Data Science Project: Child Mortality Analysis and Data Wrangling
VerifiedAdded on 2020/04/07
|27
|1602
|56
Project
AI Summary
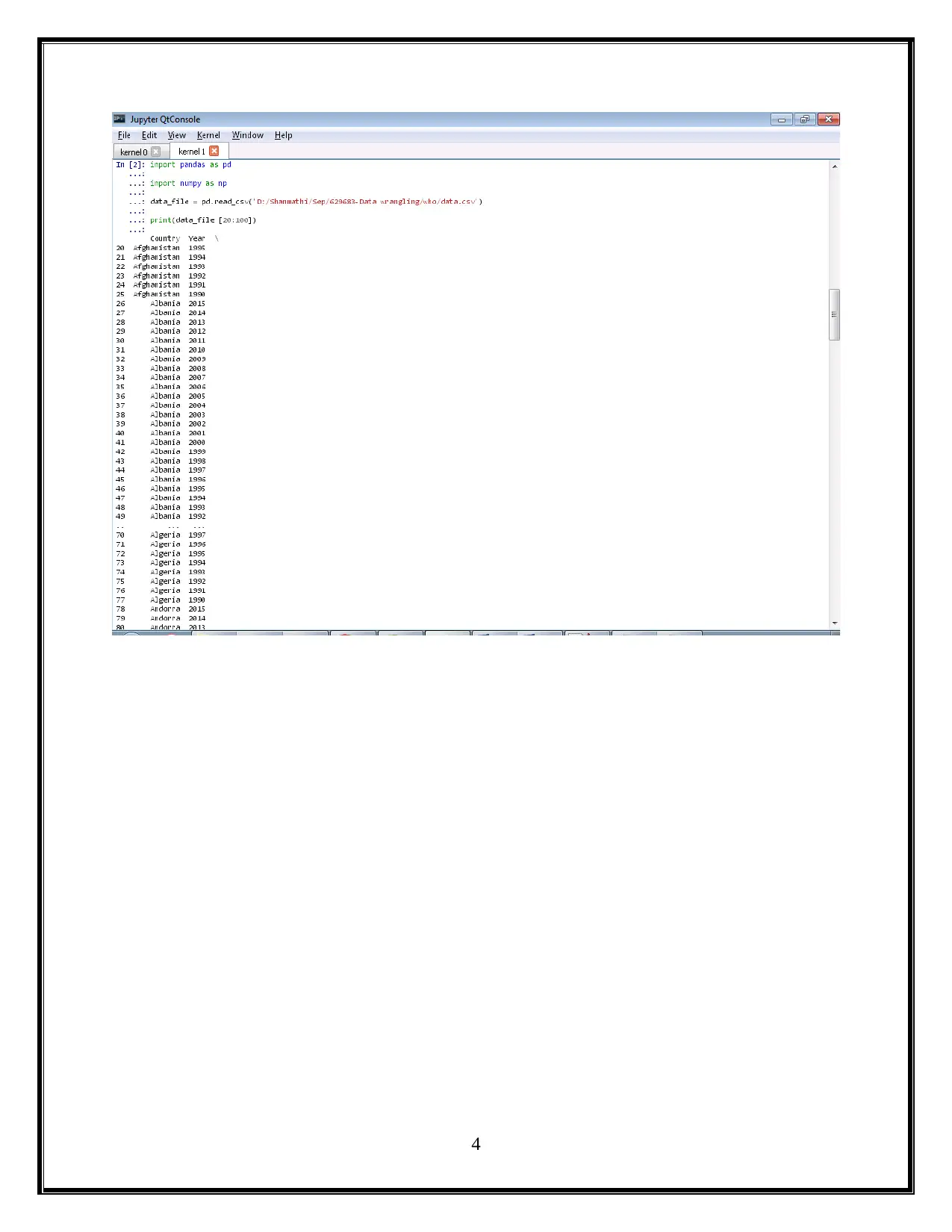
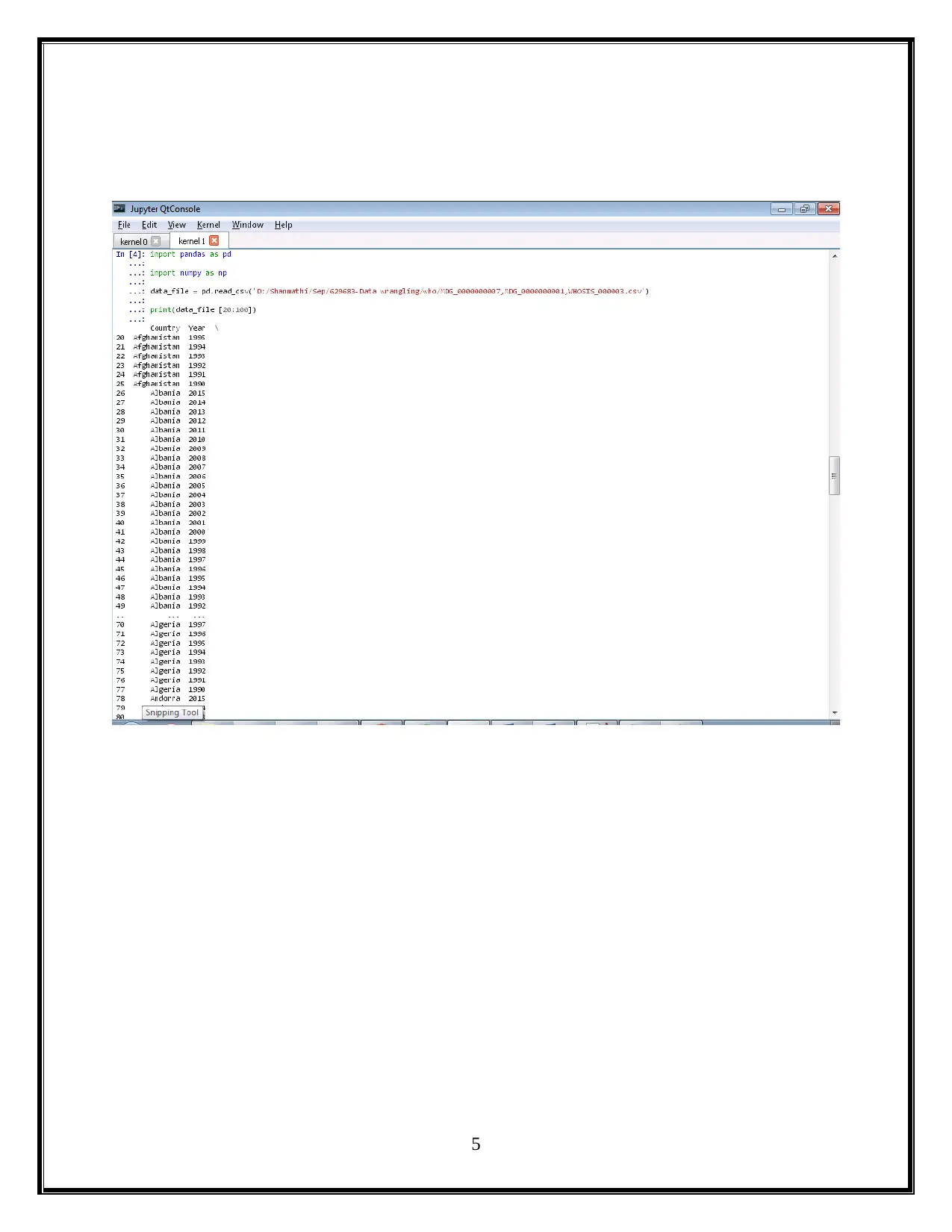
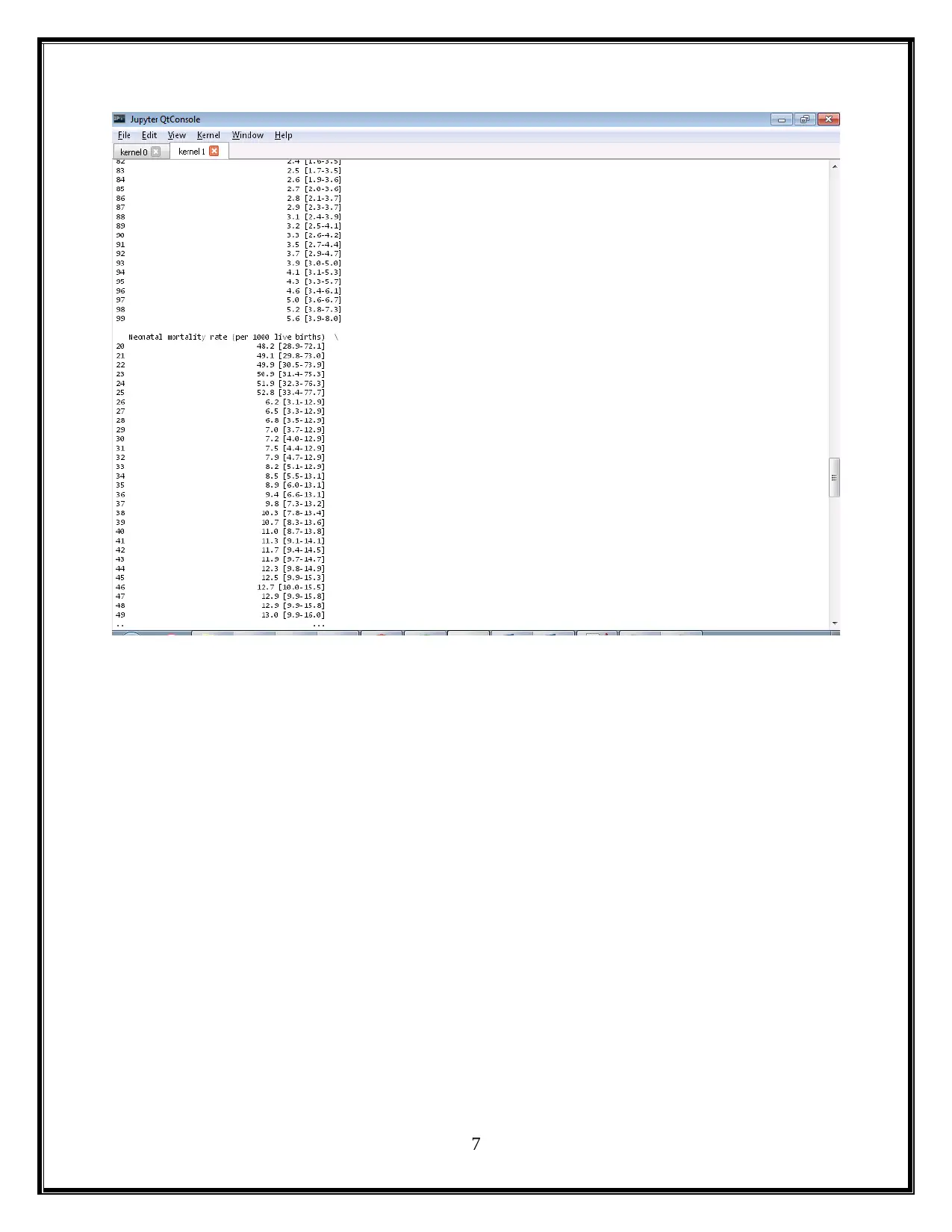
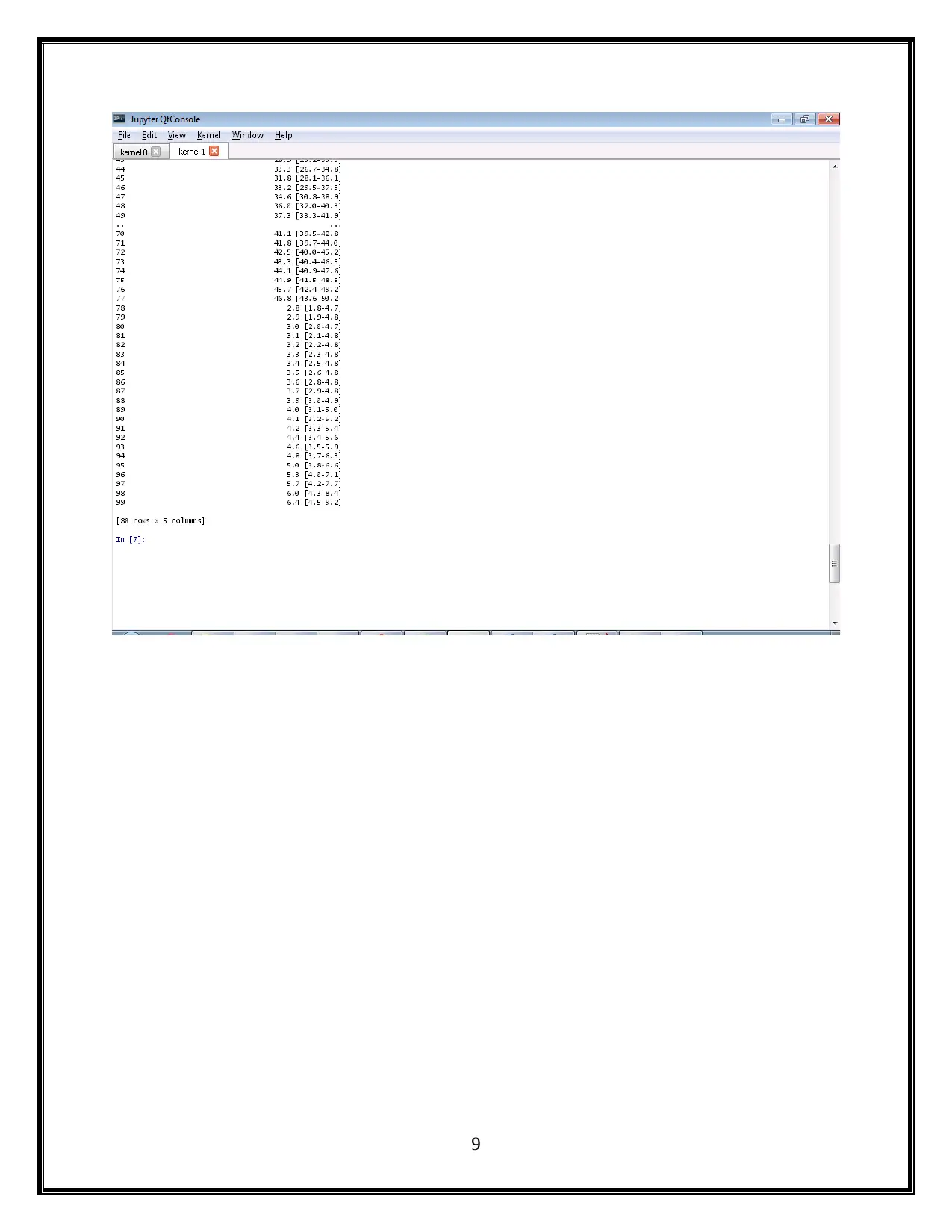
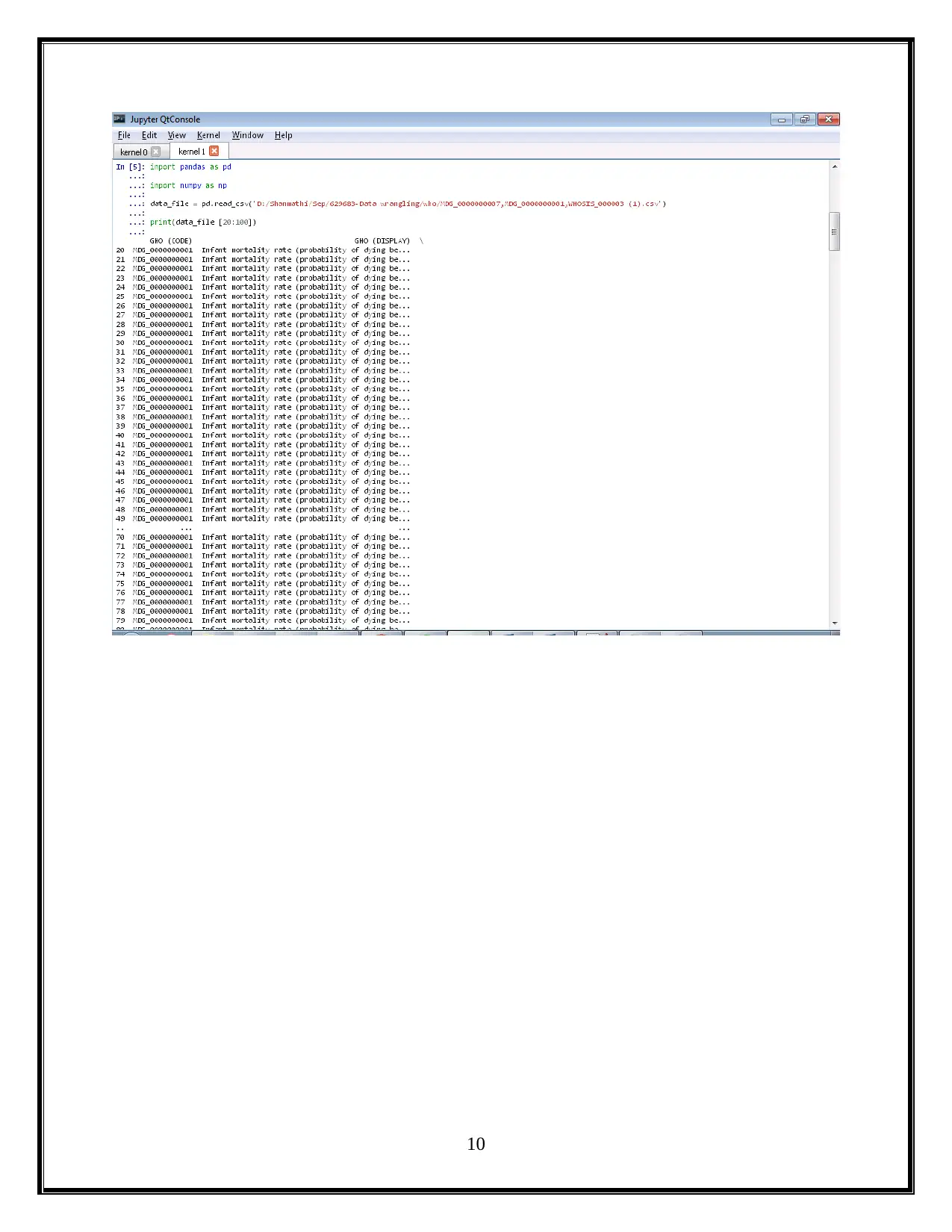
This project utilizes Python and Jupyter notebooks to analyze child mortality data from WHO. The assignment is divided into two parts: Part 1 focuses on data wrangling of CSV files, generating Python code to display mortality rates for different countries and years, and creating visualizations using libraries like Pandas and Matplotlib. Part 2 involves exploring nested JSON files to further analyze mortality rates, identify the top causes of child mortality (including pneumonia, birth complications, and diarrhea), and discuss potential solutions such as improved access to healthcare, nutrition, and sanitation. The project concludes with a summary of the findings and references relevant sources.







1 out of 27


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.