Statistical Regression Analysis and Diagnostics Report 2020
VerifiedAdded on 2022/08/08
|28
|5189
|25
Report
AI Summary
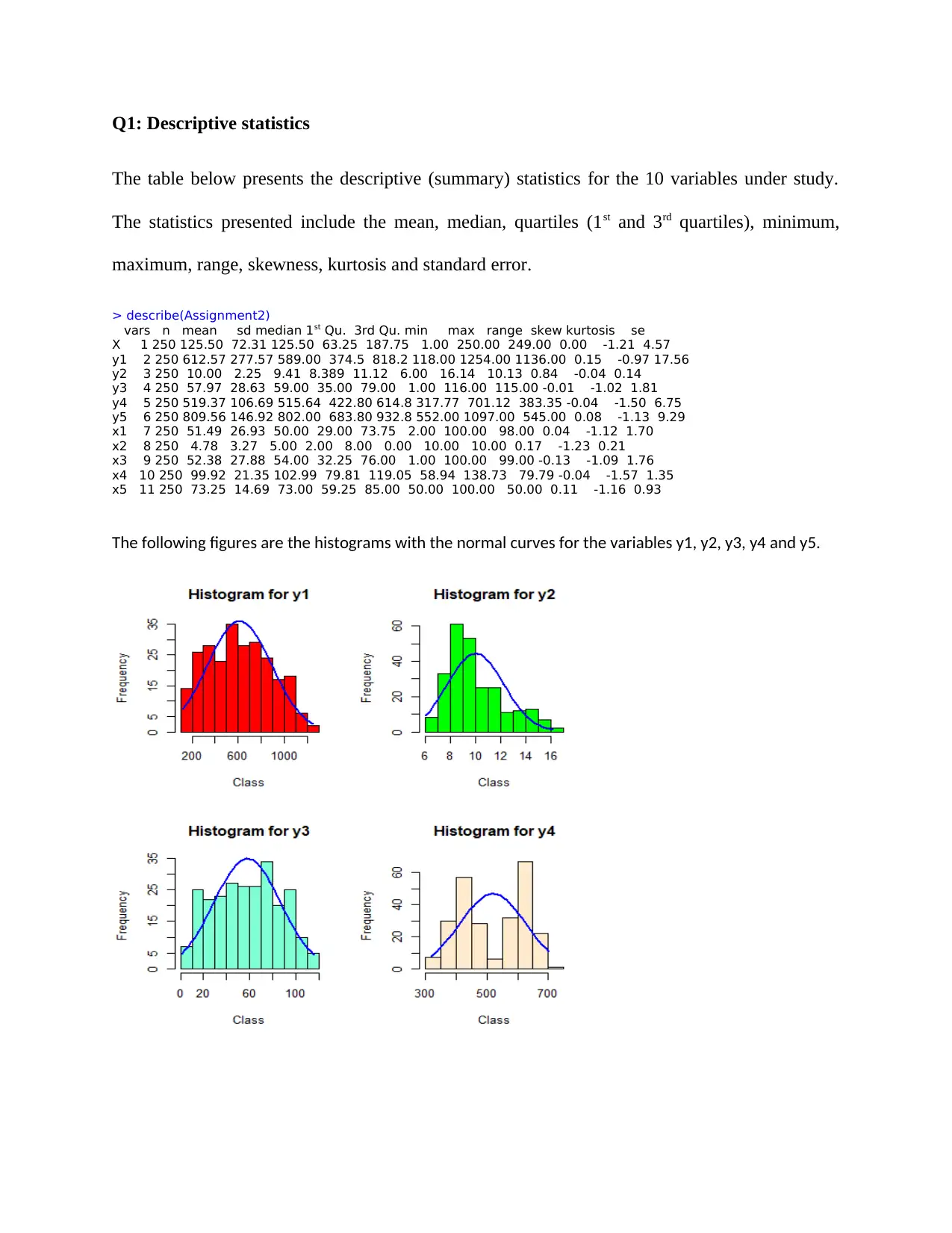
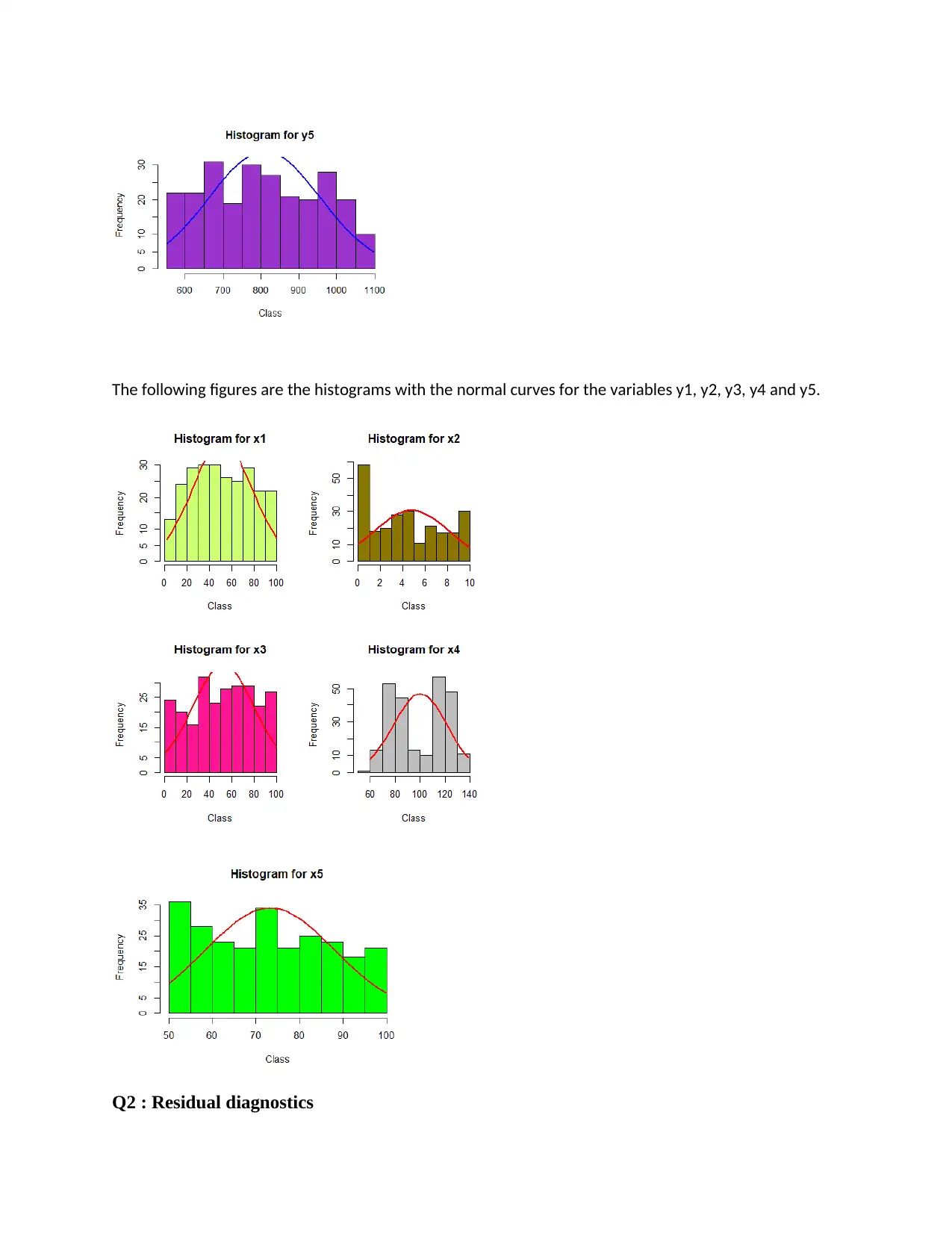
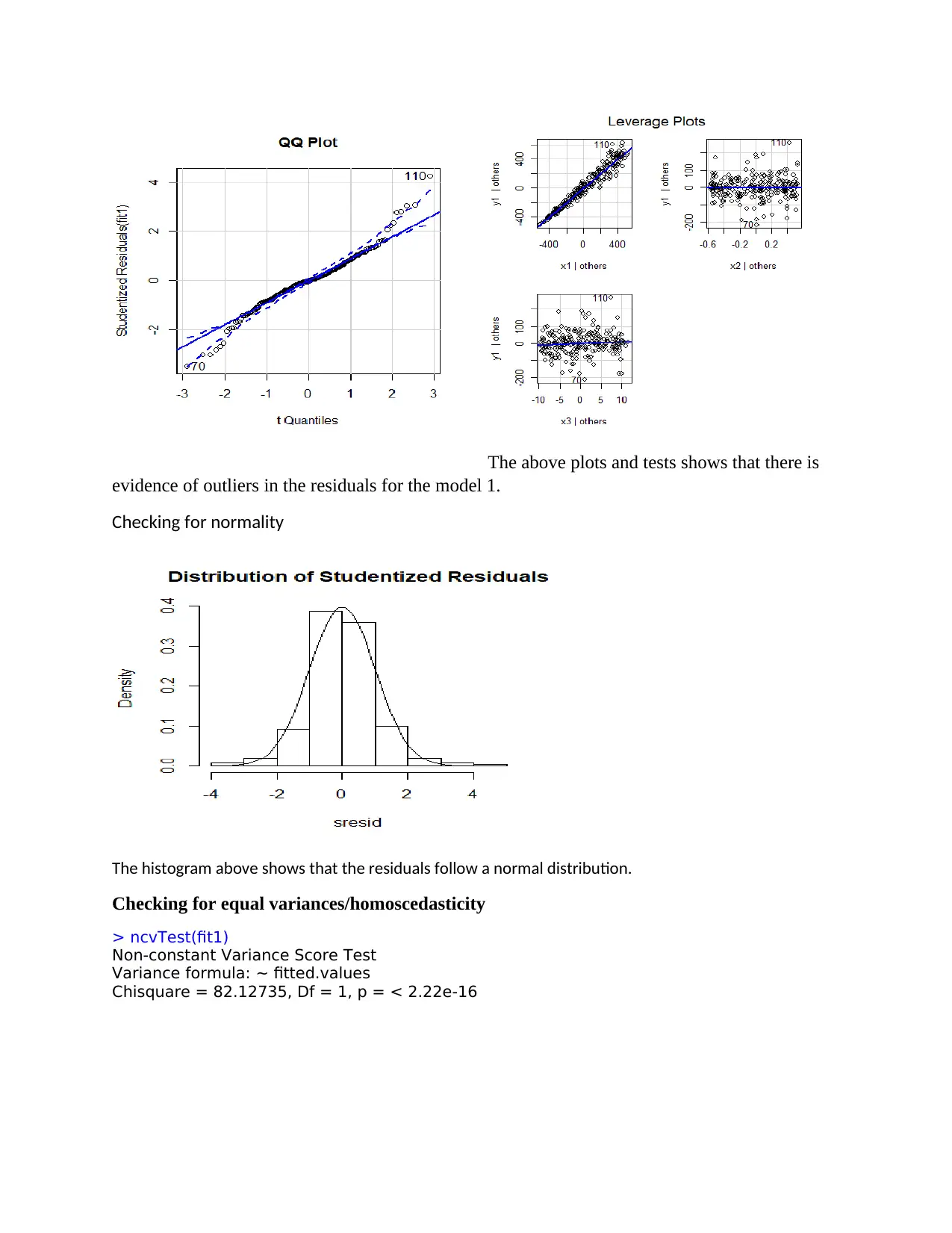
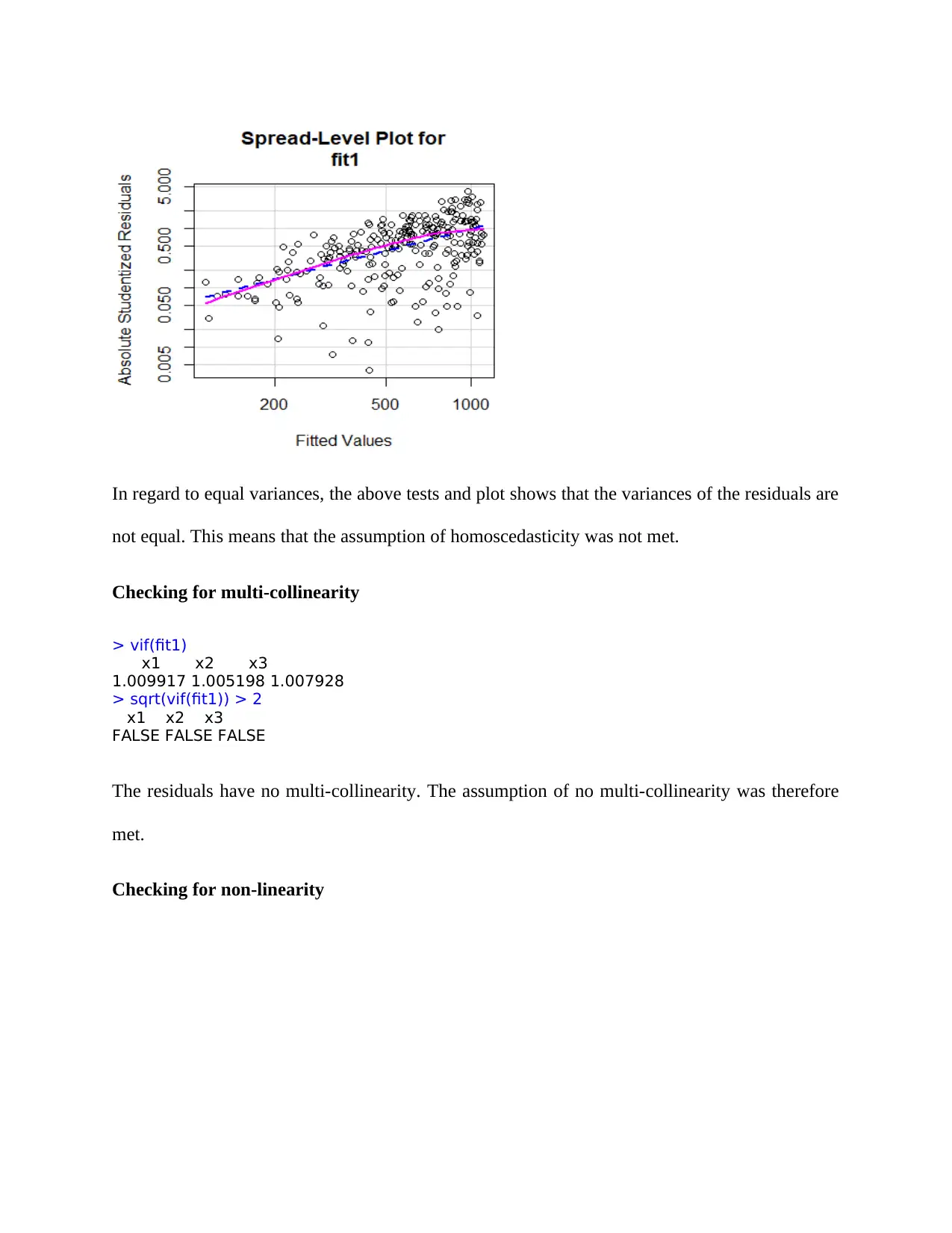
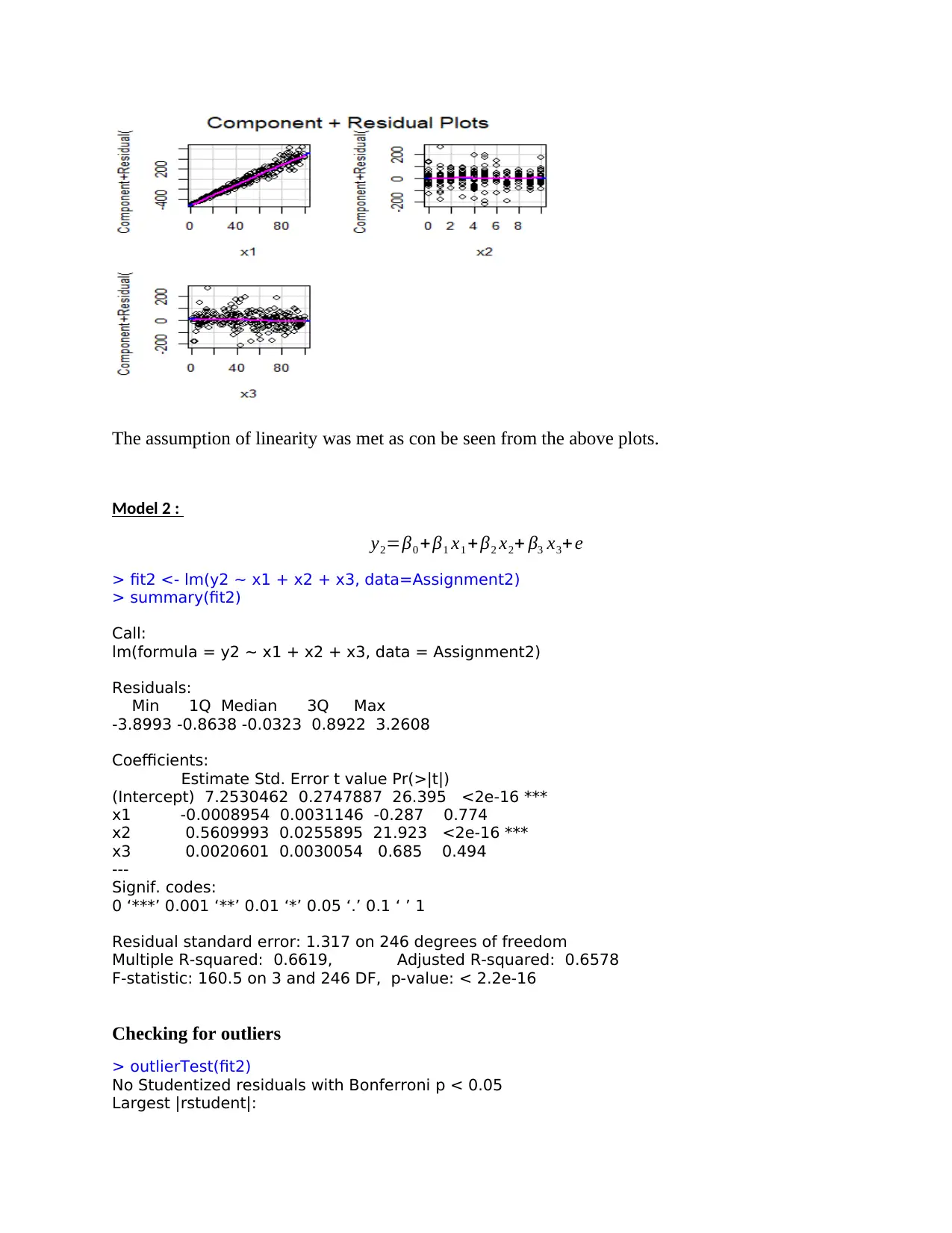
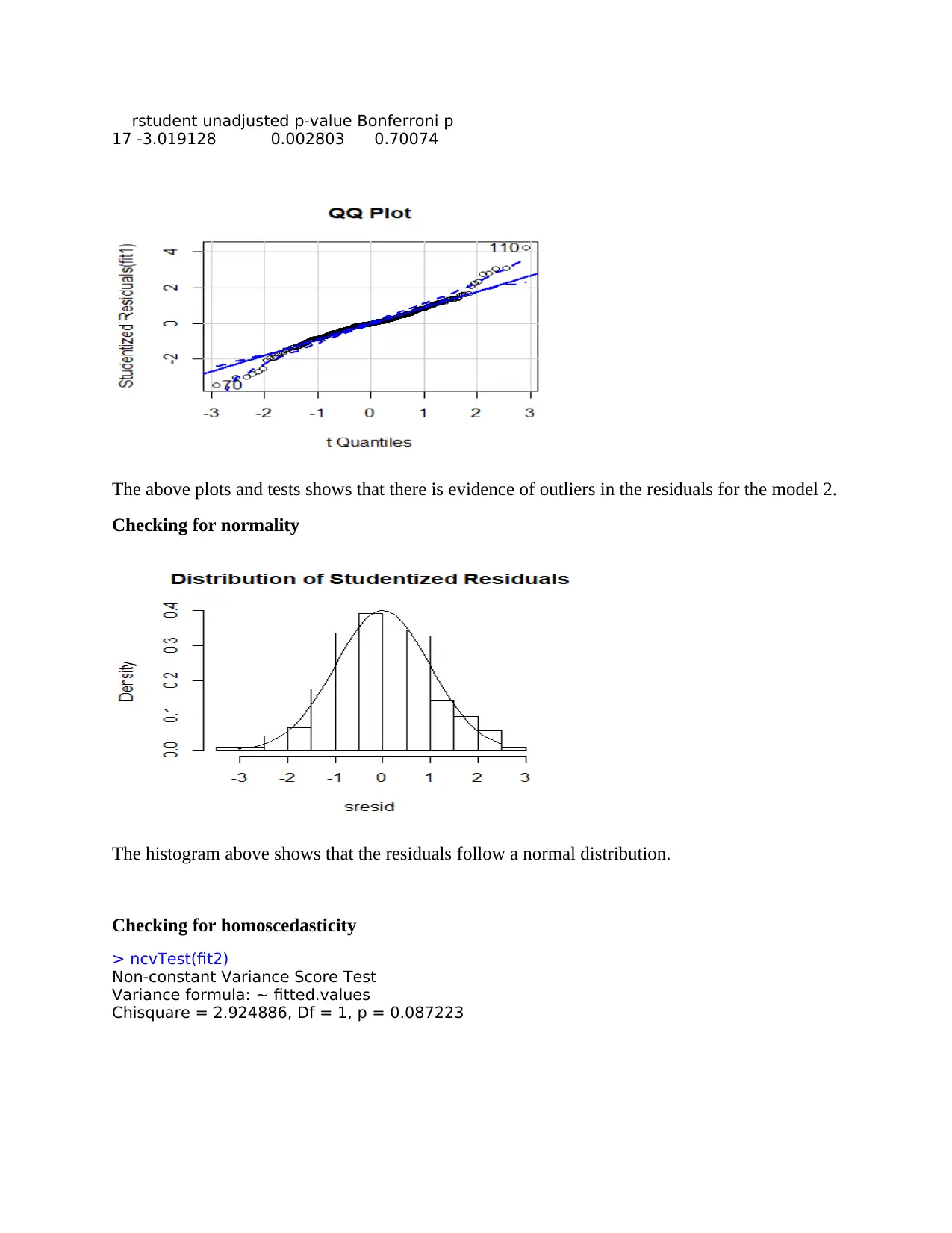
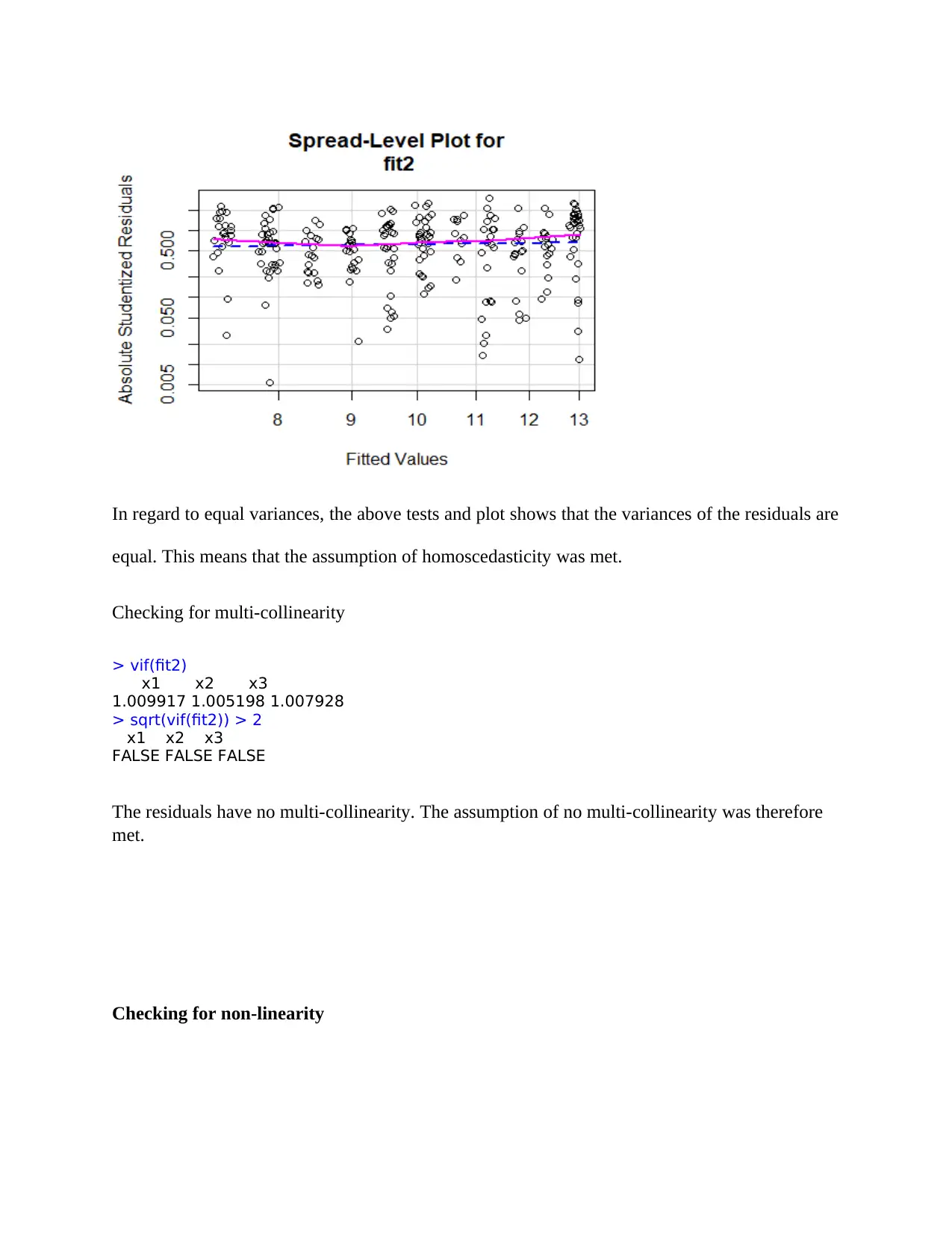
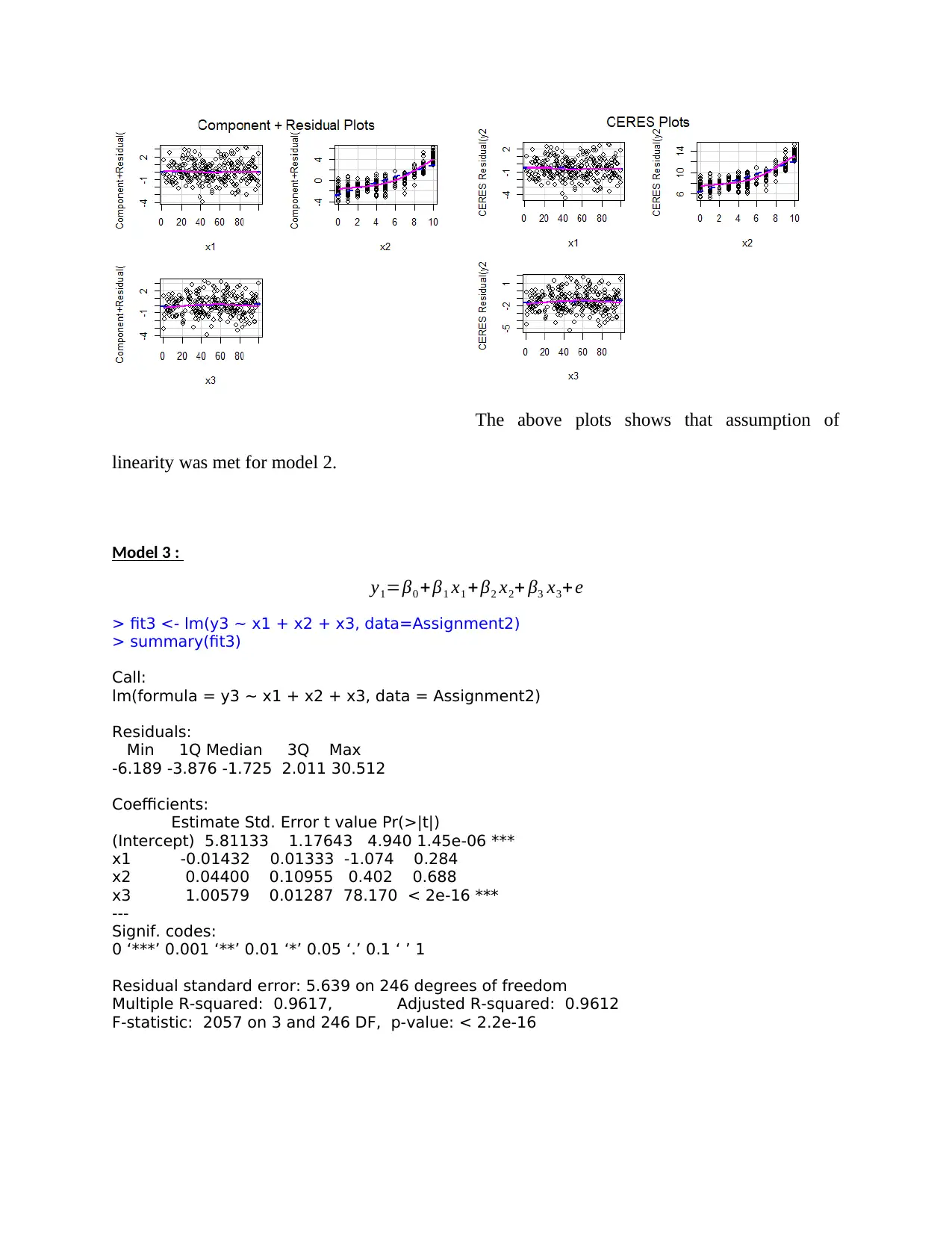
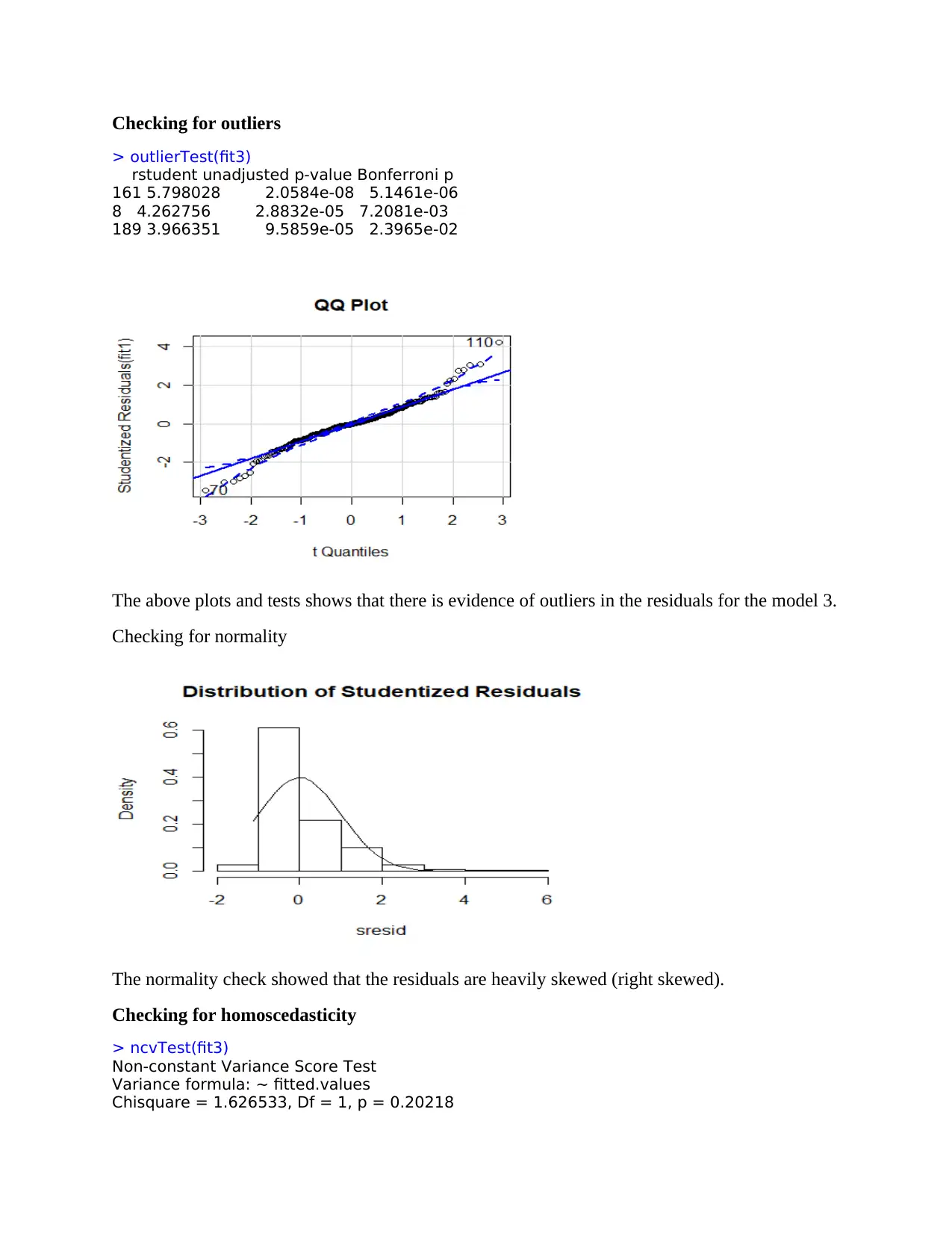
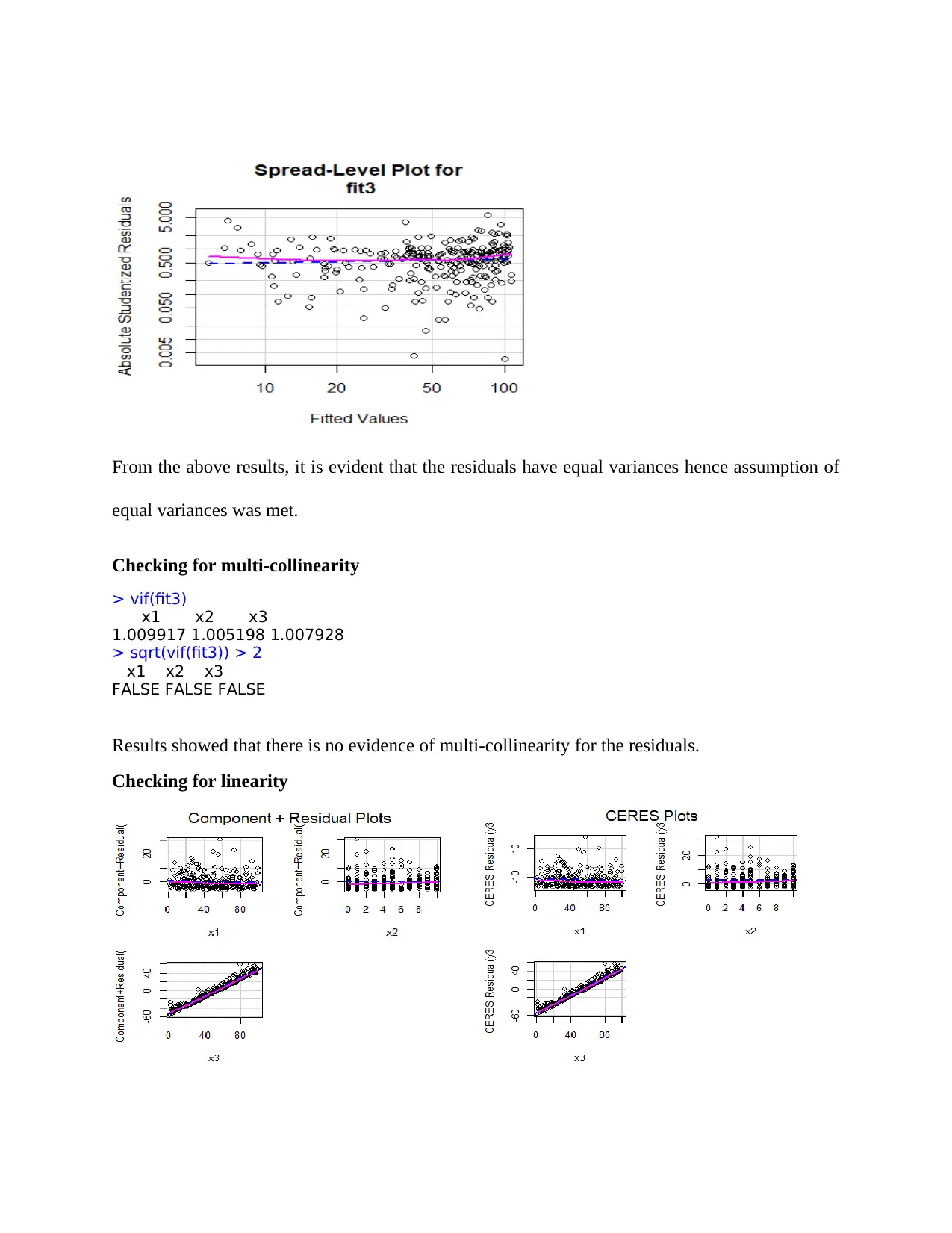
This assignment solution provides a comprehensive analysis of regression models and residual diagnostics. It begins with descriptive statistics for ten variables, including mean, median, quartiles, and skewness. The solution then assesses five regression models (fit1 to fit5), checking for outliers, normality, homoscedasticity, multicollinearity, and linearity. Diagnostic tests such as outlierTest, ncvTest, and vif are used to validate model assumptions. Additionally, the assignment includes an analysis of the 'prestige' dataset, creating scatter plot matrices and descriptive statistics. Finally, distinct simple regression models are built to predict prestige based on education, income and gender, evaluating their significance and R-squared values. The analysis uses statistical tools and tests to ensure the robustness and validity of the regression models.


1 out of 28
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.