ICT707 Data Science: Exploring PySpark for Data Science Applications
VerifiedAdded on 2022/10/17
|13
|1910
|10
Report
AI Summary
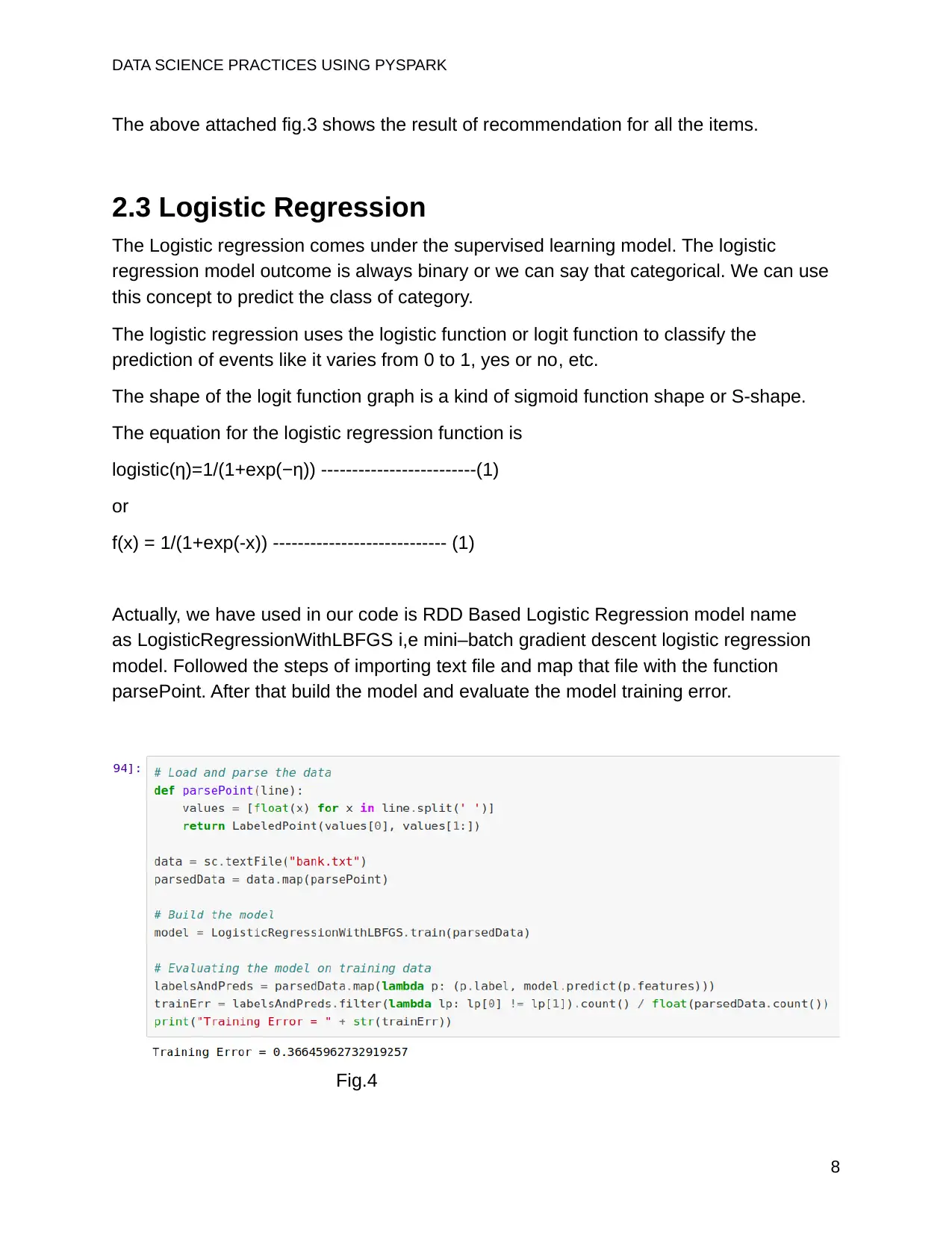
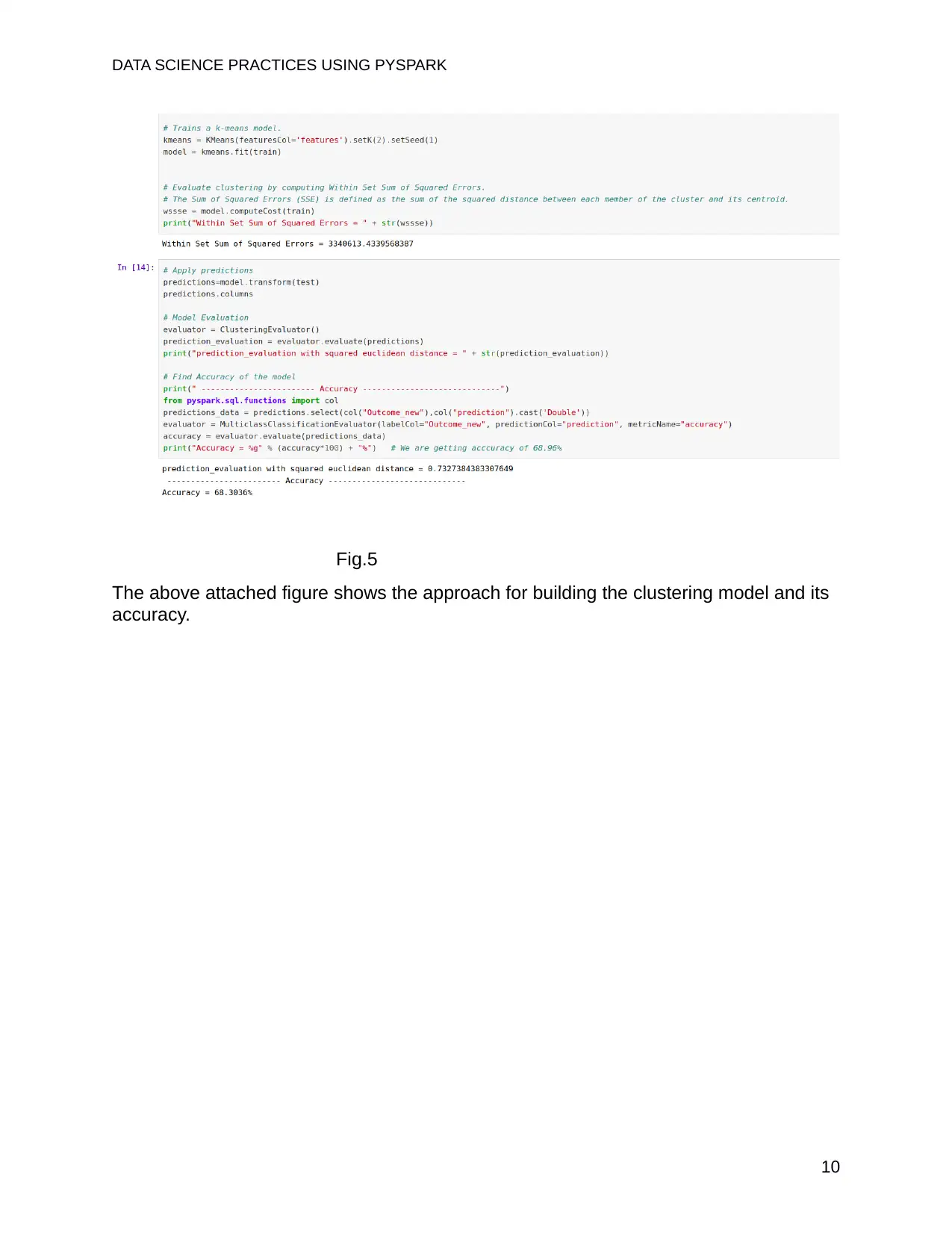
This report delves into the practical application of PySpark in data science, focusing on key concepts such as machine learning pipelines, collaborative filtering, logistic regression, and K-means clustering. The introduction highlights the significance of data science and the role of PySpark as a powerful tool for handling large-scale data processing. The report explores the Apache Spark system, RDDs, DataFrames, and MLlib, providing a foundation for understanding the core components. Machine learning pipelines, including Transformers, Estimators, and DataFrames, are discussed in detail, along with their practical applications. The report then examines collaborative filtering for building recommendation engine systems, using the ALS method, and presents the model building process and prediction results. Logistic regression, a supervised learning model, is explained, and its implementation with RDD-based Logistic RegressionWithLBFGS is demonstrated. Finally, K-means clustering, an unsupervised learning model, is explored, including its application, model evaluation, and accuracy assessment. The conclusion summarizes the key insights gained from using PySpark in real-life data science problems. References to relevant sources are also provided.










1 out of 13
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.