HI6007: Statistics and Research Methods Group Assignment T1 2019
VerifiedAdded on 2022/11/24
|10
|968
|472
Homework Assignment
AI Summary
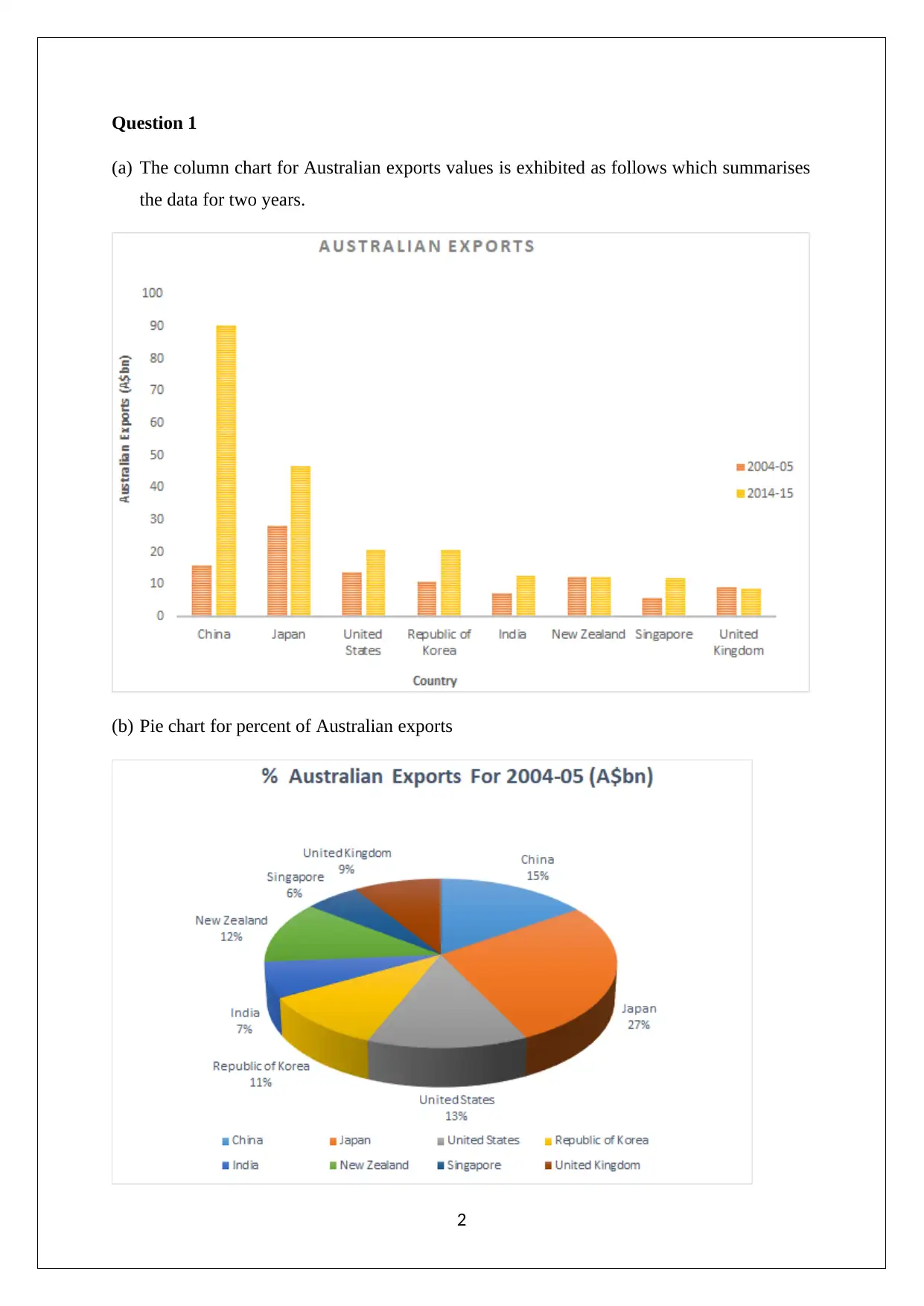
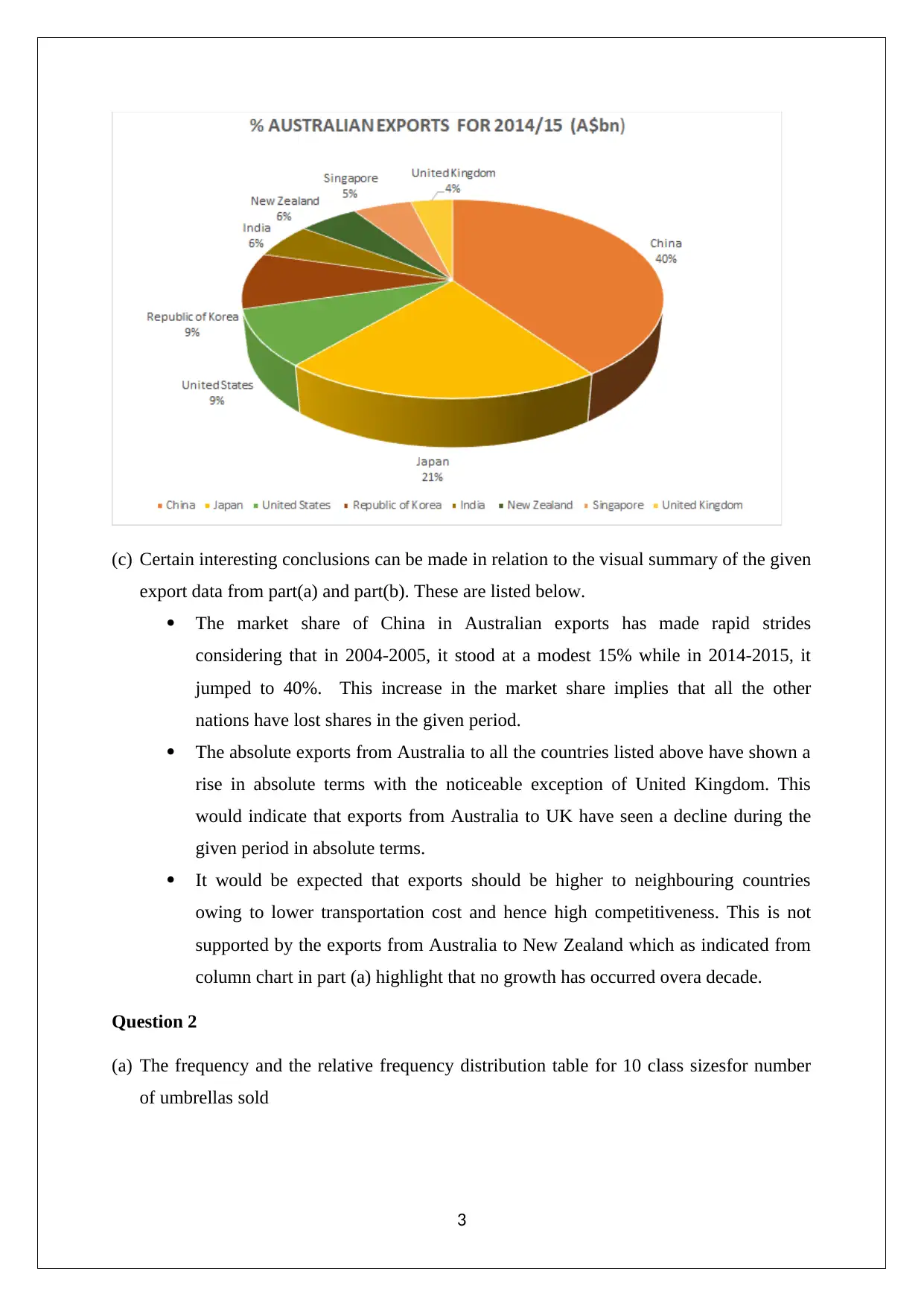
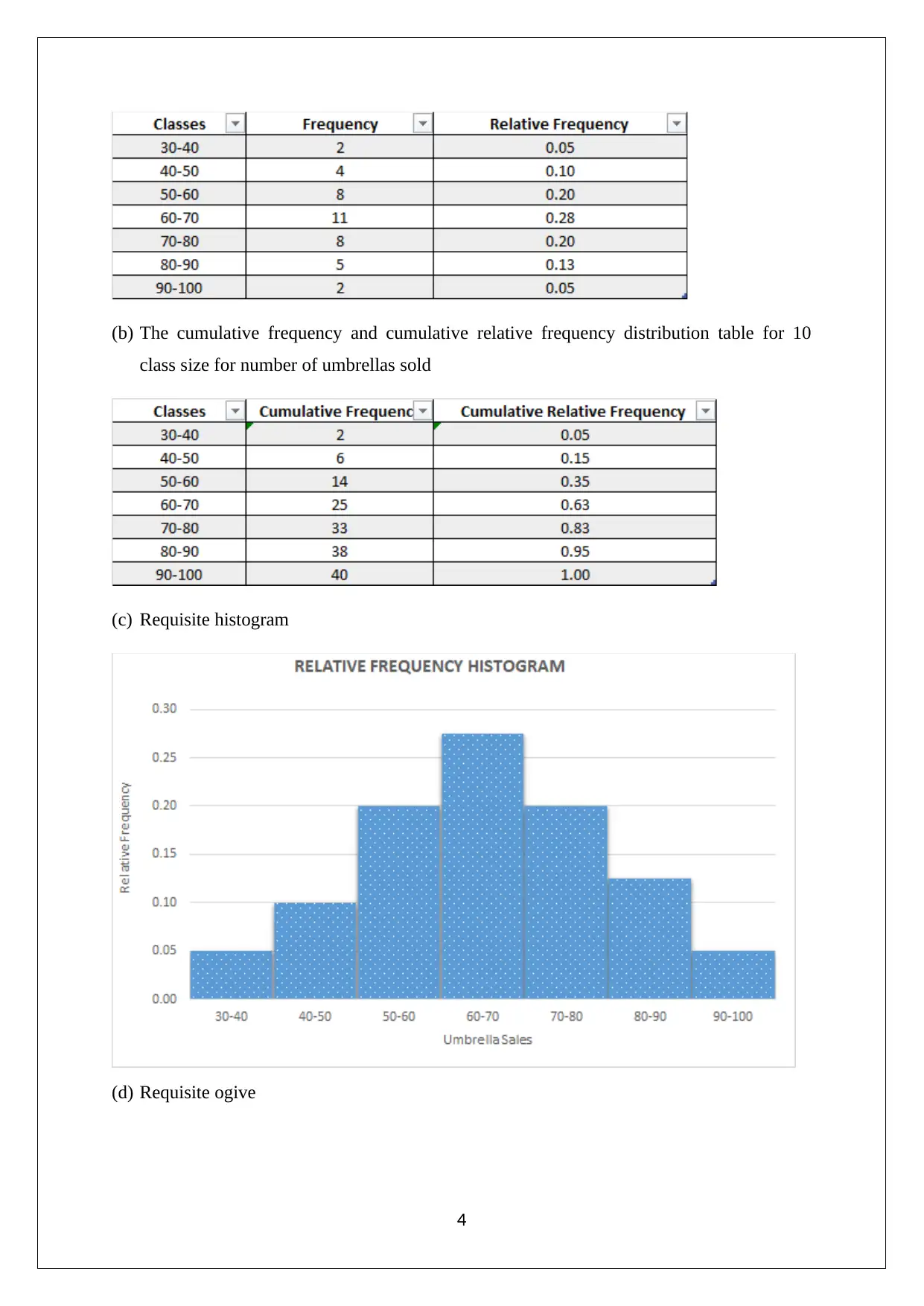
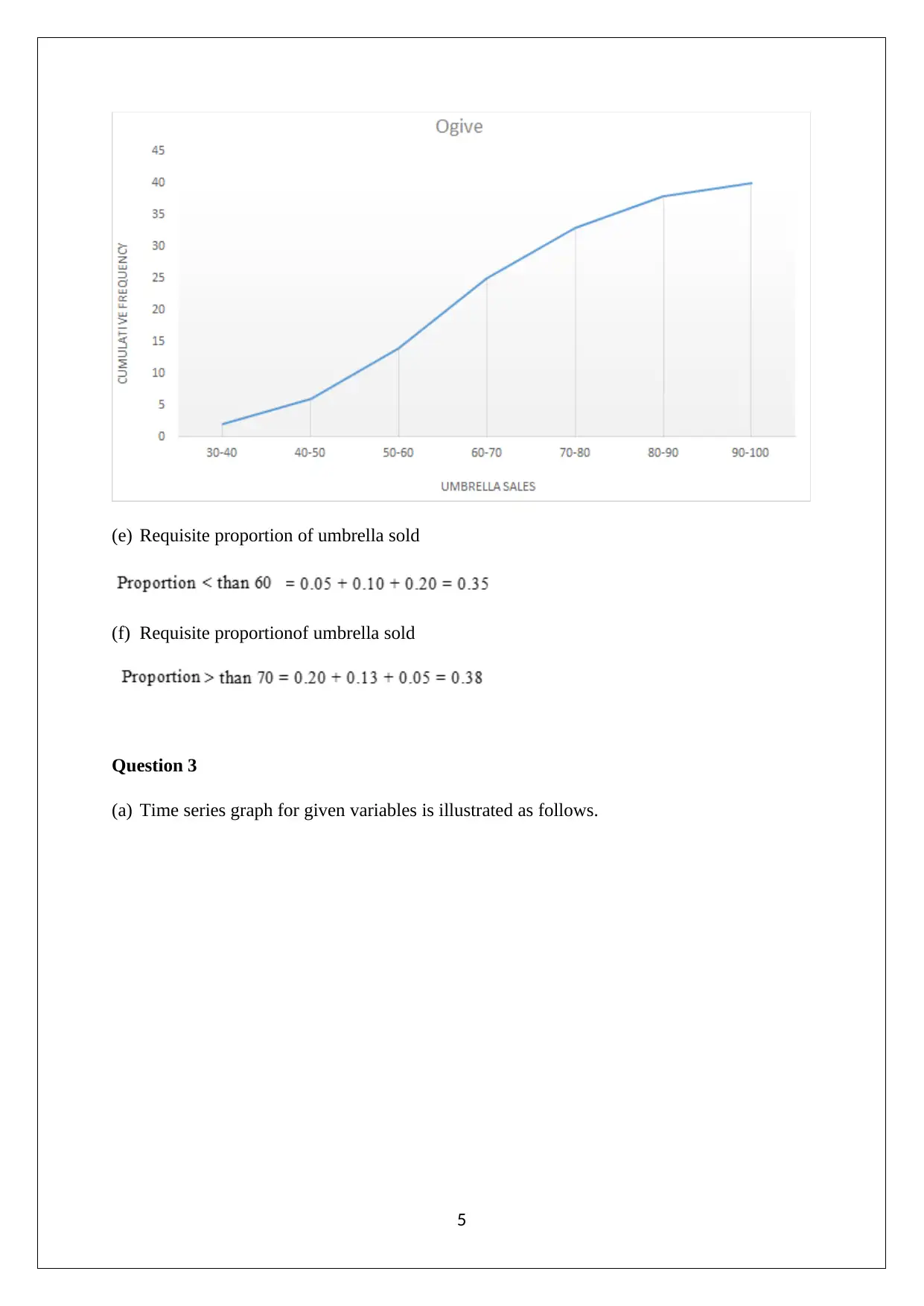
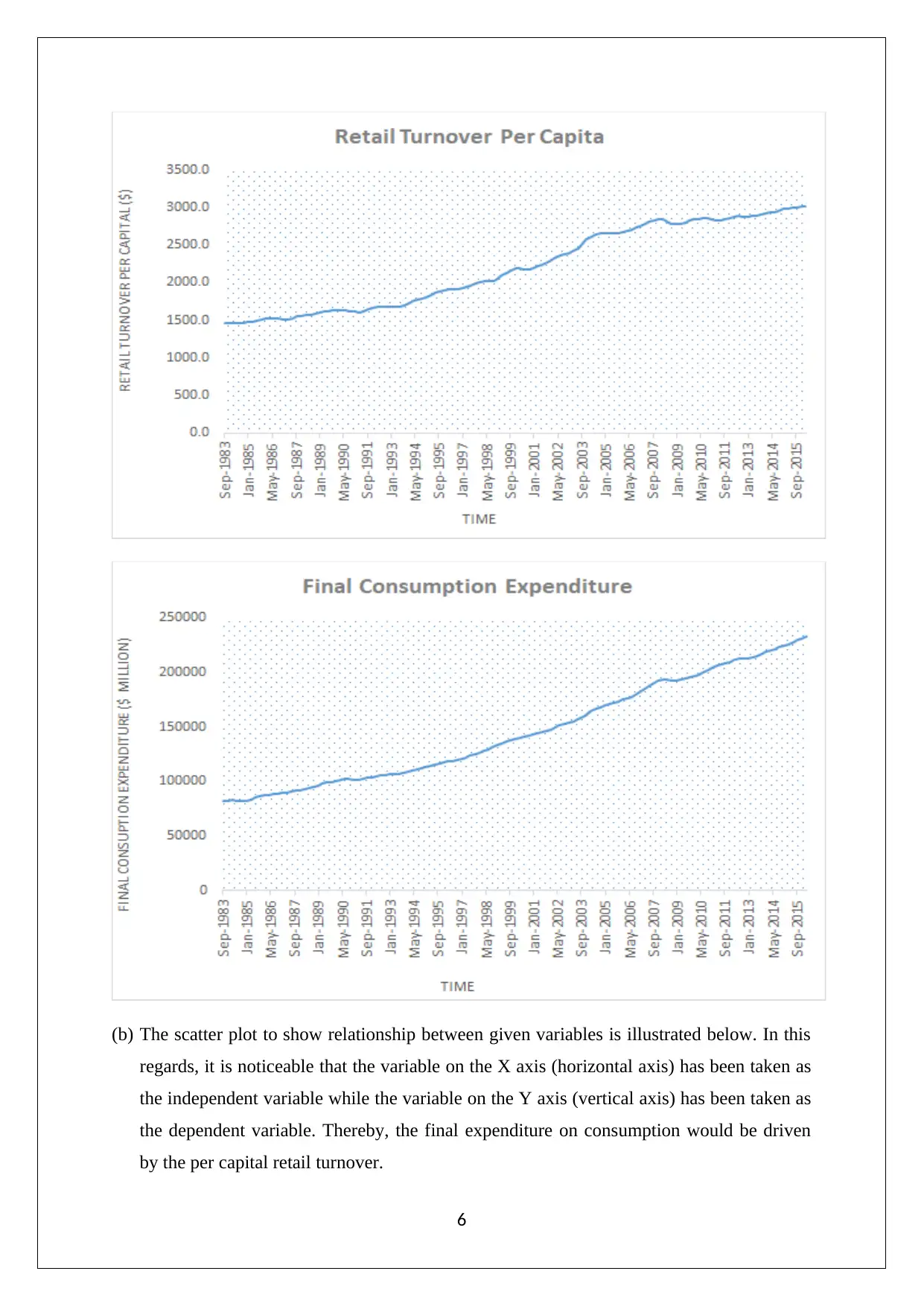
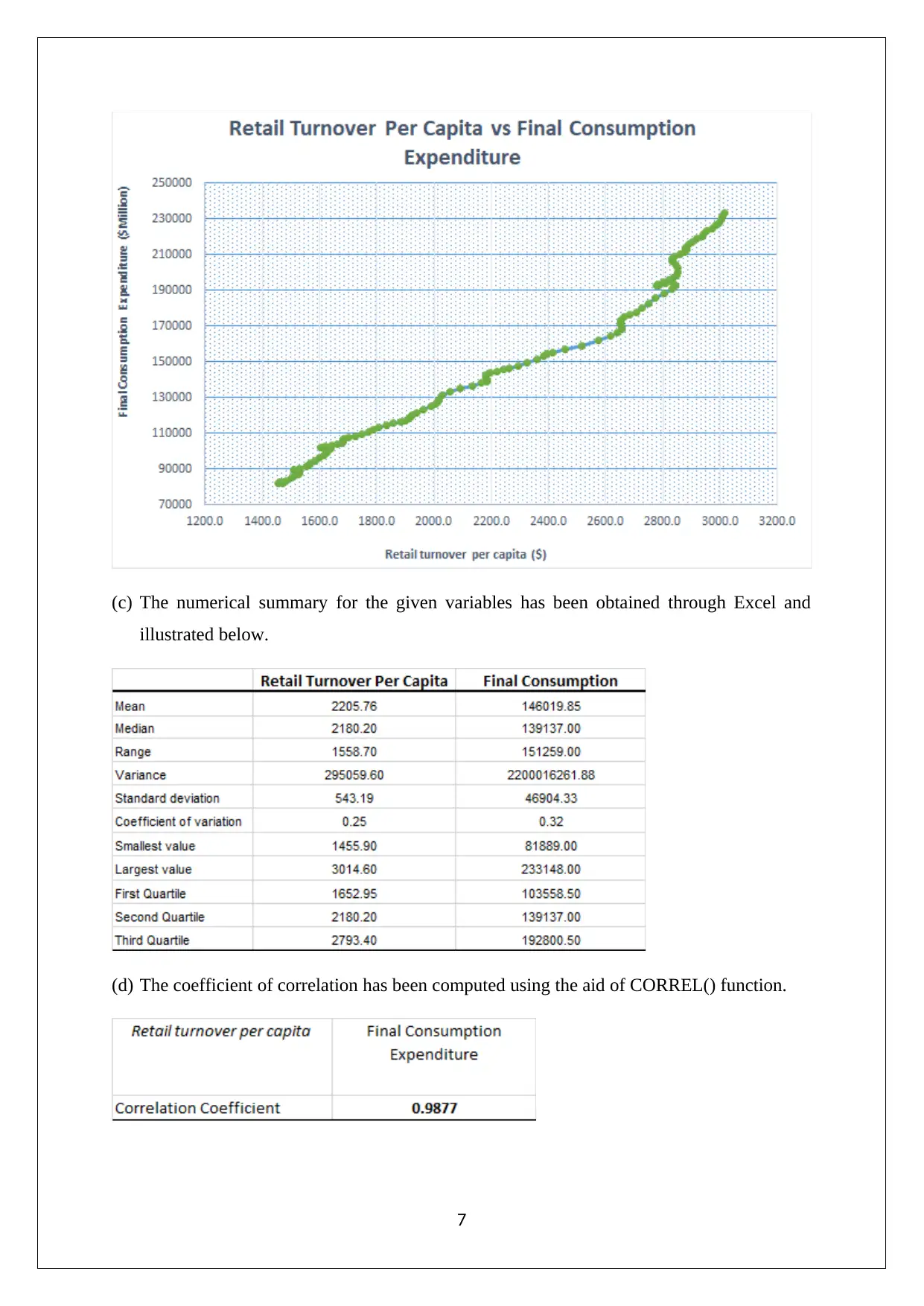
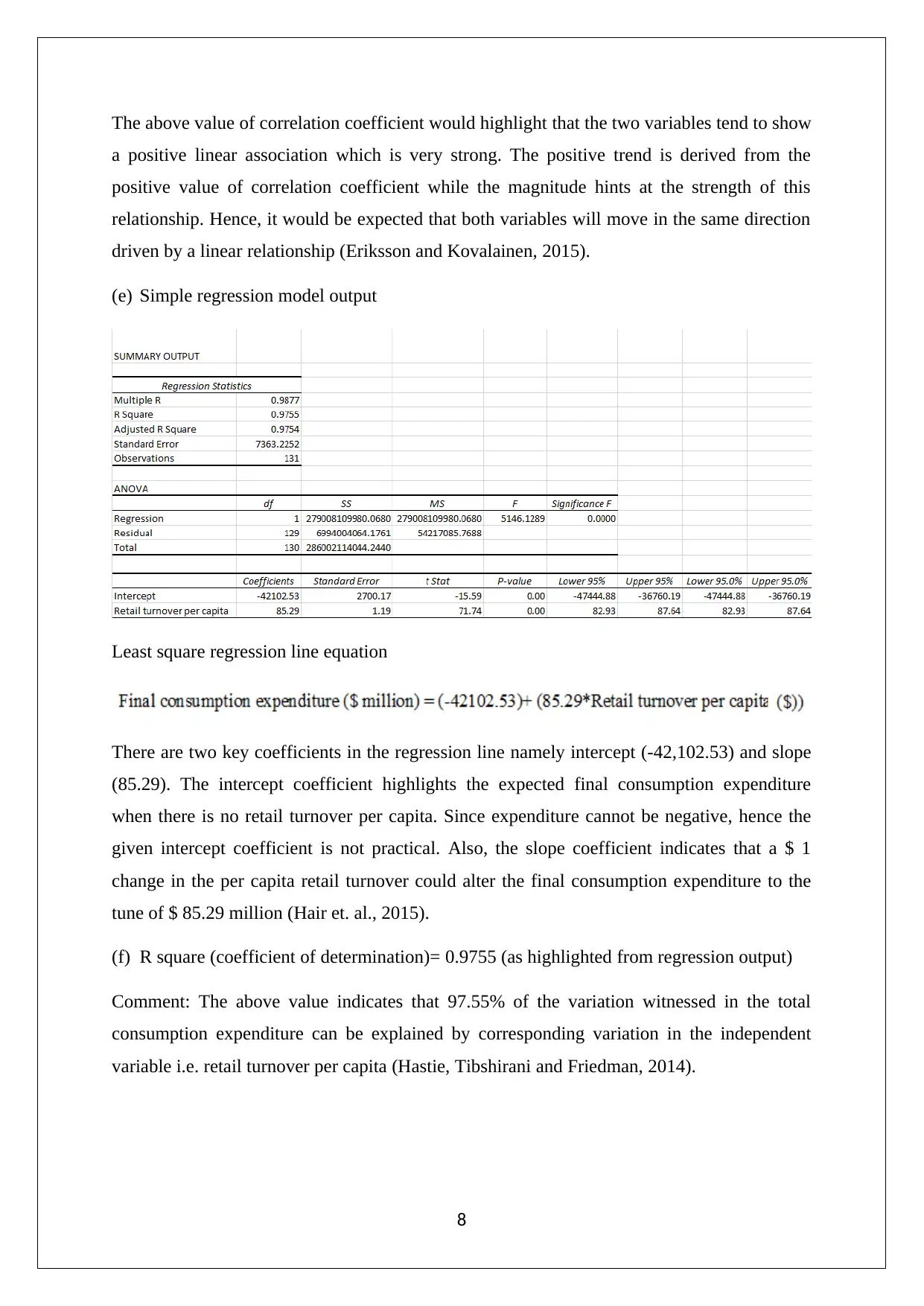
This assignment solution for the Statistics and Research Methods for Business Decision Making course (HI6007) covers various statistical concepts and their application in business contexts. The solution includes analysis of Australian export data using column and pie charts, drawing conclusions about market share changes and export trends. It also presents frequency distributions, histograms, and ogives related to umbrella sales data. Furthermore, the assignment delves into time series analysis and regression modeling, exploring the relationship between retail turnover per capita and final consumption expenditure. It provides a numerical summary, correlation analysis, regression model output, and hypothesis testing to determine the significance of the relationship. The document also includes references to support the analysis and findings.



1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.