Regression Analysis: Examining Tax and Deregulation Impact
VerifiedAdded on 2023/06/11
|16
|1898
|150
Homework Assignment
AI Summary
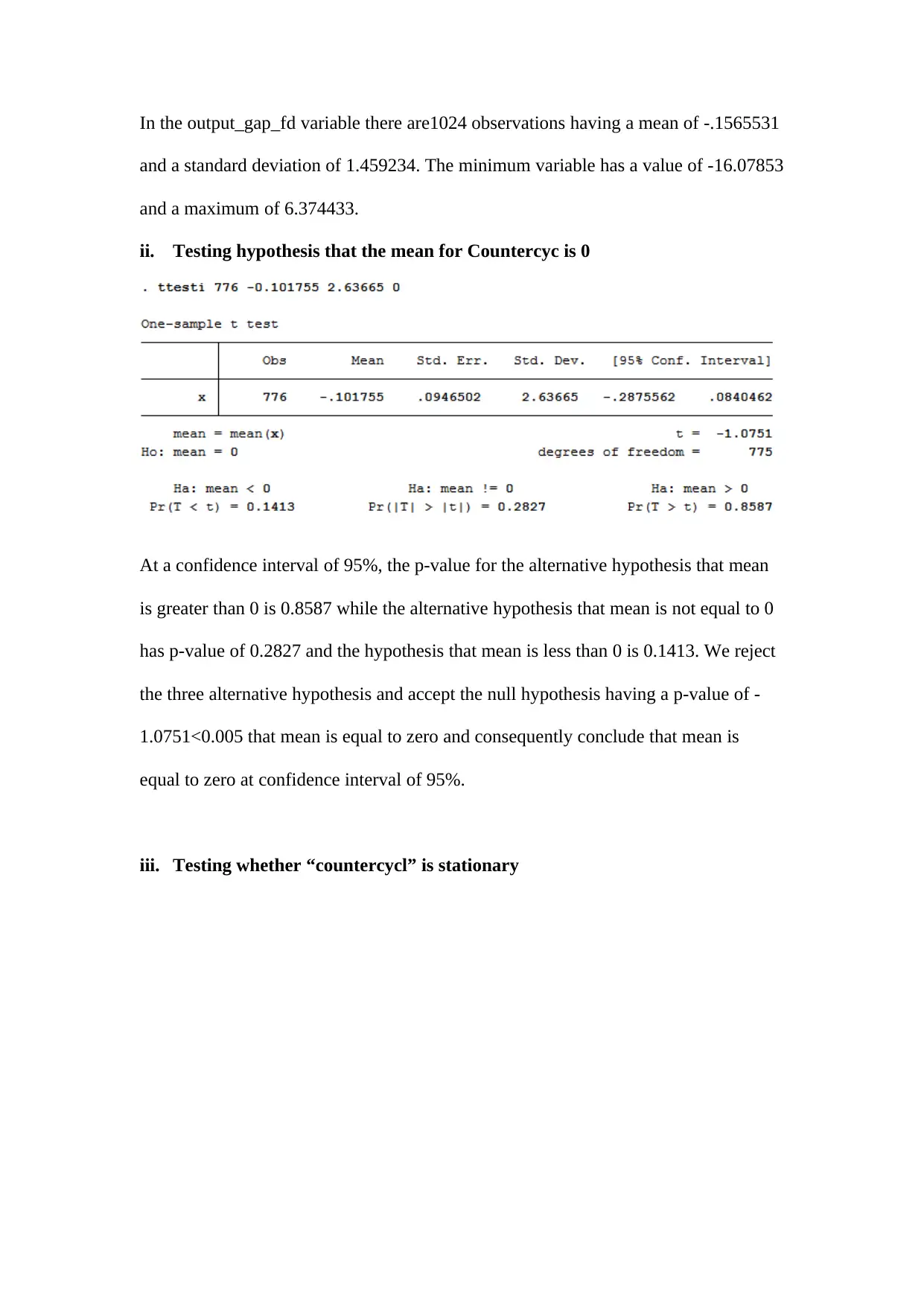
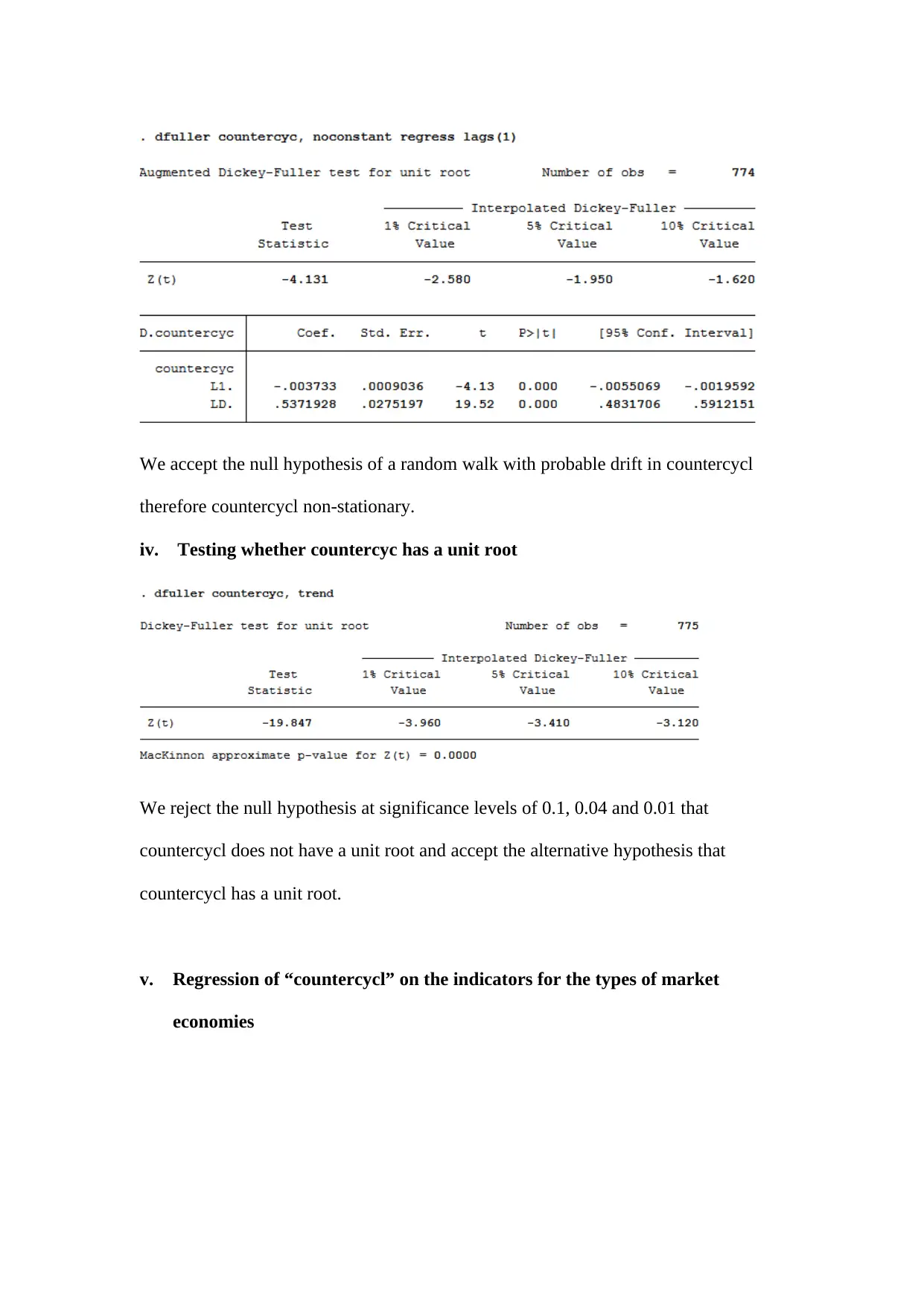
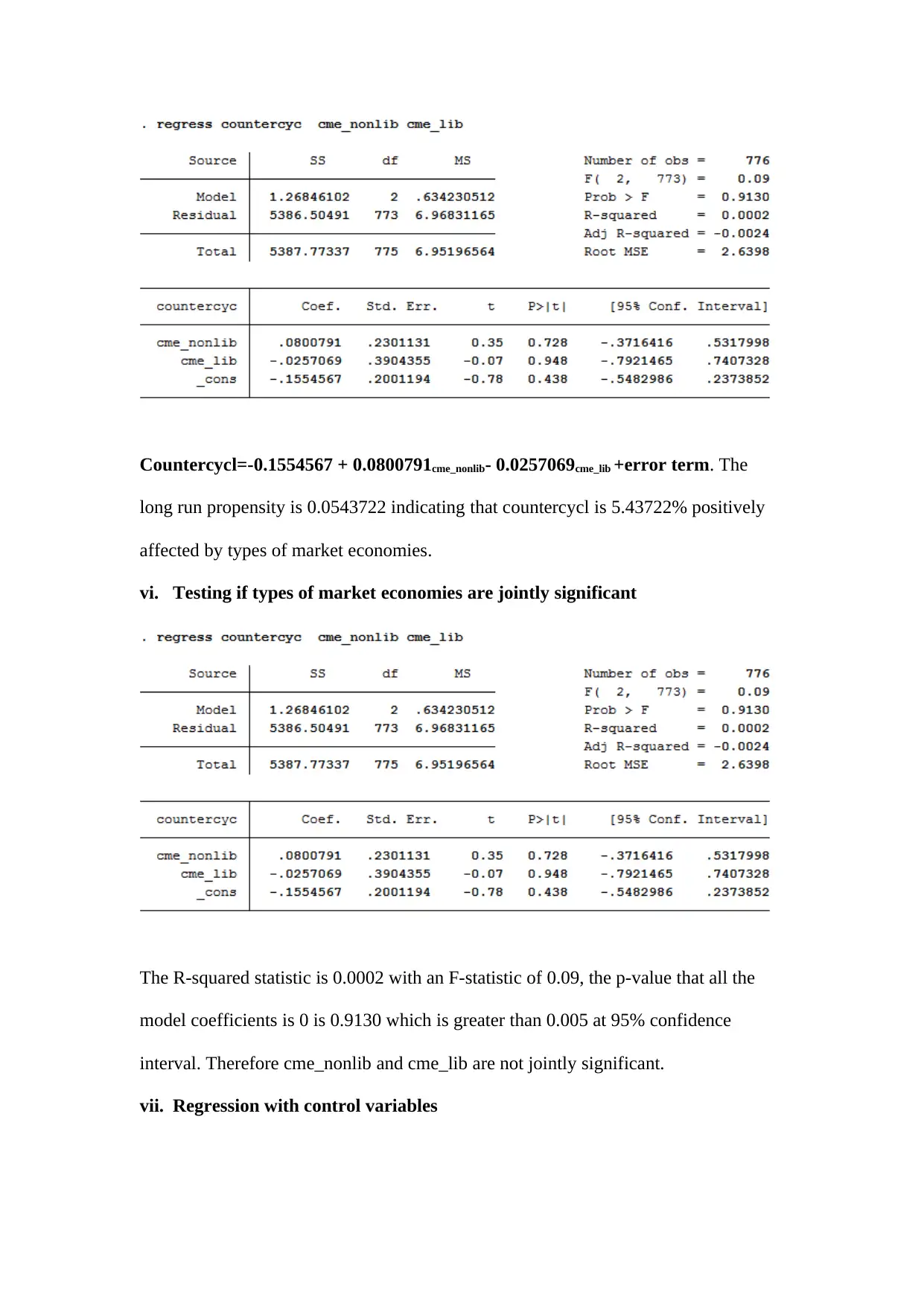
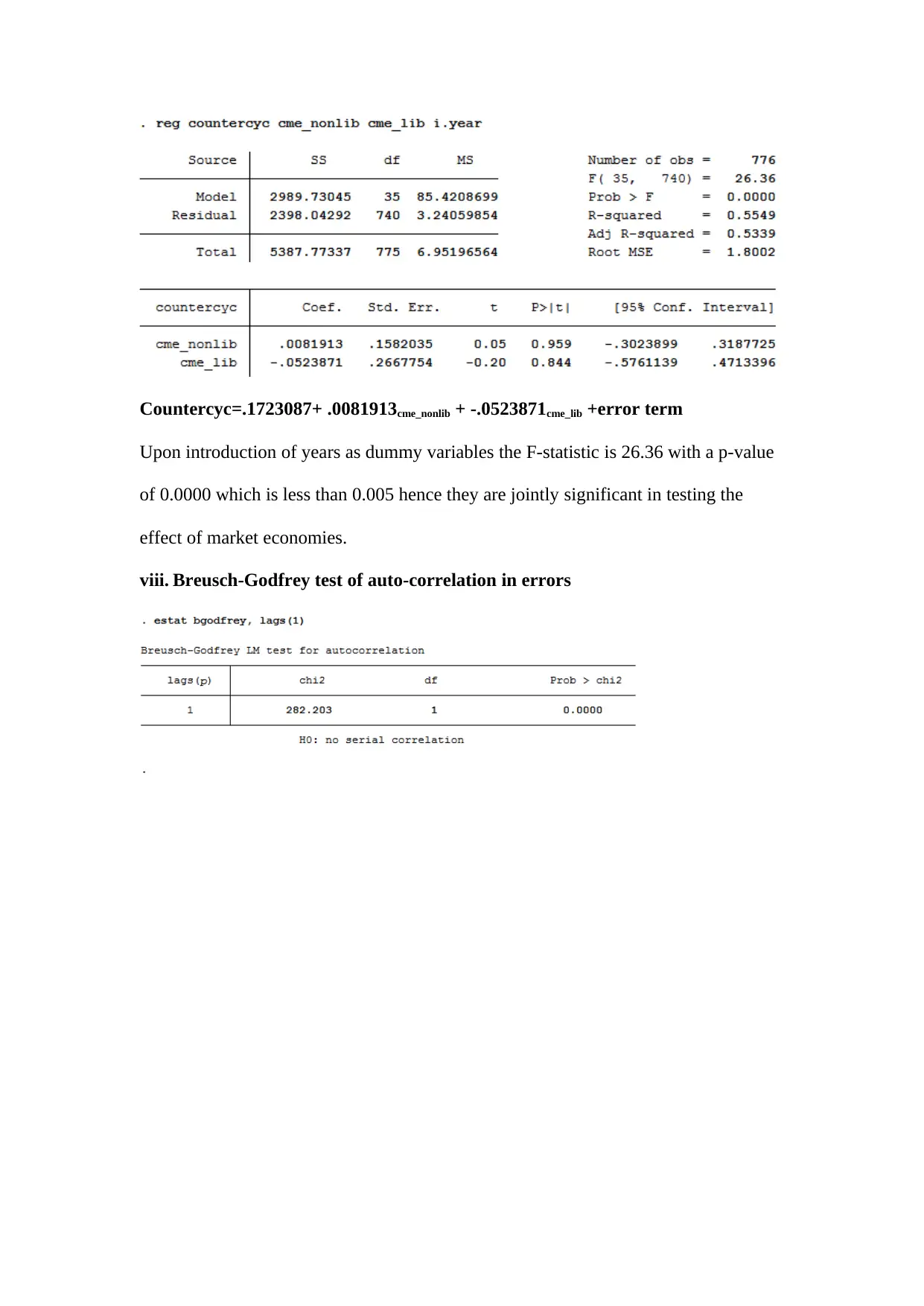
This assignment delves into several key econometric concepts and applies them to analyze economic policies. It begins by explaining the importance of endogenous sample selection, errors in variables, and strict exogeneity in regression models. The assignment then explores the usefulness of introducing deregulation policies at different times for different companies when conducting a difference-in-difference analysis. Furthermore, it examines the long-run effect of personal tax exemptions on fertility rates, including hypothesis testing and interpretation of results. The study also includes a detailed statistical analysis of variables like 'countercyc,' 'cagpb_fd,' and 'output_gap_fd,' including stationarity tests, unit root tests, and regressions on market economy indicators and financial market variables. Finally, the assignment investigates correlation and regression analyses with simulated data, focusing on spurious regressions and the use of time trends to address persistence issues. The document provides comprehensive insights into econometric modeling and policy evaluation. Desklib offers a platform to access this and similar solved assignments, enhancing students' understanding and academic performance.




1 out of 16

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.