LC572: Analyzing Quantitative Research Methods in Social Science
VerifiedAdded on 2023/06/12
|10
|1619
|448
Report
AI Summary
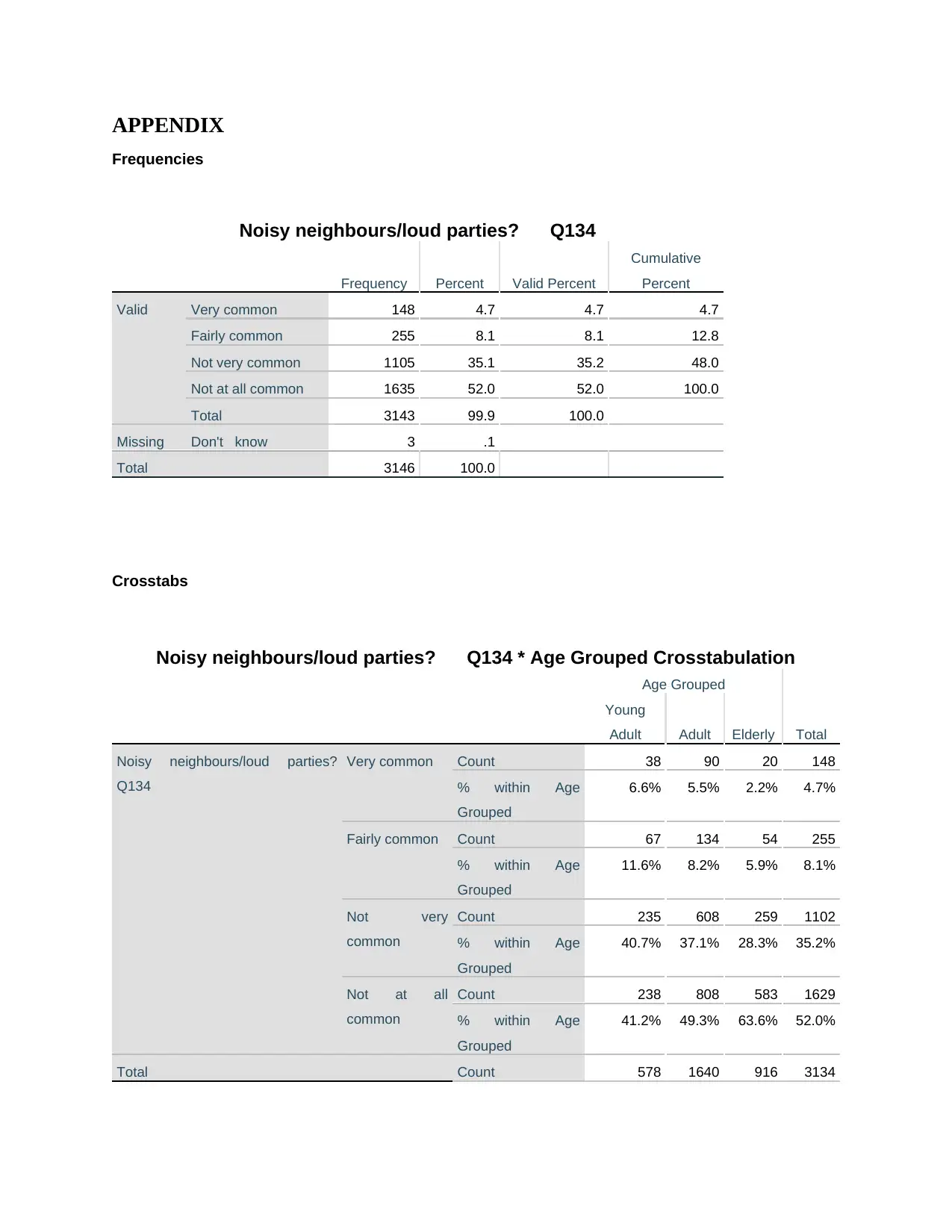
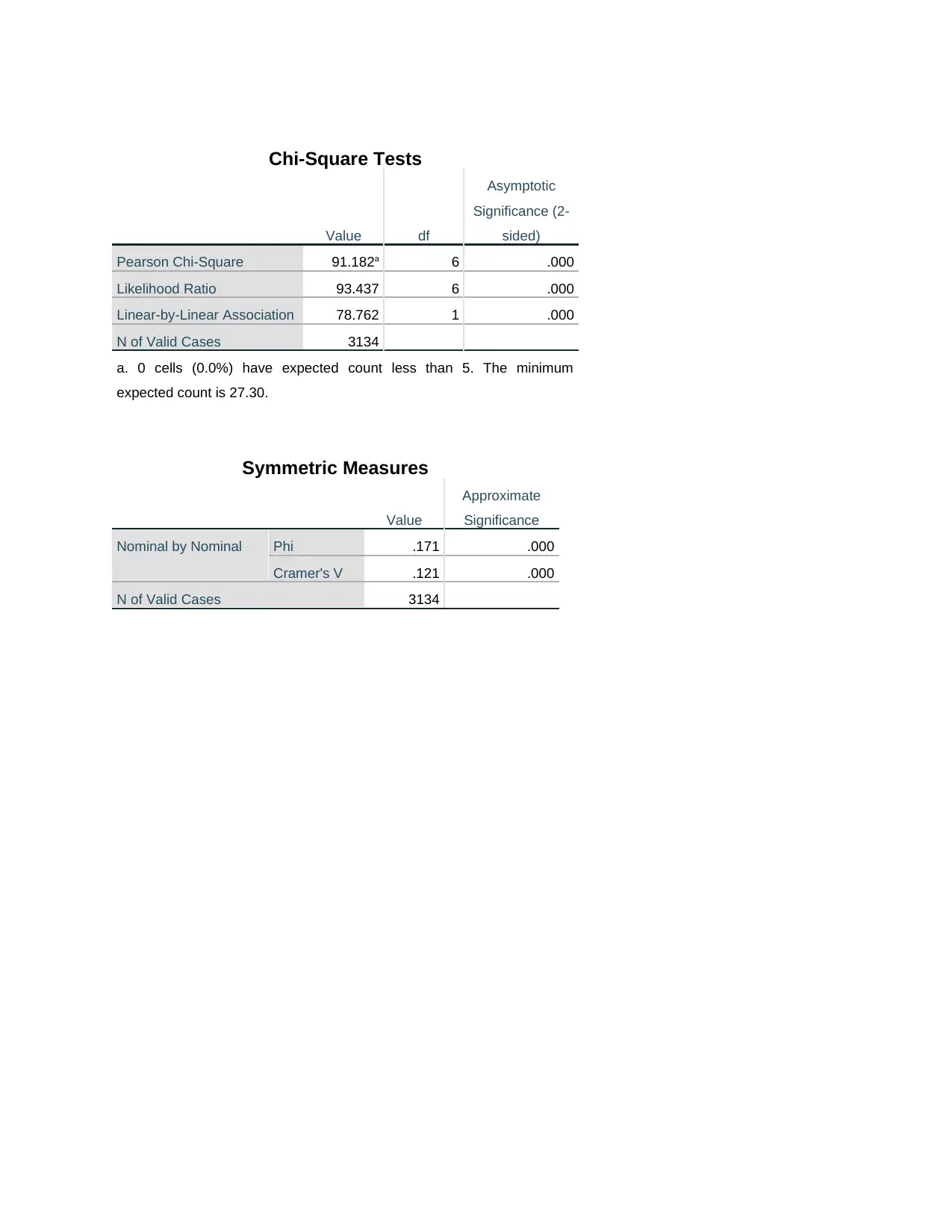
This report provides a comprehensive overview of quantitative research methods for social scientists. It identifies and explains the four levels of measurement (nominal, ordinal, interval, and ratio) with examples. The report also details measures of central tendency (mean, median, mode) and dispersion, differentiating between descriptive and inferential statistics. Key statistical terms such as hypothesis, null hypothesis, independent, dependent, and extraneous variables are explained. Furthermore, the report includes an interpretation of SPSS output, specifically frequency tables and cross-tabulations, to analyze the relationship between noisy neighborhoods and age groups, using chi-square tests and Phi/Cramer's V to assess the strength of association. The analysis concludes that while a statistically significant relationship exists, the association between the variables is negligible. Desklib provides access to this document and many other resources for students.








1 out of 10
Related Documents



Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.