Statistics in R: Airline Customer Satisfaction Analysis Report - Data
VerifiedAdded on 2022/08/30
|13
|1059
|18
Report
AI Summary
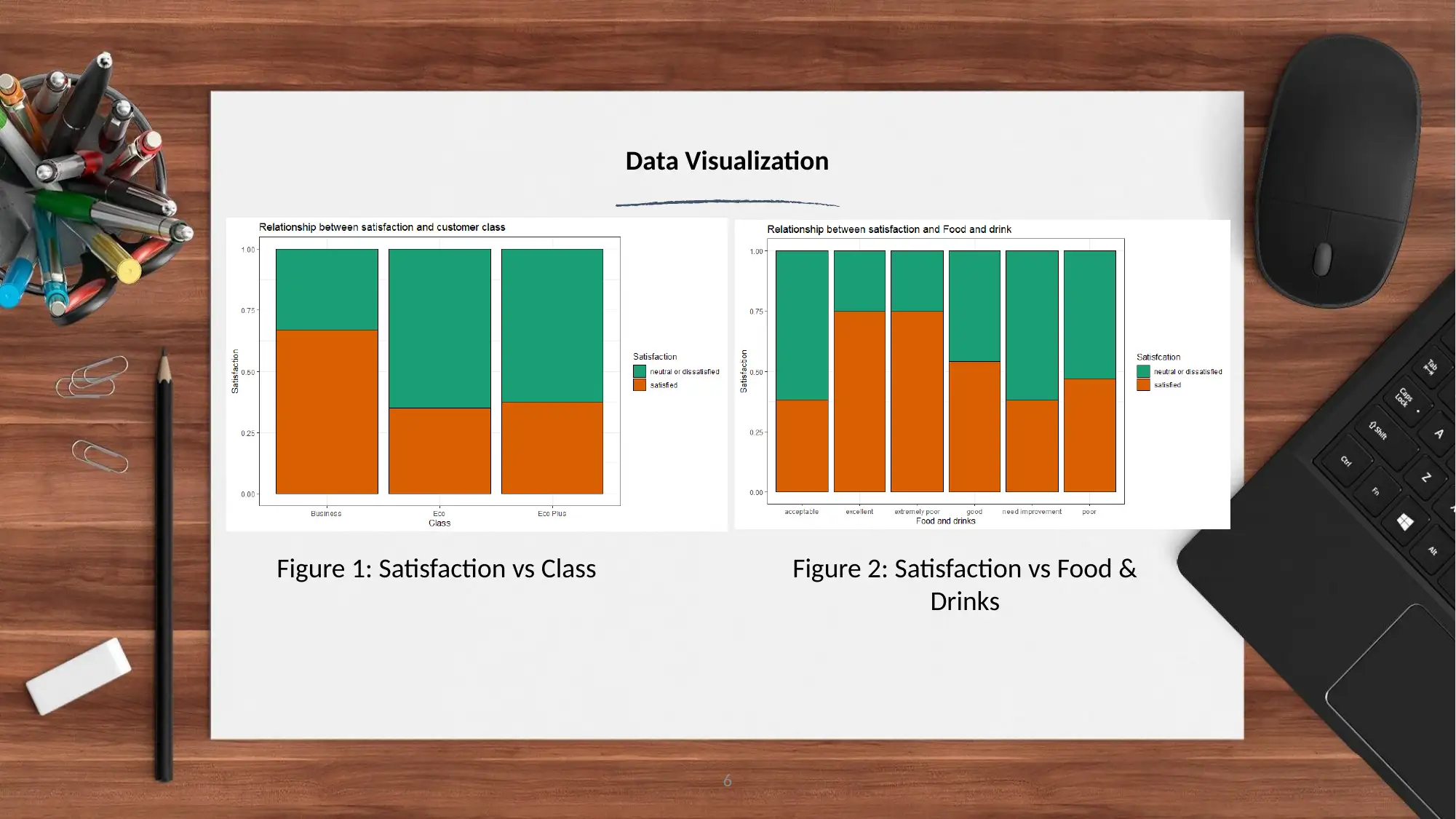
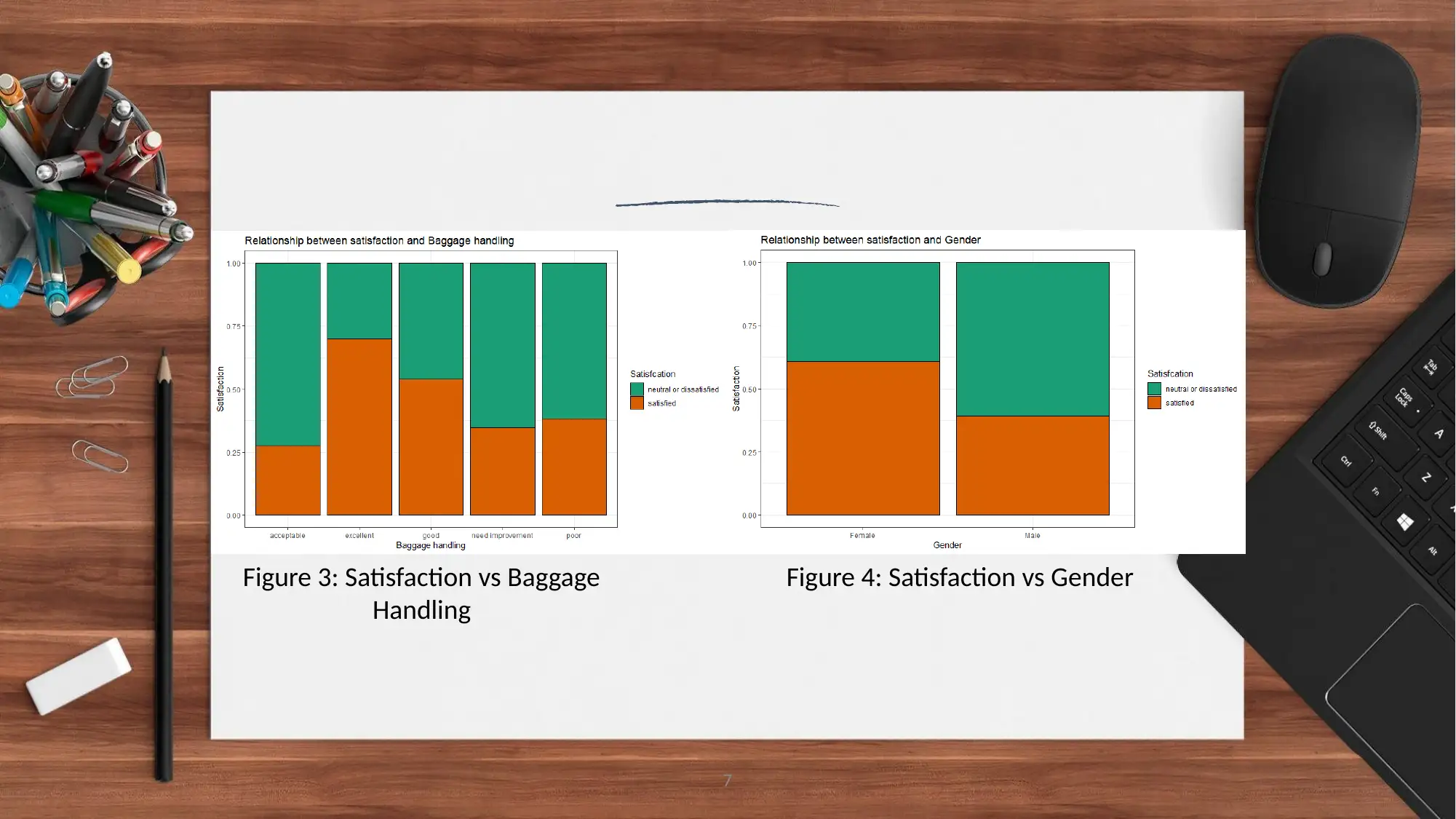
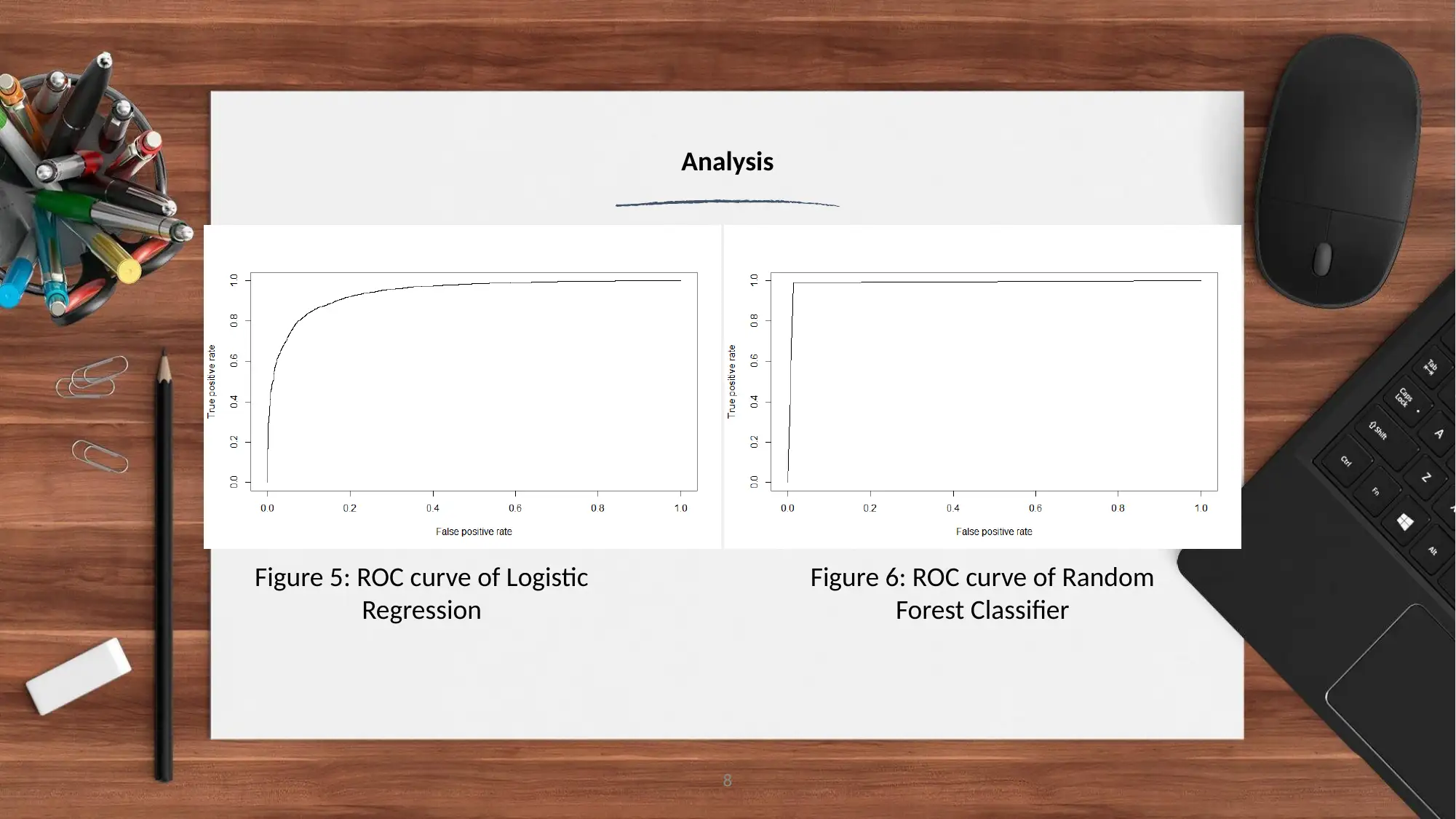
This report analyzes airline customer satisfaction data using the R programming language. The analysis focuses on customer feedback from the airline industry to predict customer satisfaction levels. The study employs various machine learning algorithms, including logistic regression and random forest classifiers, to build predictive models. Data visualization techniques are used to explore relationships between variables such as customer class, food and drinks, baggage handling, and gender, and their impact on satisfaction. The report presents the model outputs, including confusion matrices and statistical analyses, highlighting the superior performance of the random forest classifier. The conclusion emphasizes the importance of data quality and suggests future improvements, such as incorporating additional machine learning models and generating more datasets. Recommendations are provided to improve customer facilities, including enhancements to food and beverage services, baggage handling, and in-flight entertainment, aiming to increase overall customer satisfaction.









1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.