Quantitative Analysis of Business Project: Analysis & Findings
VerifiedAdded on 2022/10/04
|6
|1425
|19
Project
AI Summary
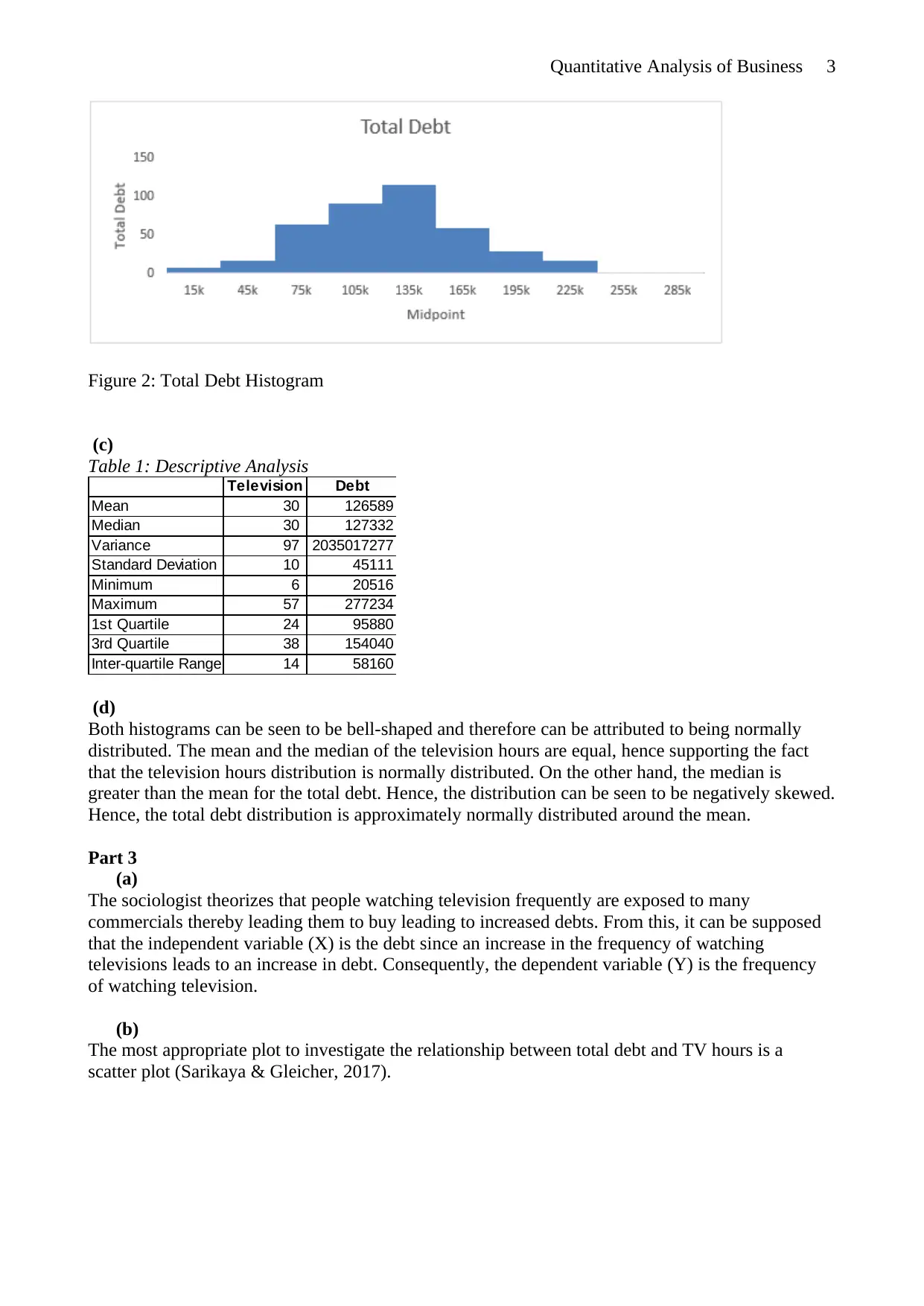
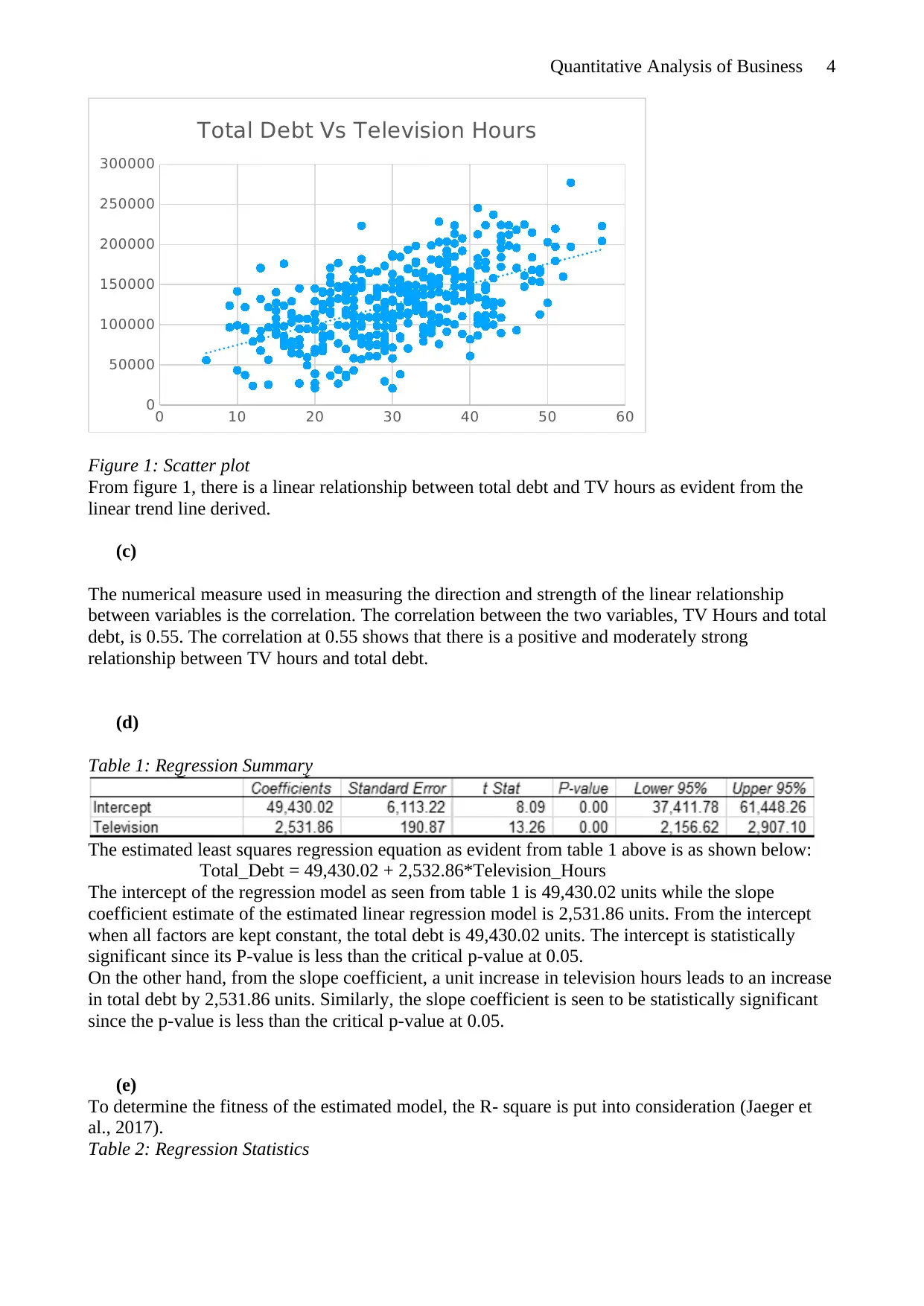
This assignment is a comprehensive quantitative analysis project focused on business applications. The project utilizes an online survey method to collect data, followed by a random sampling technique to ensure a representative sample. The analysis involves creating histograms to visualize data distributions, with a class size of 10 deemed appropriate for the dataset's size. Descriptive statistics, including mean and median, are calculated to understand the data's characteristics. A scatter plot is used to investigate the relationship between television viewing hours and total debt, revealing a positive correlation. Regression analysis is performed to quantify this relationship, resulting in a regression equation and statistical significance tests. The findings support the theory that increased television viewing is linked to higher debt levels due to exposure to commercials, aligning with existing research on the topic. The project concludes by interpreting the results and discussing the implications for consumer behavior and debt accumulation.




1 out of 6
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.