Quantitative Analysis for Business (QAB 105) Assignment Solution
VerifiedAdded on 2020/05/11
|7
|862
|183
Homework Assignment
AI Summary
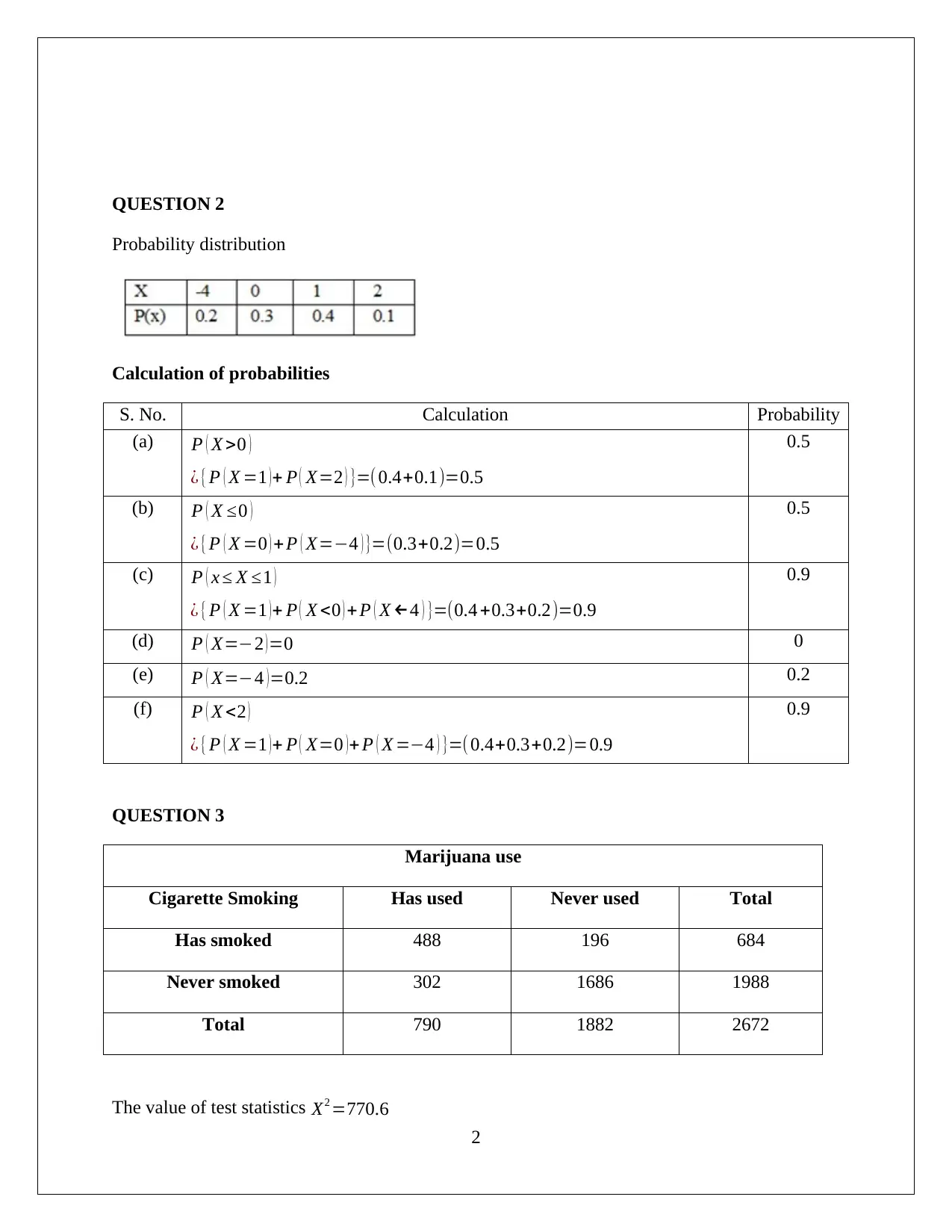
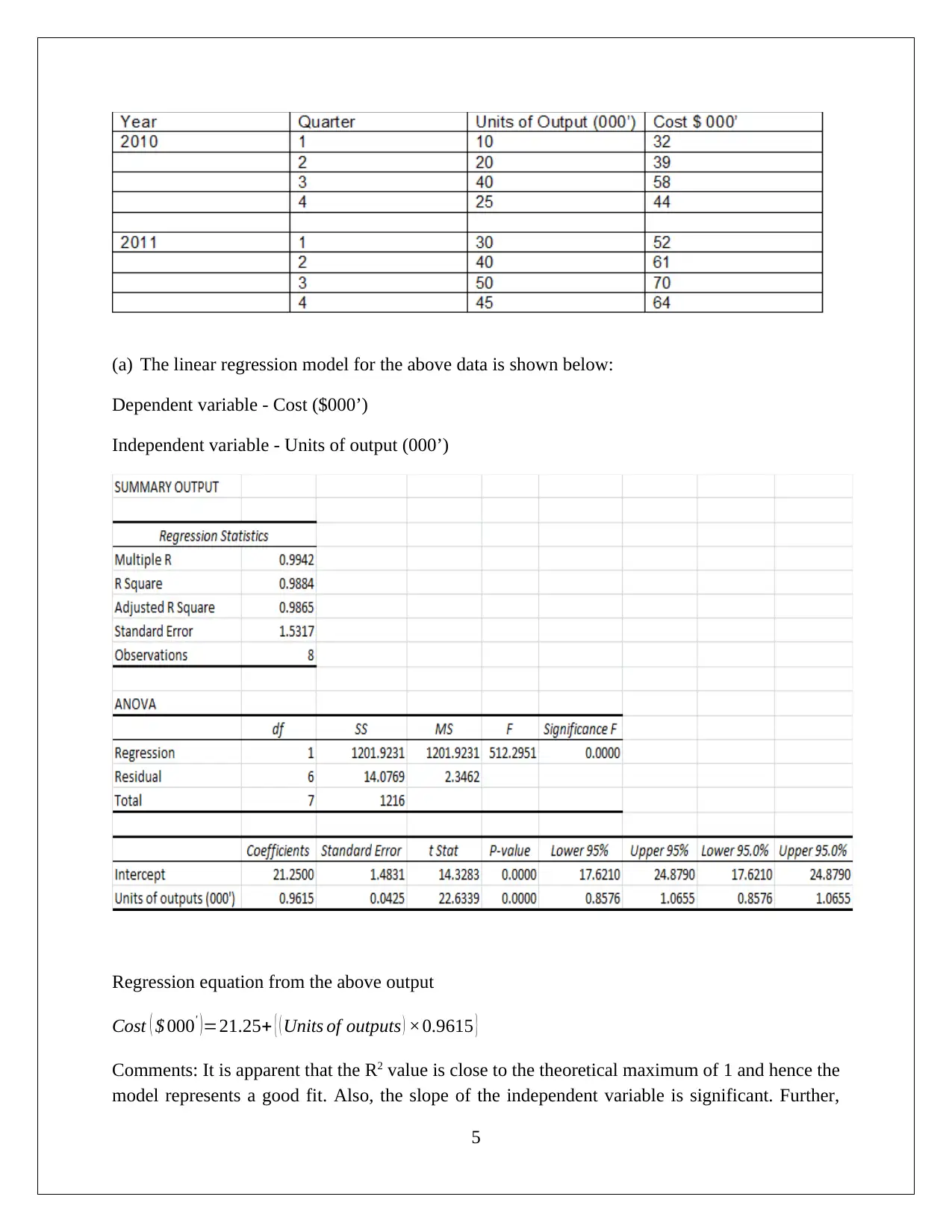
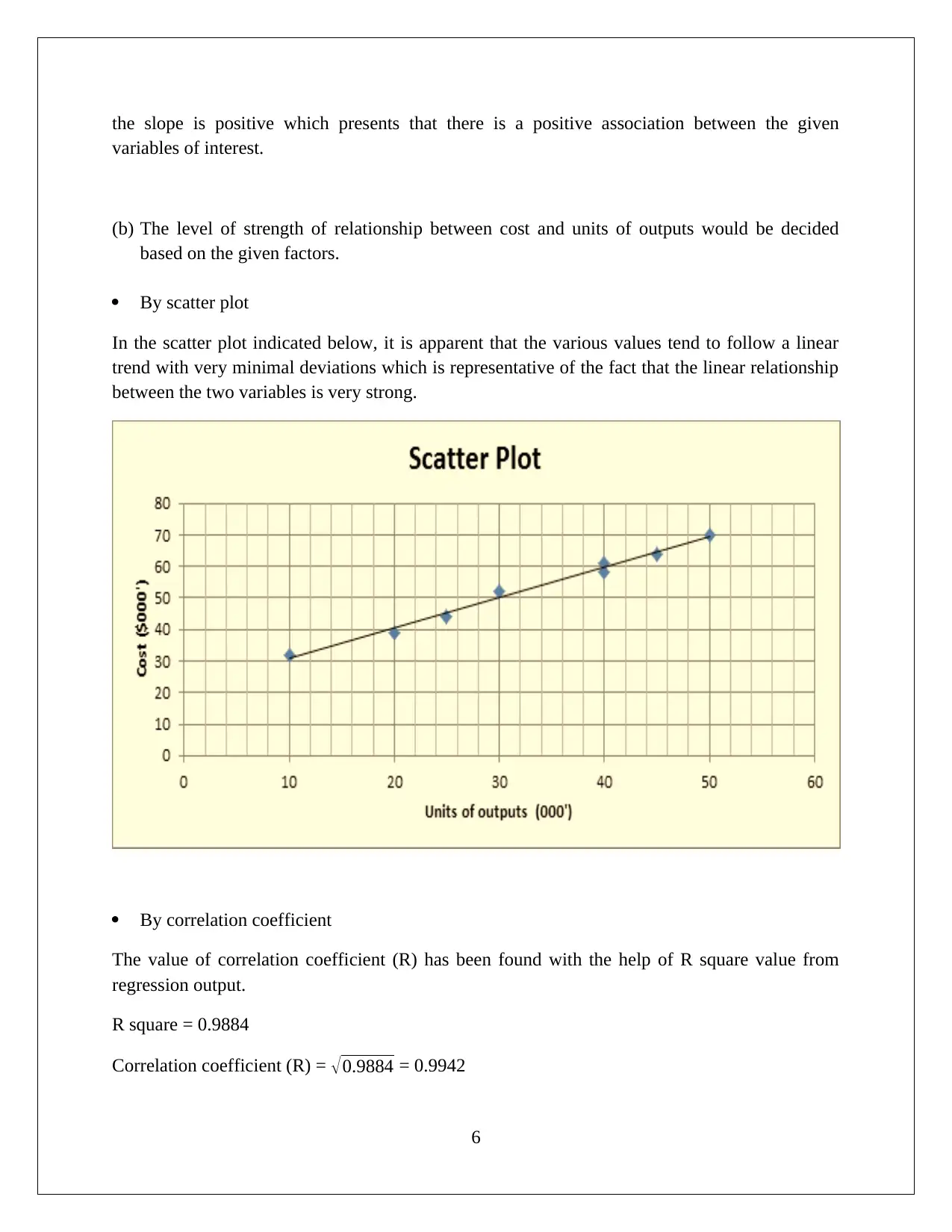
This assignment solution for QAB 105 (Quantitative Analysis for Business) covers various statistical concepts. Question 1 focuses on creating a random sample of retailers and calculating a 95% confidence interval for the proportion of retailers selling below a recommended price. Question 2 involves calculating probabilities. Question 3 explores the association between cigarette smoking and marijuana use using hypothesis testing and p-values. Question 4 investigates whether homes near a city have higher values than the mean, also employing hypothesis testing and t-statistics. Finally, Question 5 presents a linear regression model to analyze the relationship between cost and units of output, including an interpretation of the R-squared value, the significance of the slope, and the strength of the relationship based on a scatter plot and correlation coefficient.




1 out of 7
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.