Econometrics Homework: Regression Analysis of Call Centre Data RMIT
VerifiedAdded on 2023/06/04
|9
|2101
|132
Homework Assignment
AI Summary
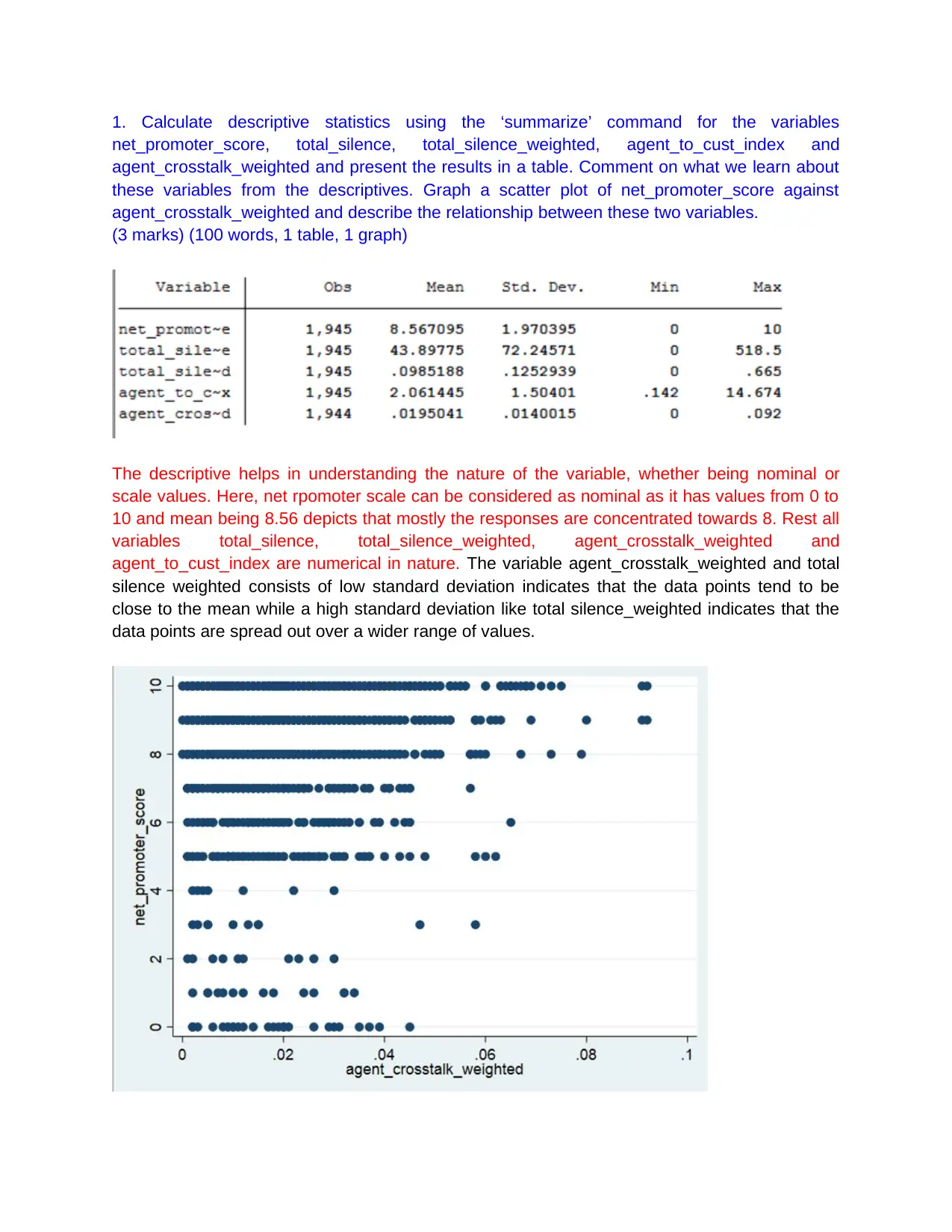
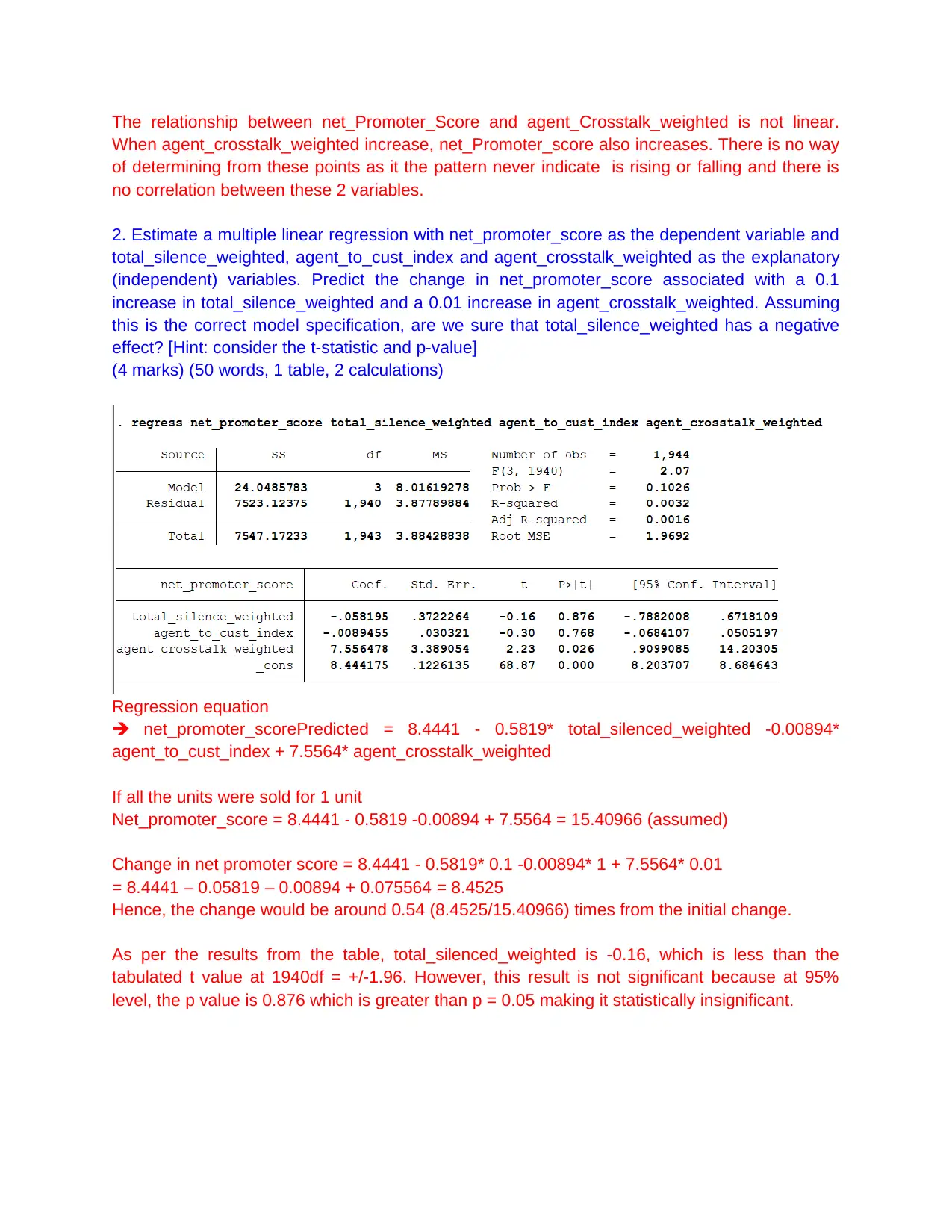
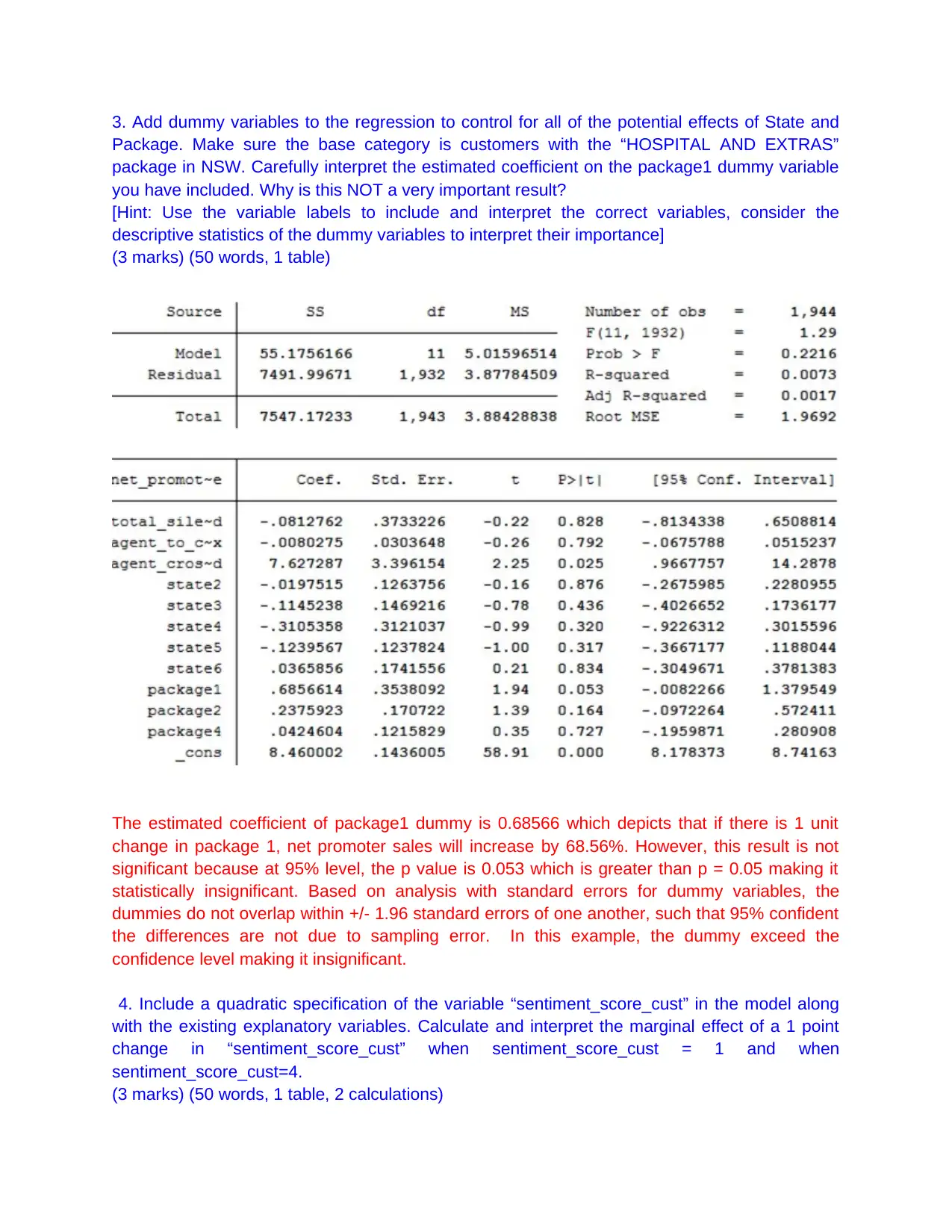
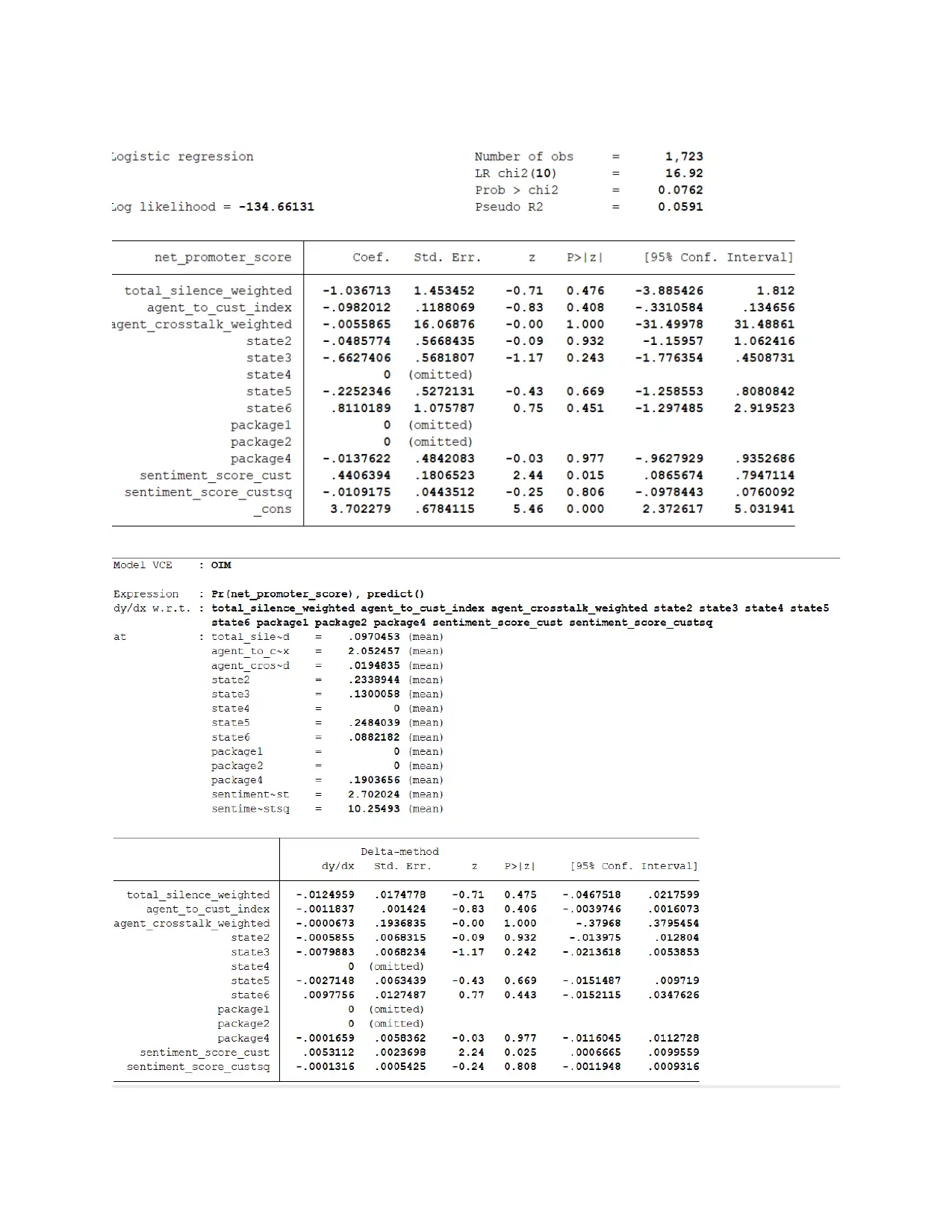
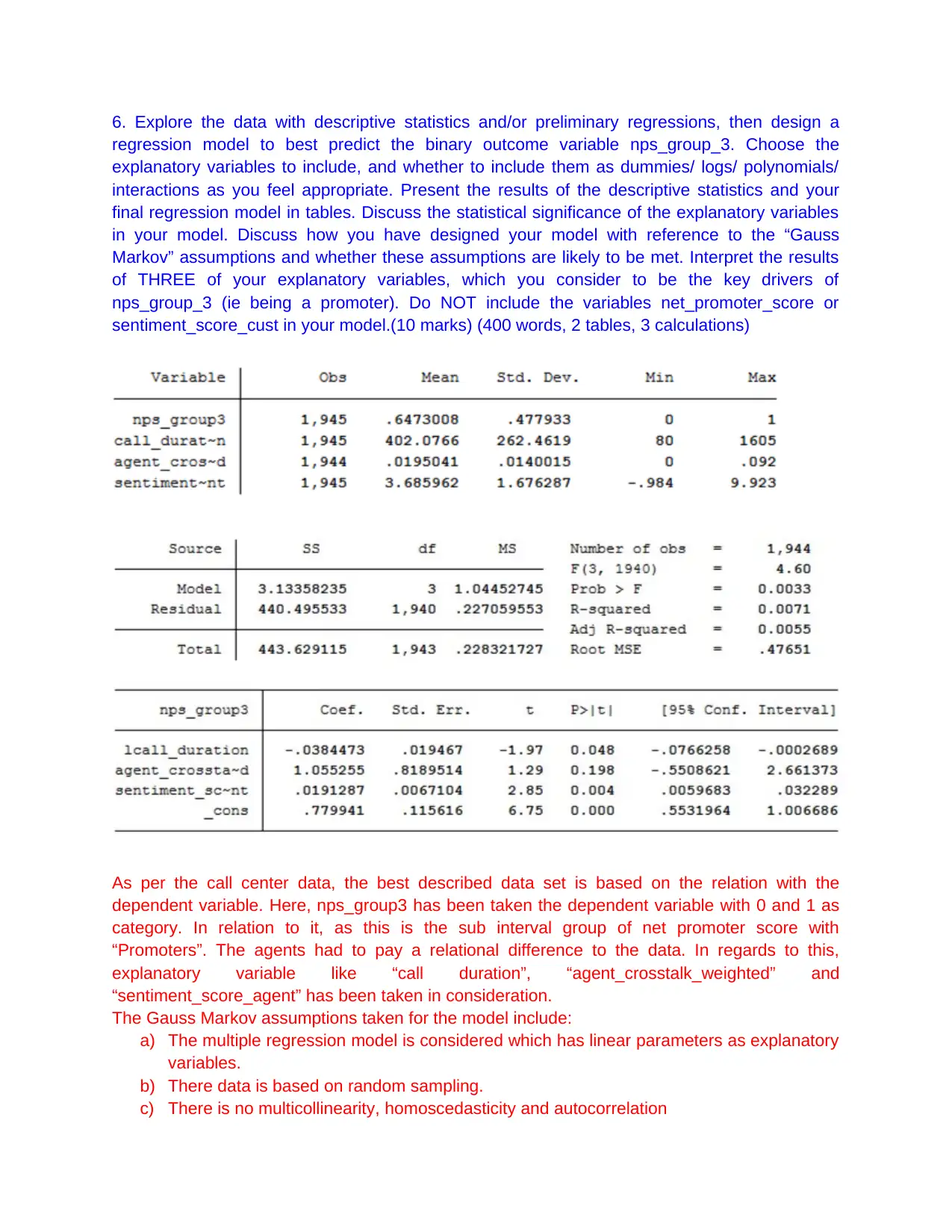
This assignment focuses on analyzing call centre data using regression analysis in Stata to determine the key drivers of the Net Promoter Score (NPS). It involves calculating descriptive statistics, estimating multiple linear regressions, incorporating dummy variables for state and package effects, and including a quadratic specification for sentiment score. The analysis assesses the conditional mean independence assumption and designs a regression model to predict a binary outcome variable related to NPS group. The findings are summarized in an executive summary, highlighting the importance of variables like agent crosstalk, call duration, and agent sentiment in influencing the net promoter score, while also discussing limitations and potential improvements to the model. This assignment also checks Gauss Markov assumptions to see the validity of regression model. Desklib provides students access to a wide range of solved assignments and study tools.




1 out of 9
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.