Homework: Confidence Intervals & Quantitative Statistical Methods
VerifiedAdded on 2023/05/30
|11
|2537
|345
Homework Assignment
AI Summary
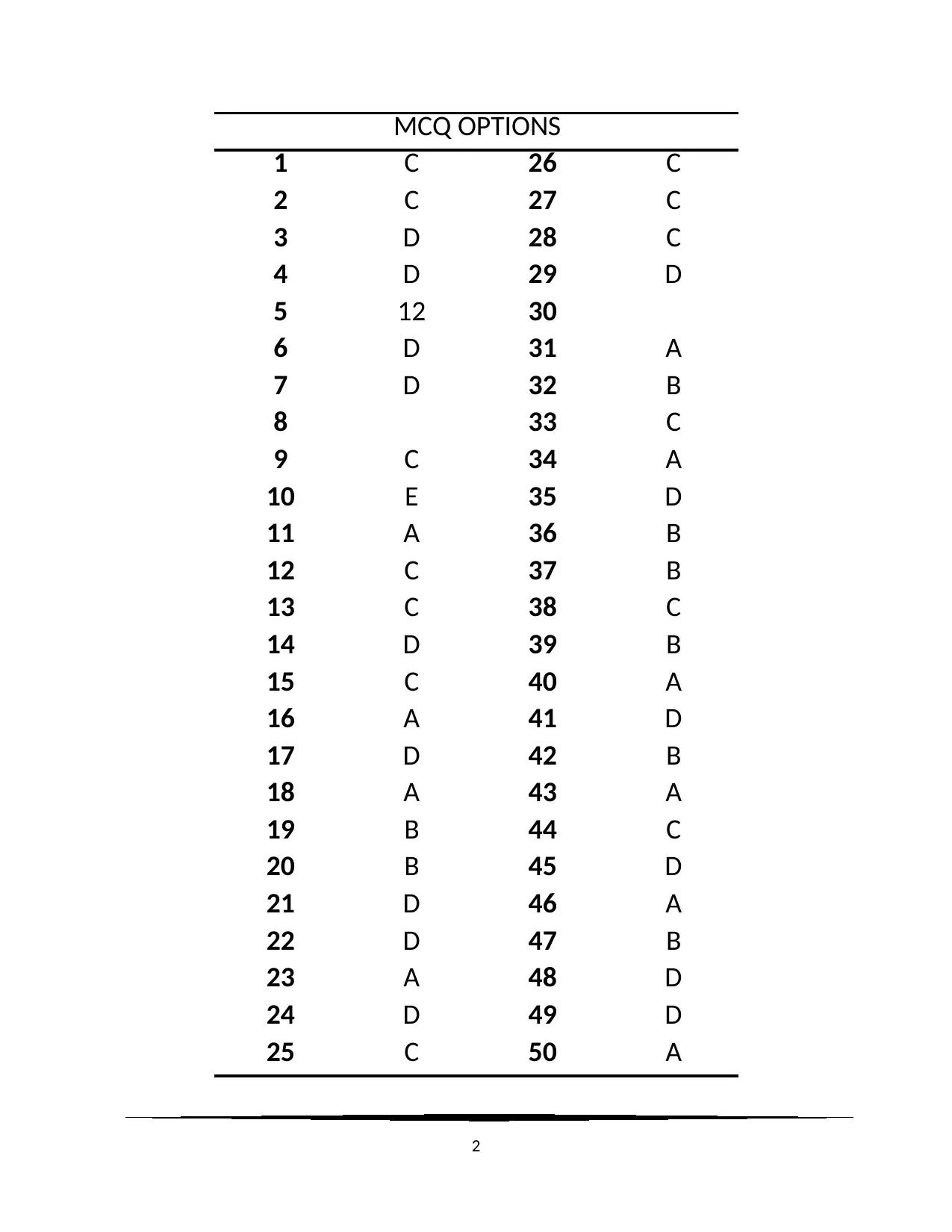
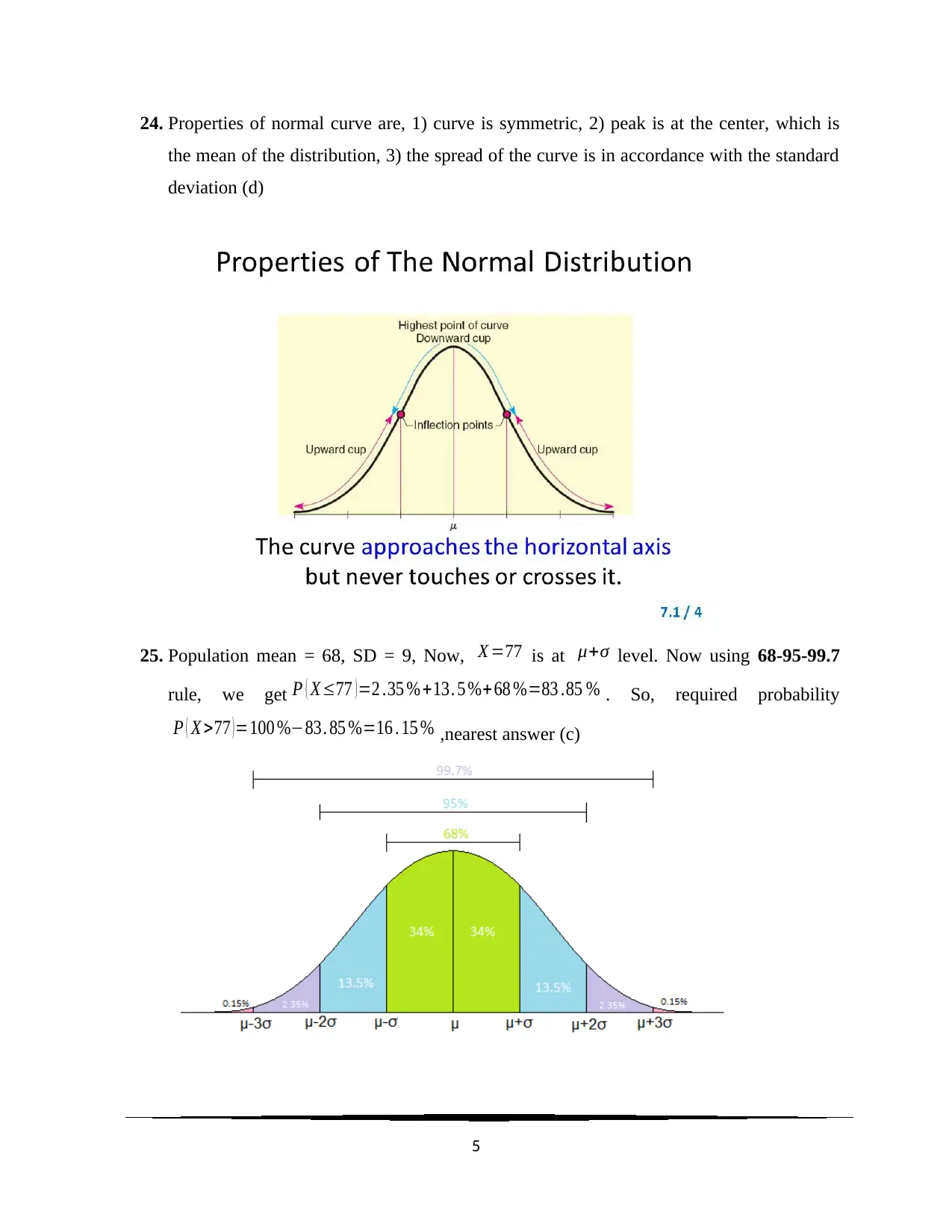
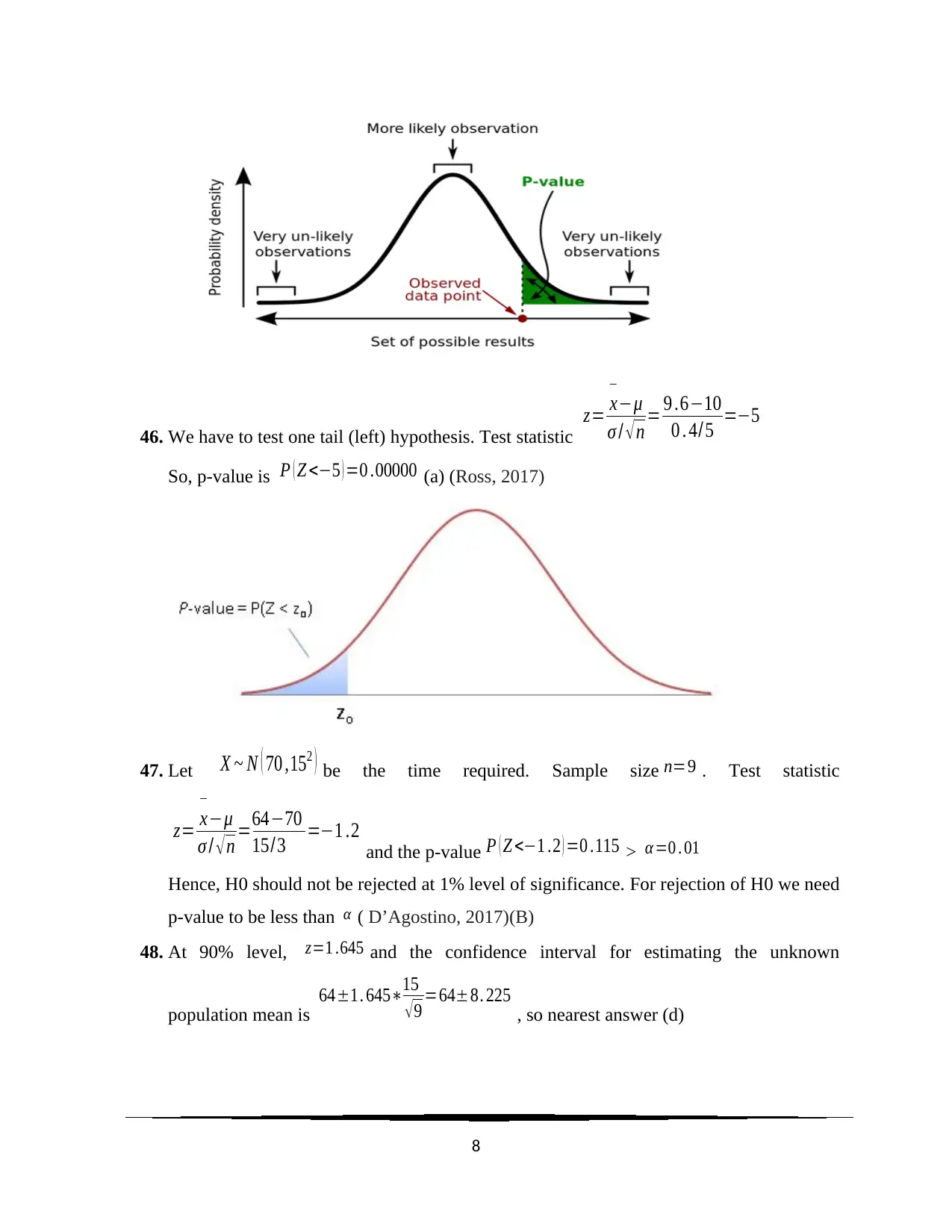
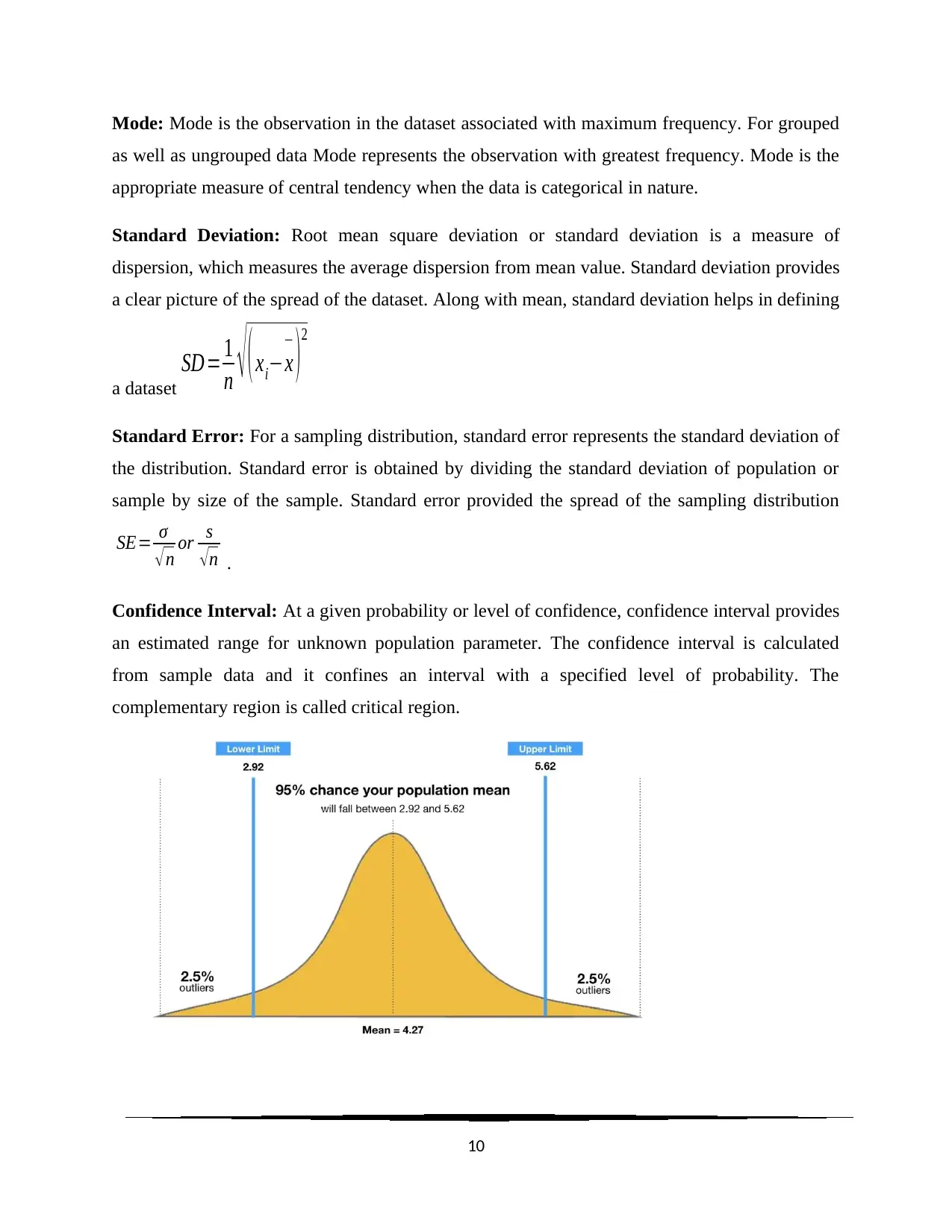
This document presents a comprehensive solution to a statistics homework assignment focusing on quantitative methods. It includes multiple-choice questions covering topics such as multivariate analysis, measures of central tendency (mean, median, mode), standard deviation, confidence intervals, and hypothesis testing. The solutions are detailed and provide explanations for each answer, referencing statistical rules and theorems where applicable. Key concepts like the Central Limit Theorem, p-values, and the Chi-Square test are also addressed. The assignment also includes definitions of statistical terms such as mean, median, mode, standard deviation, standard error and confidence interval. Desklib provides a platform for students to access this and other solved assignments and past papers.







1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.