Quantitative Methods for Business: Statistical Analysis Assignment
VerifiedAdded on 2022/12/27
|9
|1606
|56
Homework Assignment
AI Summary
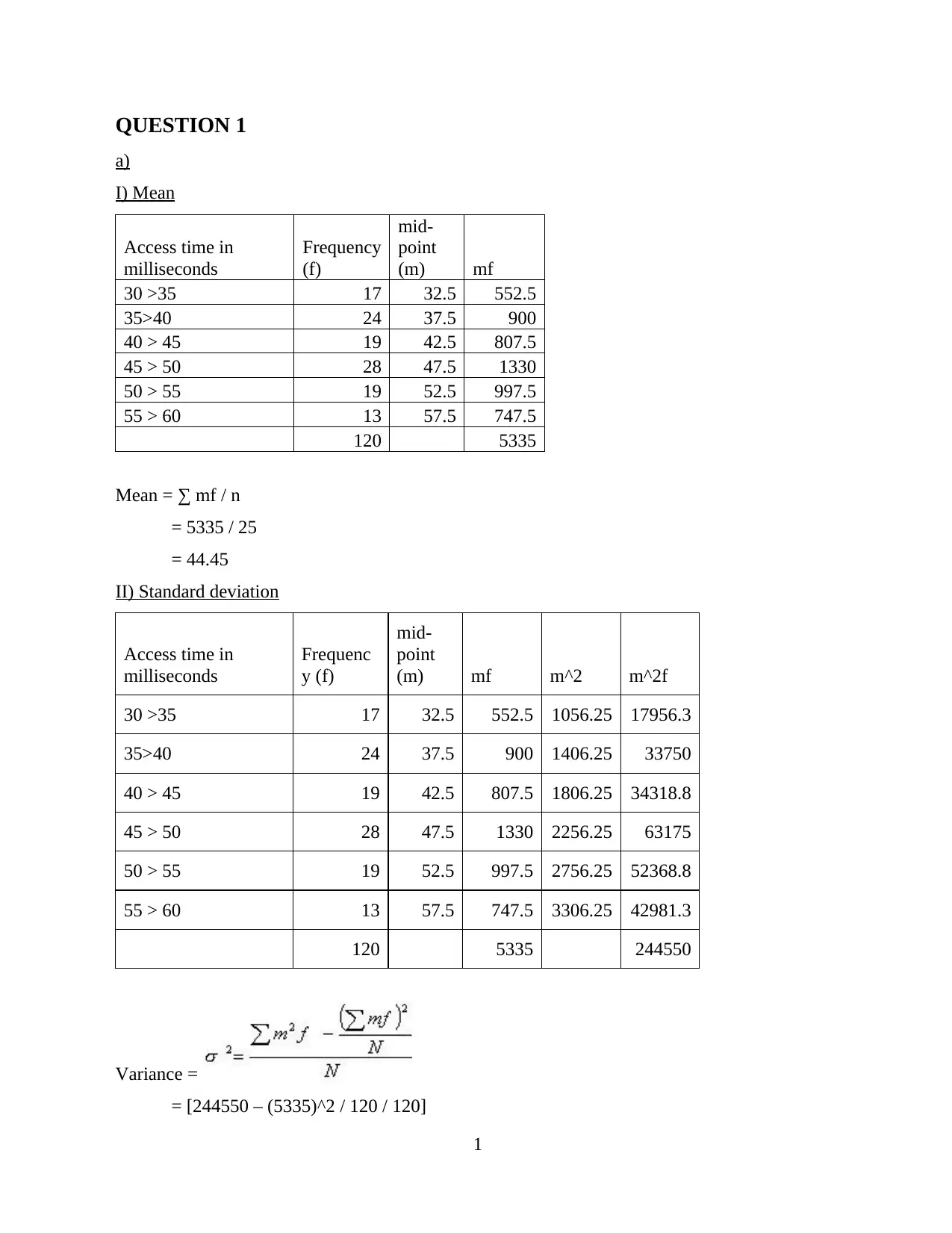
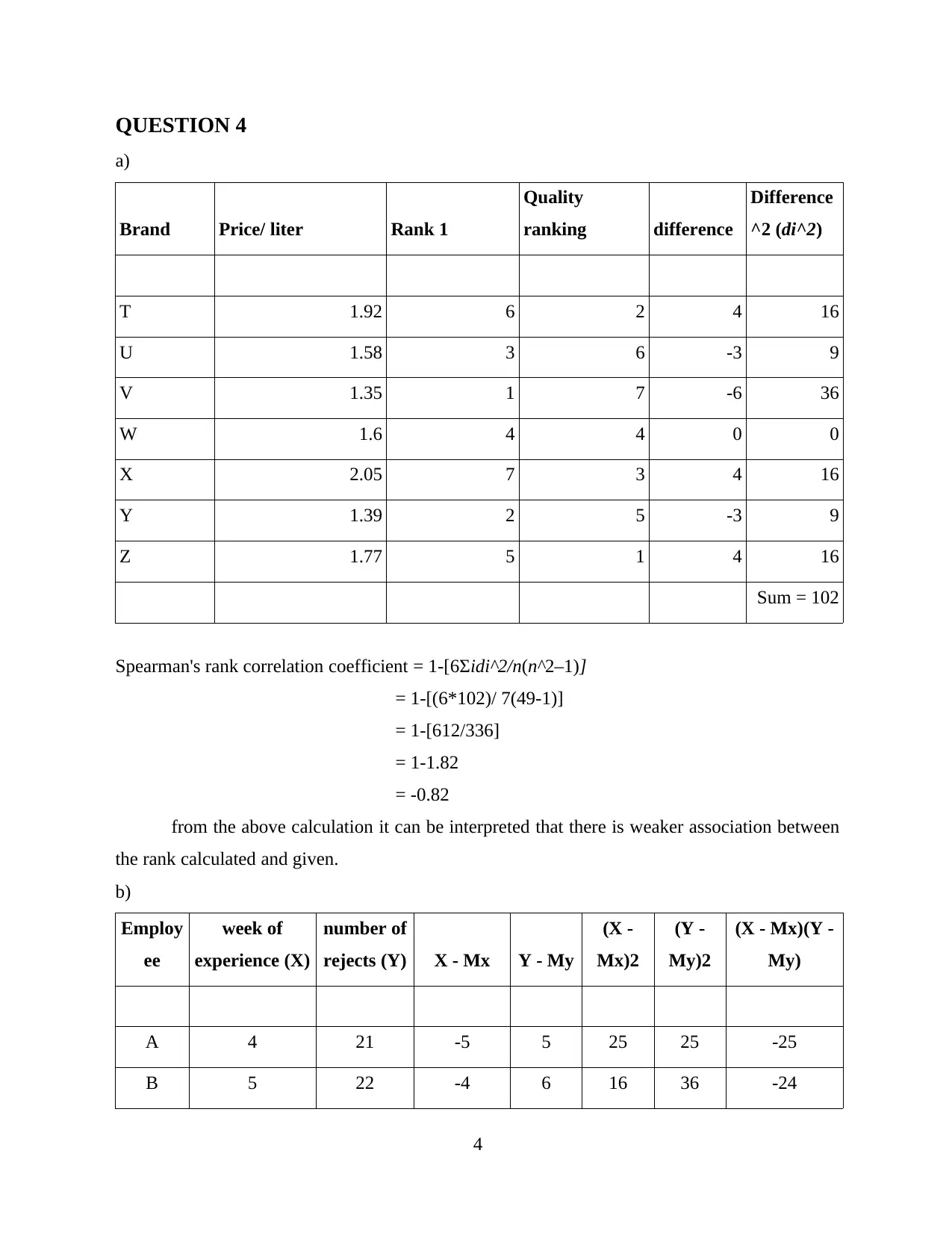
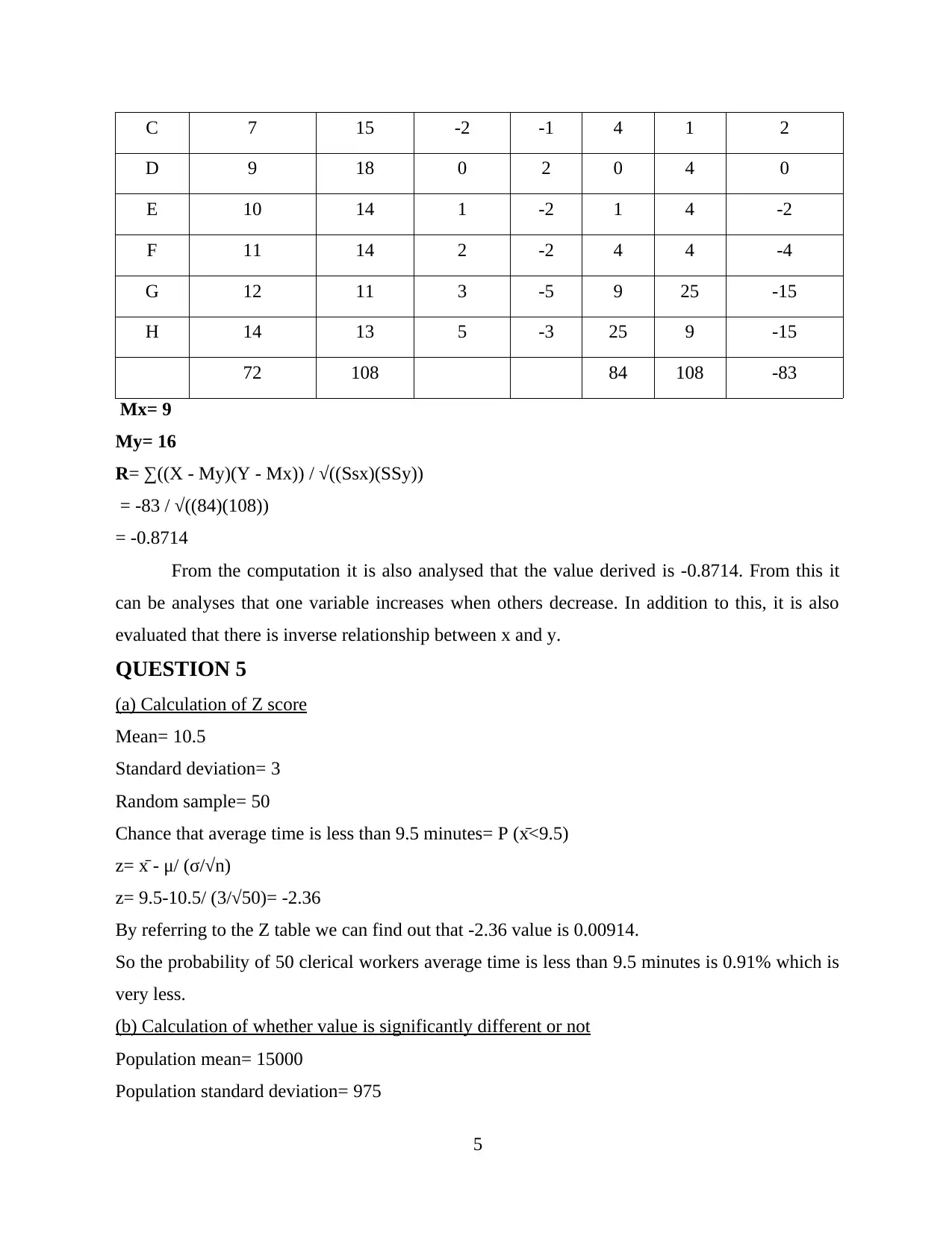
This assignment delves into quantitative methods used in a business context, covering several key areas of statistical analysis. The solution begins with the calculation and interpretation of the mean and standard deviation from a frequency distribution table, demonstrating how to analyze data related to access time in a computer disc system. It then explores different sampling methods, including simple random sampling, quota sampling, cluster sampling, and systematic sampling, with examples illustrating their application. The assignment continues with the calculation of cumulative frequency. Further analysis includes the calculation of Spearman's rank correlation coefficient and the interpretation of the relationship between variables. Finally, the assignment concludes with the calculation of Z-scores and P-values to determine statistical significance, including examples related to clerical worker average time and population mean comparisons, providing a comprehensive overview of statistical techniques relevant to business analysis.






1 out of 9
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.