Statistics Report: Statistical Analysis of Quantitative Data, Results
VerifiedAdded on 2022/09/15
|11
|724
|26
Report
AI Summary
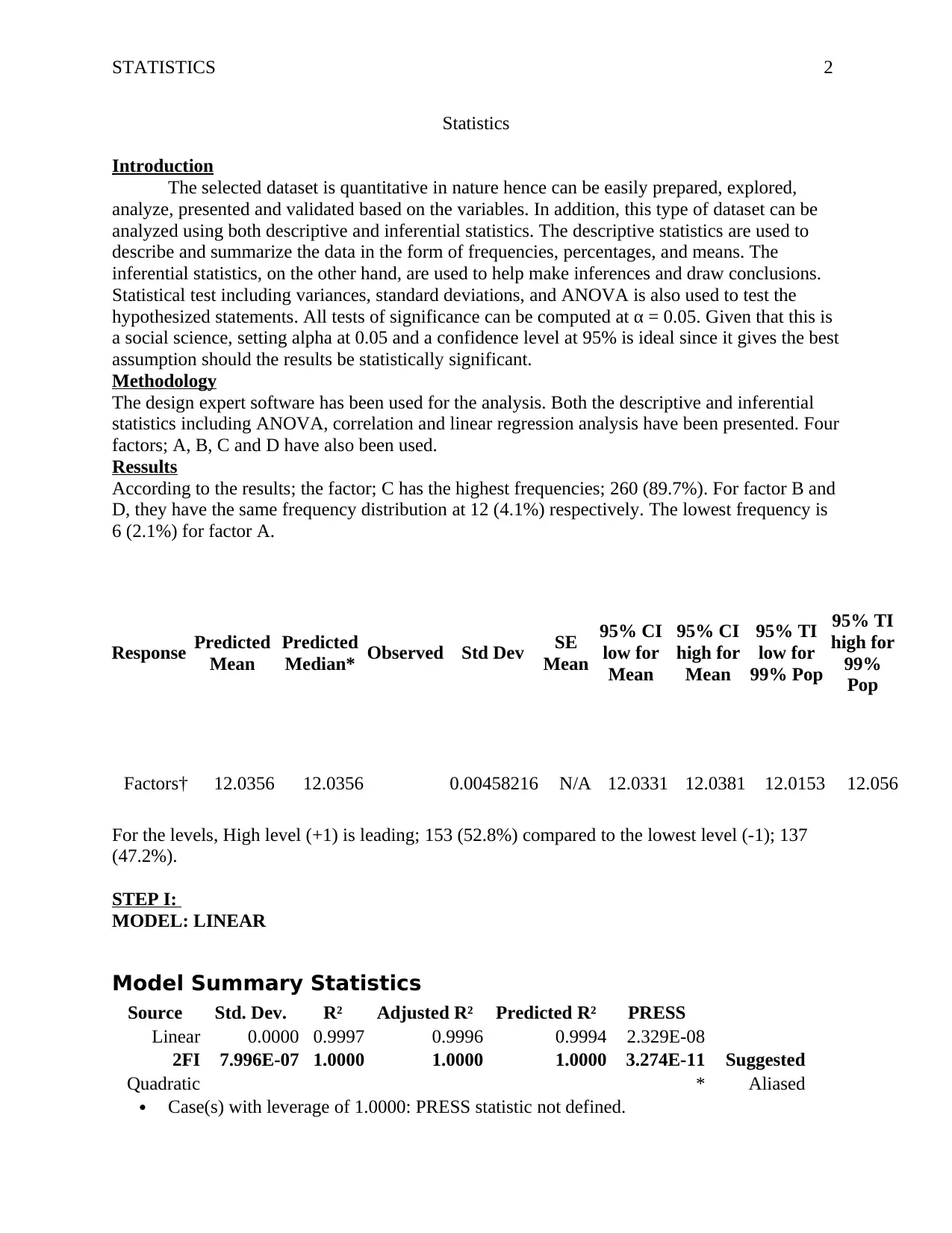
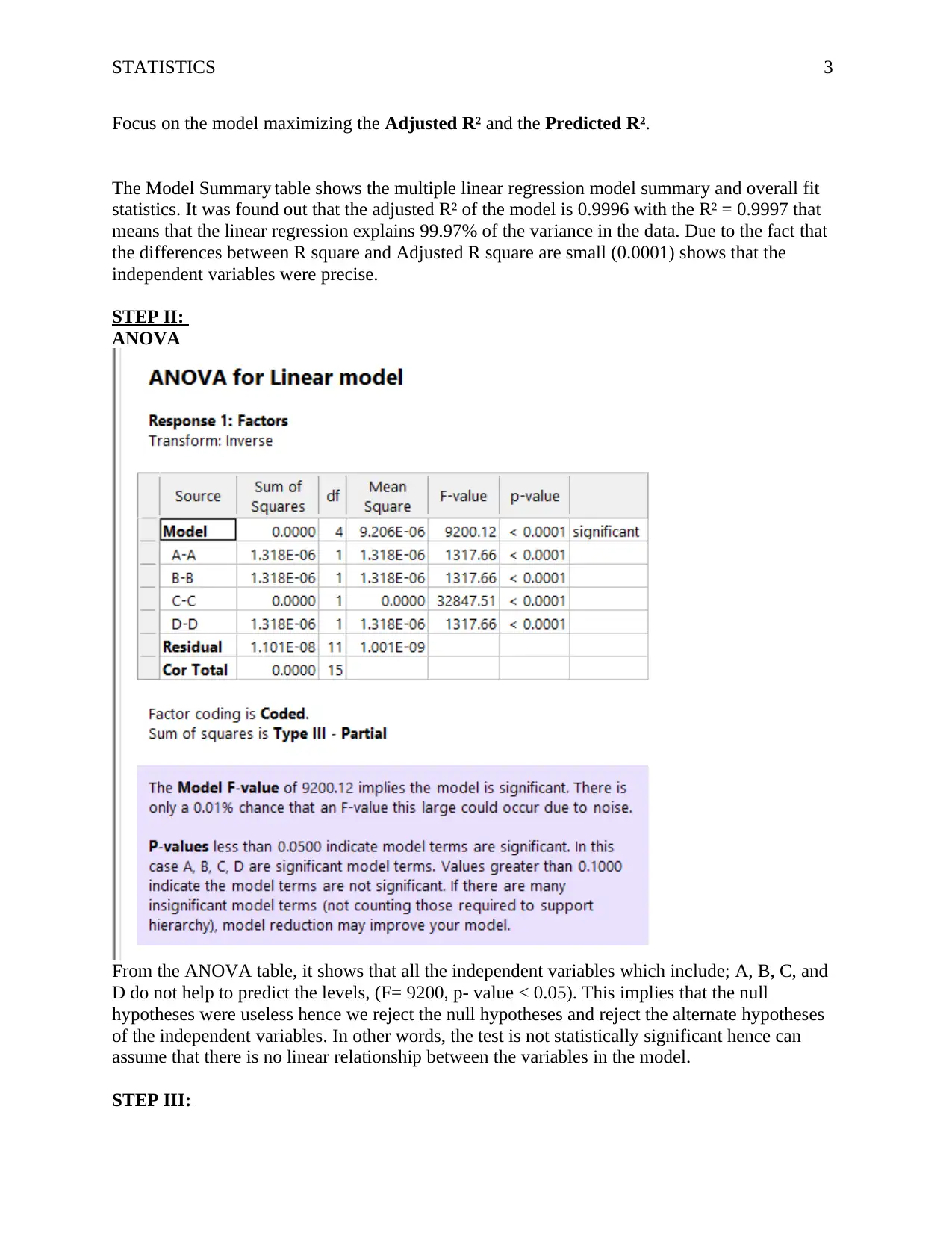
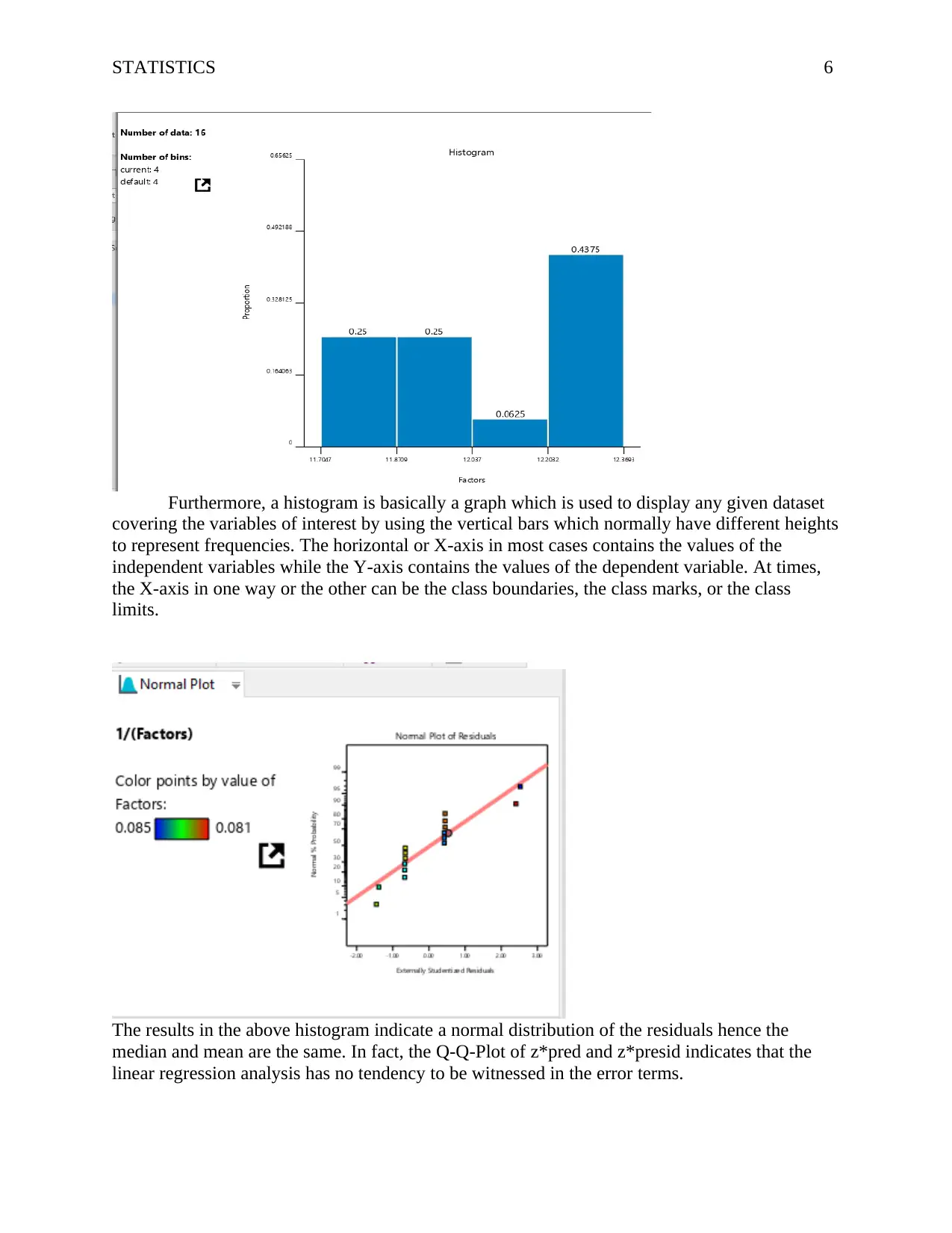
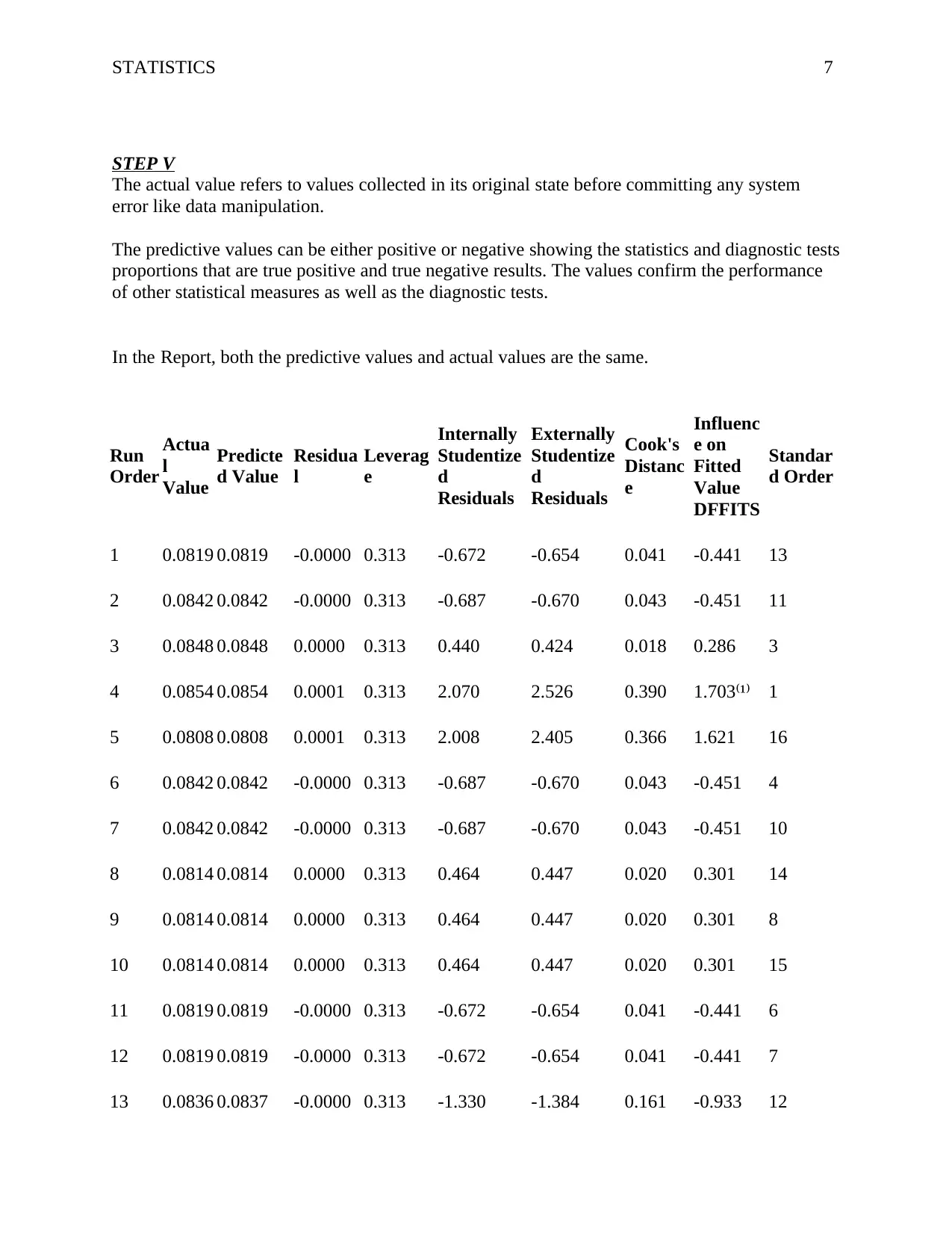
This statistics report presents an analysis of quantitative data, utilizing both descriptive and inferential statistical techniques. The analysis employs Design Expert software to explore the dataset, focusing on factors A, B, C, and D. The results highlight that factor C has the highest frequency, followed by factors B and D, with factor A having the lowest frequency. The report includes a detailed breakdown of the observed and predicted values, along with key statistical metrics such as adjusted R-squared, C.V. %, and Adeq Precision. The conclusion emphasizes that the linear regression model explains a significant portion of the variance in the data (99.97%), with all independent variables contributing to the prediction of levels. Additionally, the collinearity diagnostics indicate no multicollinearity issues. The report also discusses the coefficient estimate and the intercept in the orthogonal design. Finally, the report suggests future scopes, including adding more factors and variables for a more detailed prediction and transforming variables to refine coefficient estimates.







1 out of 11
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.