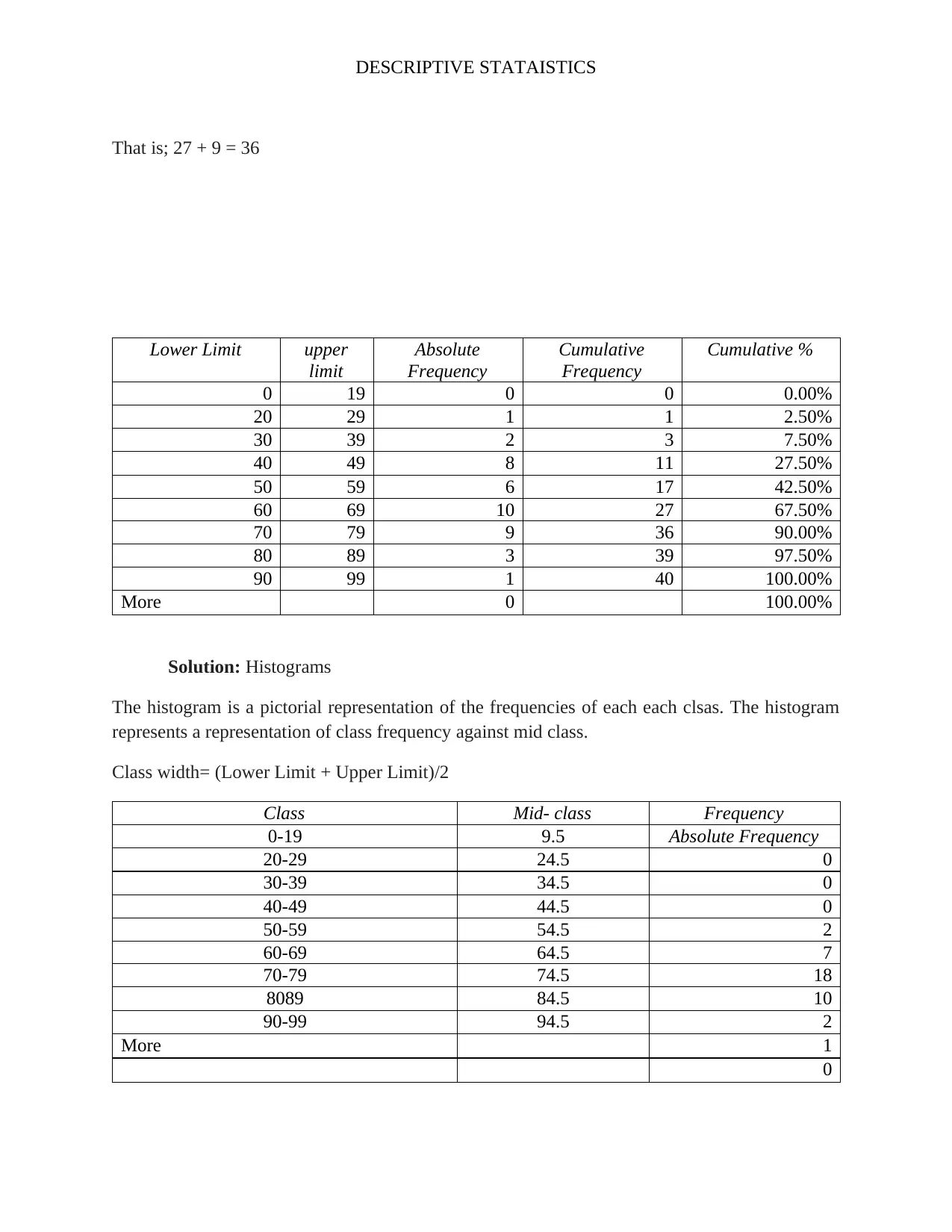
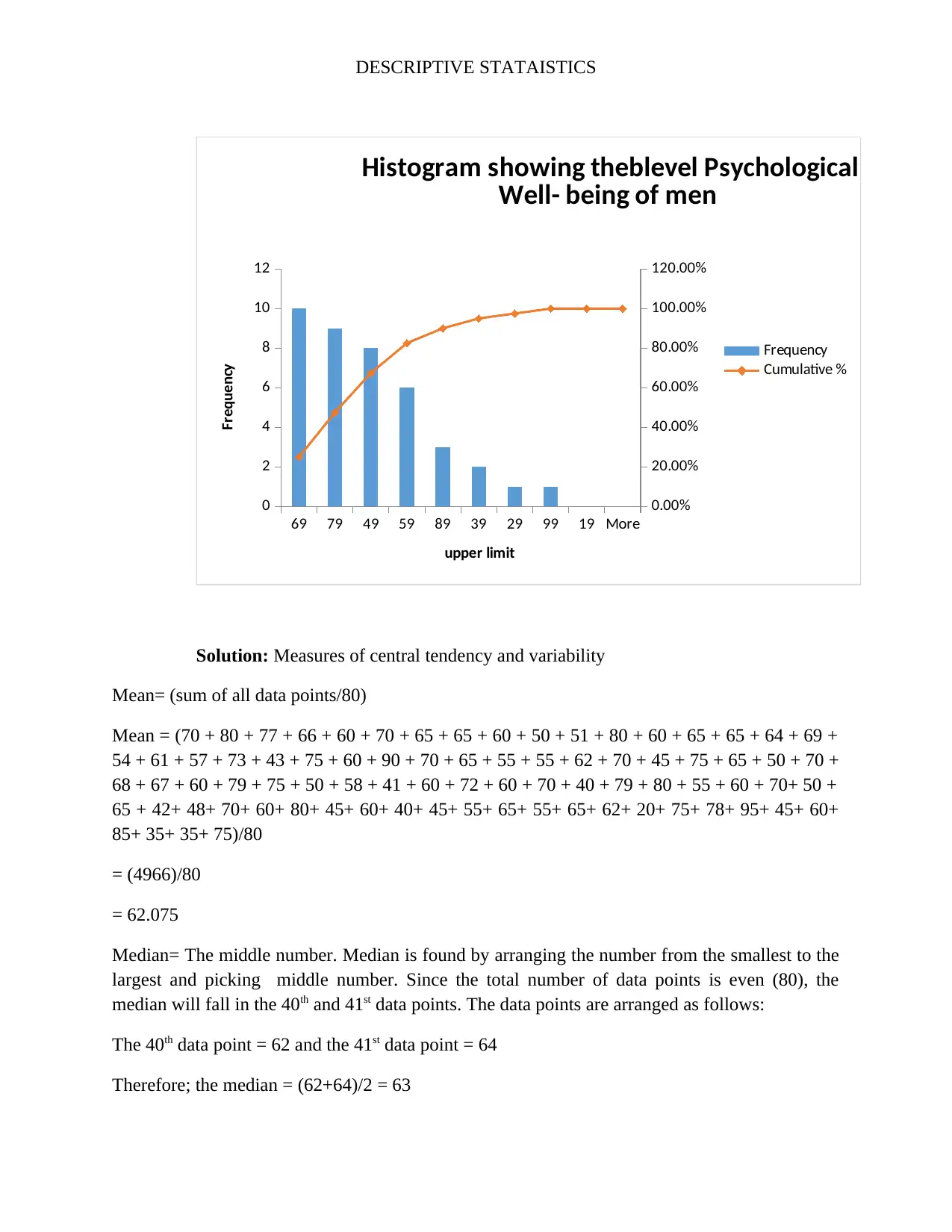
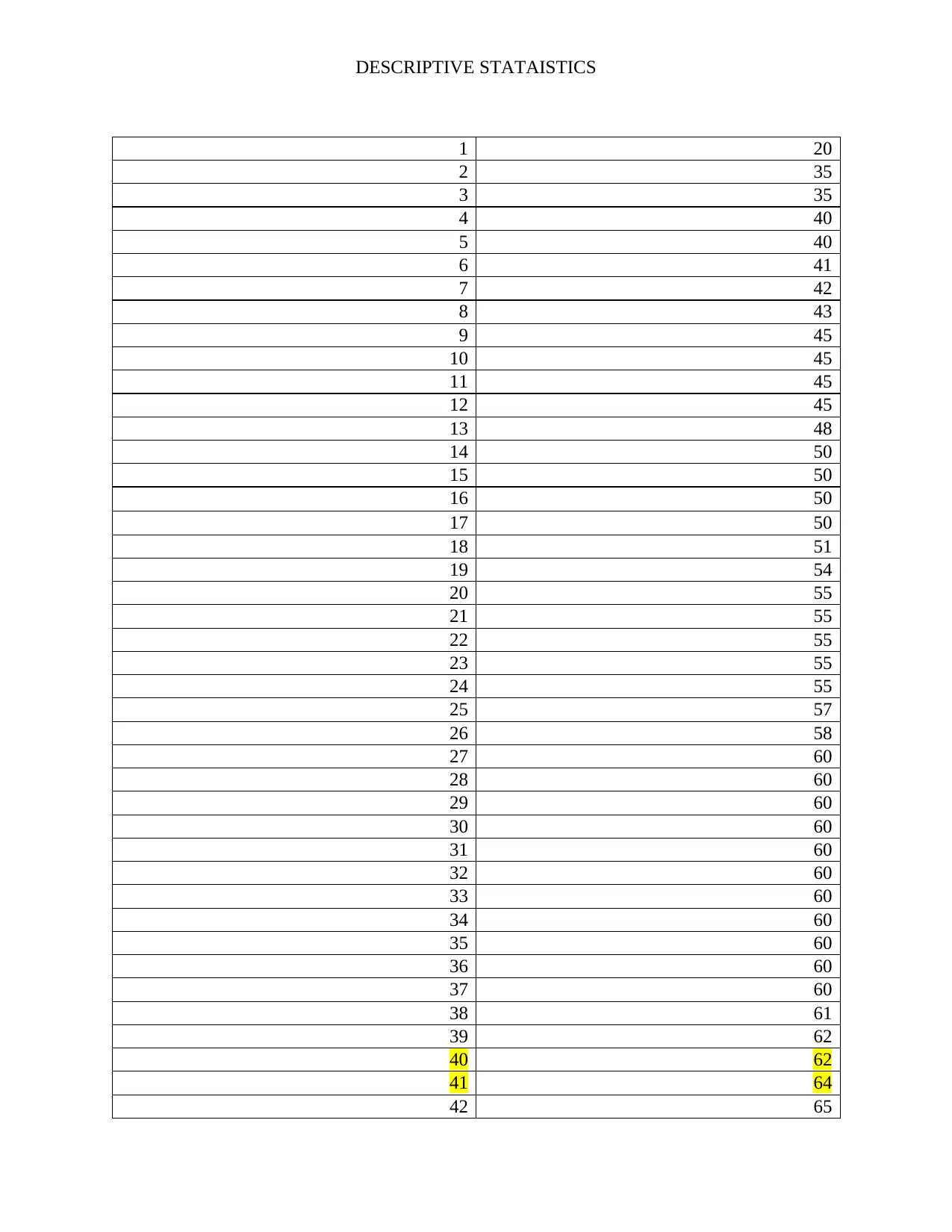
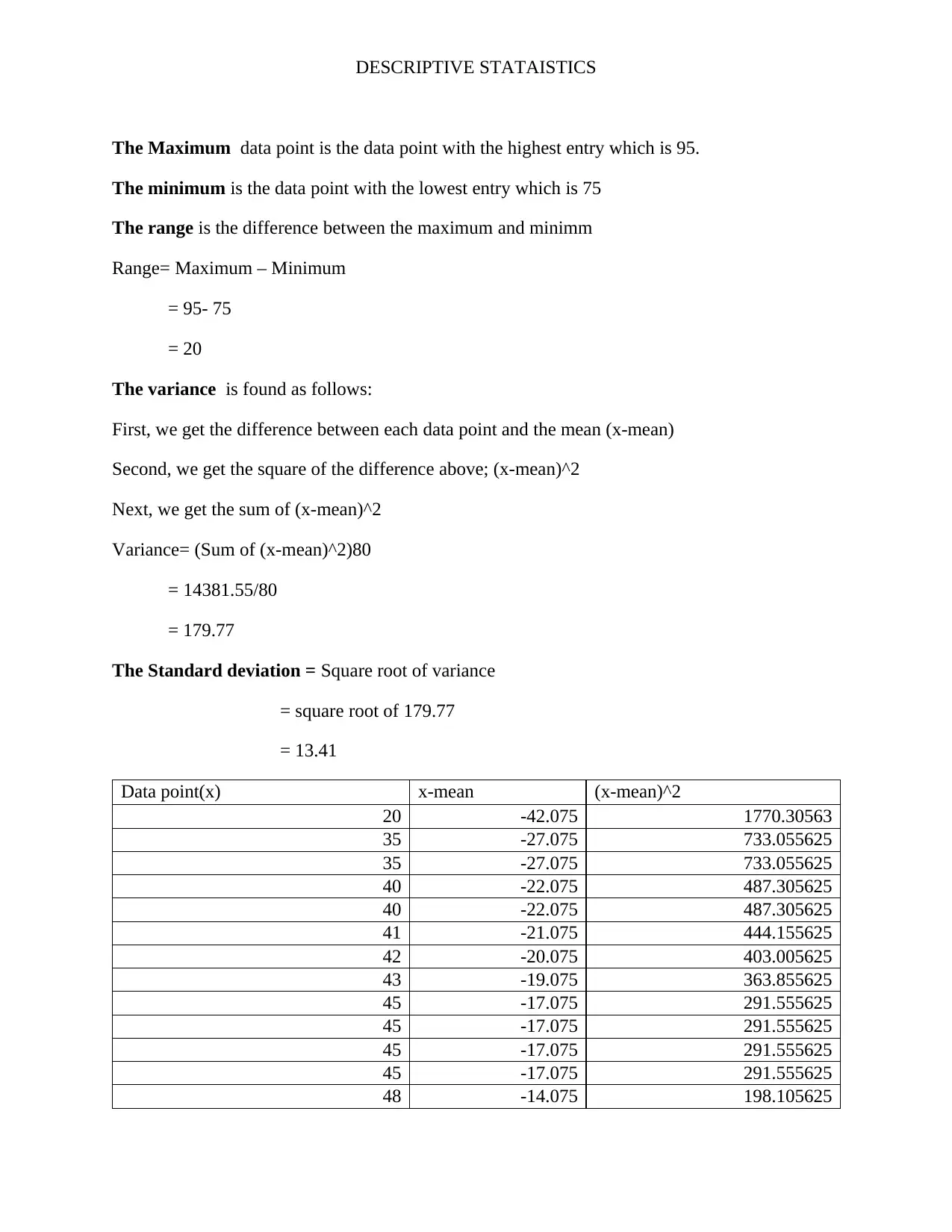
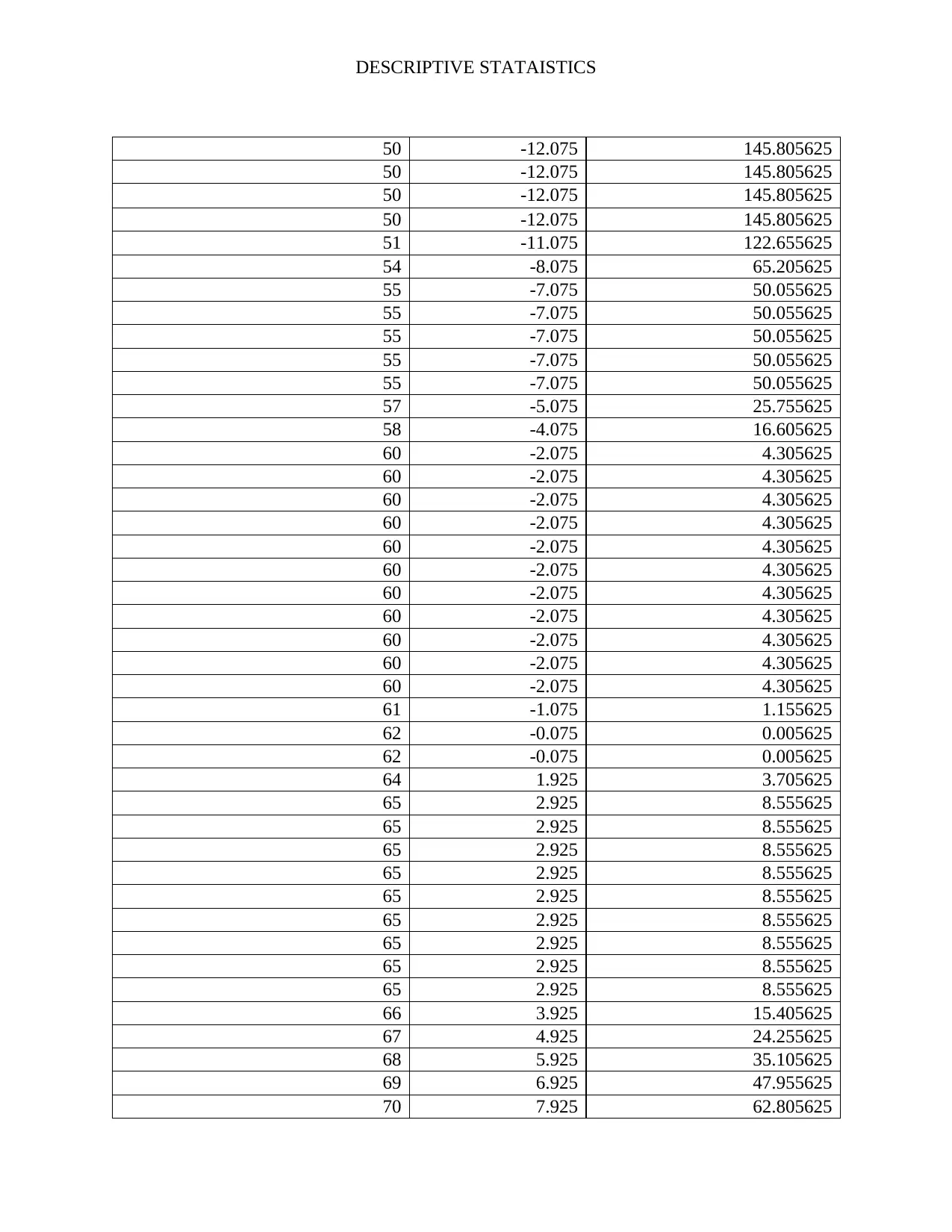
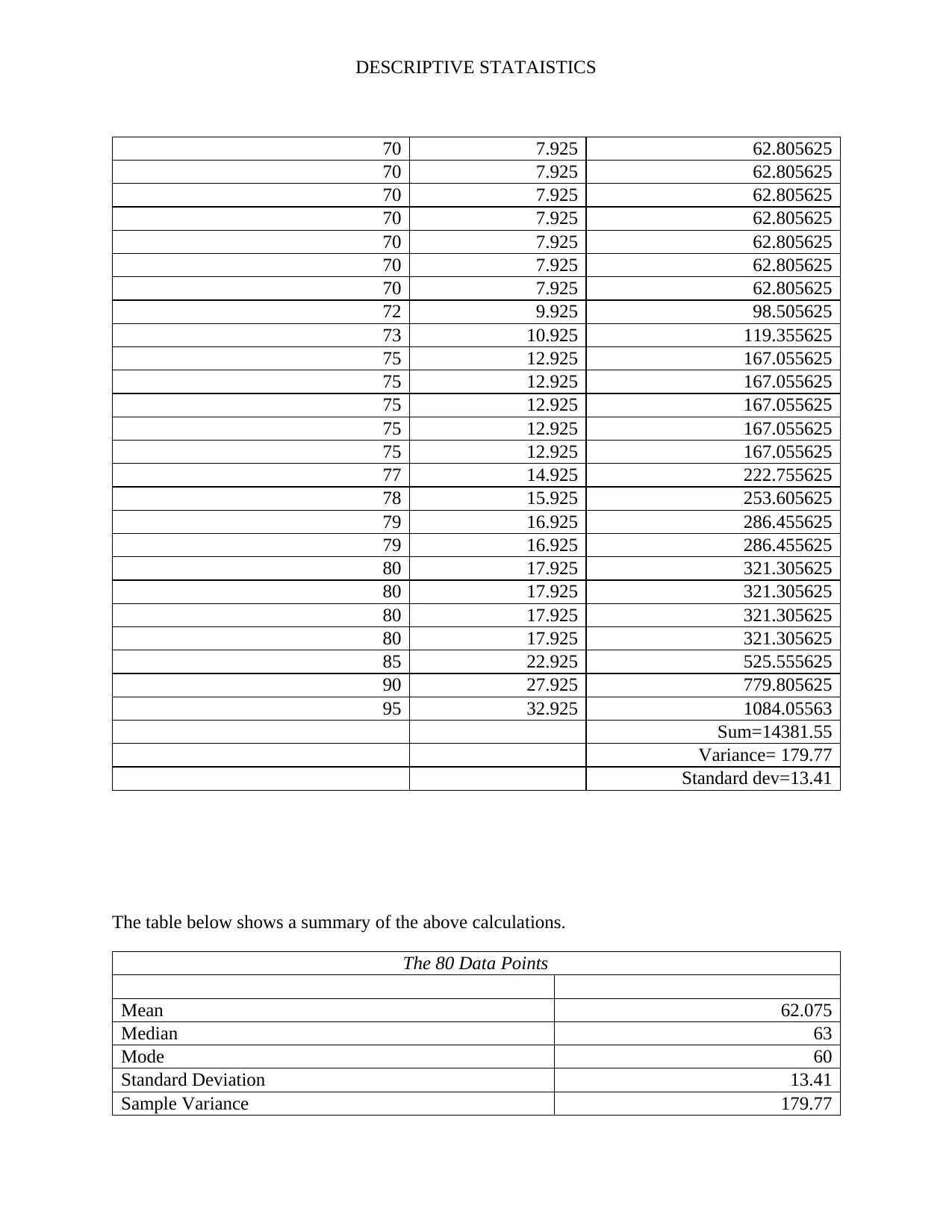
This assignment analyzes a dataset of 80 students' psychological well-being scores to investigate potential gender differences. It begins by classifying the data as a sample or population based on the context. The independent variable (gender) and dependent variable (level of psychological well-being, a continuous variable) are identified. A frequency distribution table is constructed, including absolute, cumulative absolute, and relative frequencies. Histograms are created to visualize the data. Measures of central tendency (mean, median, mode) and variability (range, variance, standard deviation) are calculated. Boxplots and stem-and-leaf displays are generated to represent the data visually, and conclusions are drawn regarding gender differences in well-being and the presence of outliers. The solution includes the R code used for generating the visualizations.




1 out of 19
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.