Statistical Analysis Assignment Solution: SOC 302, Fall 2024
VerifiedAdded on 2023/01/19
|30
|3963
|74
Homework Assignment
AI Summary
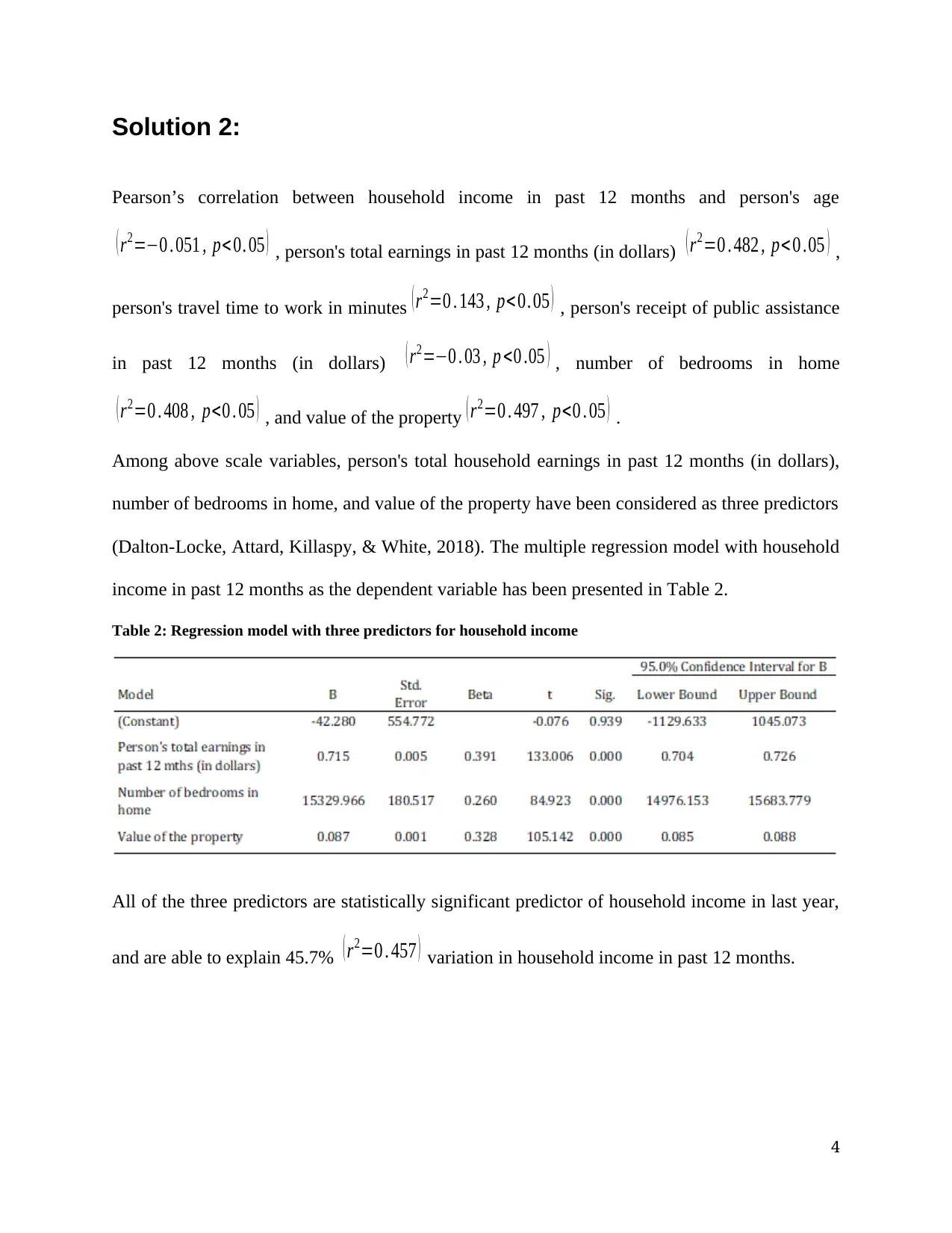
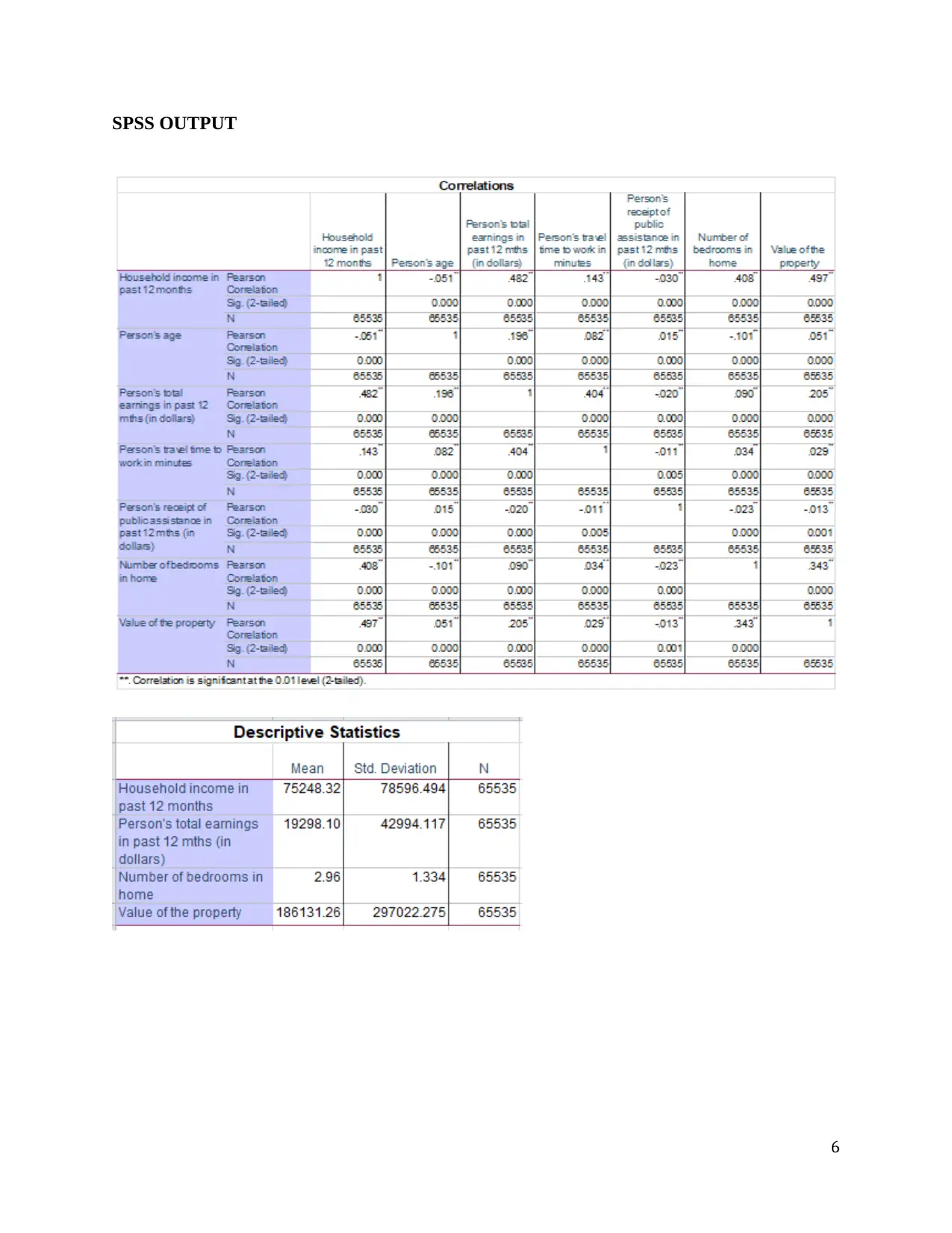
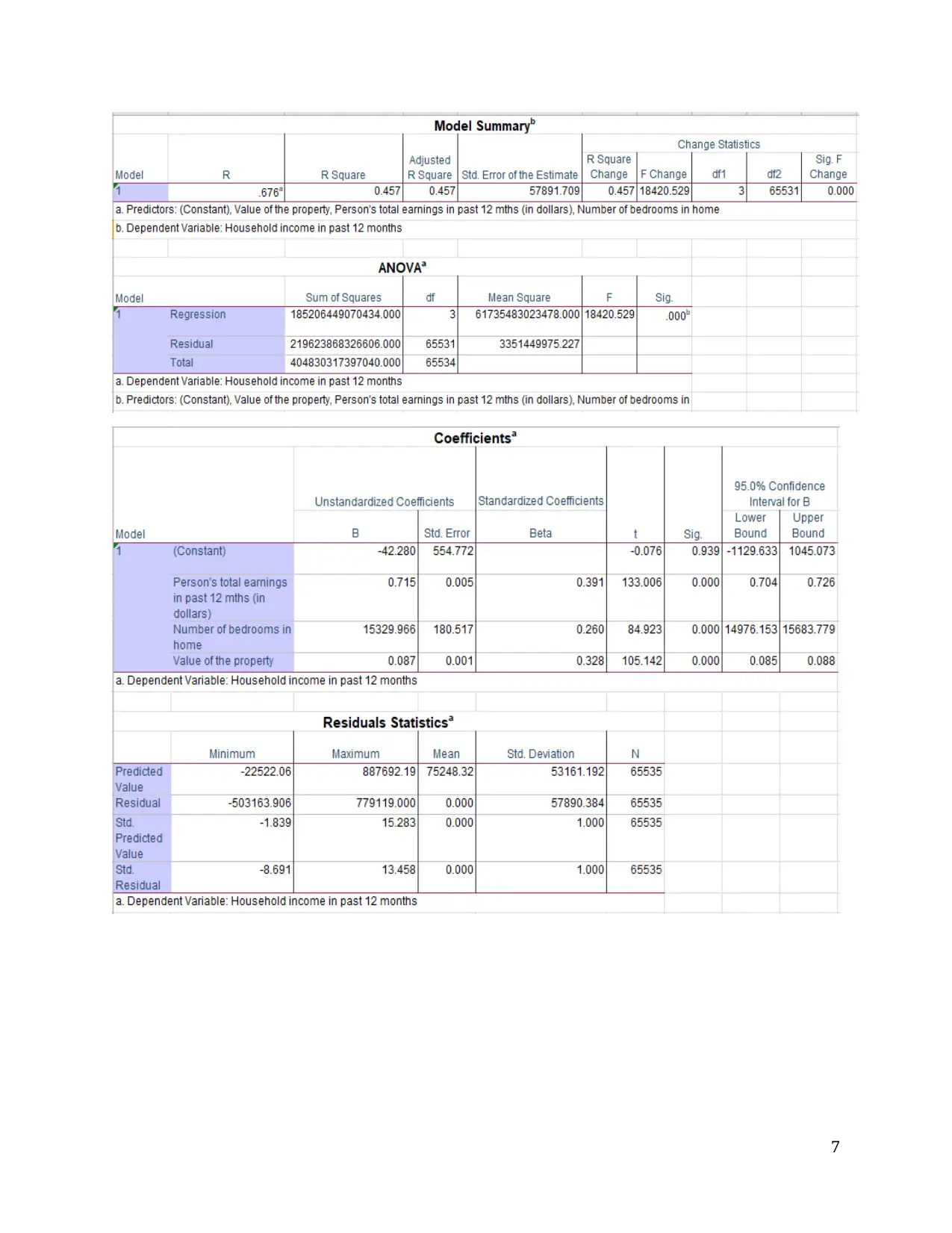
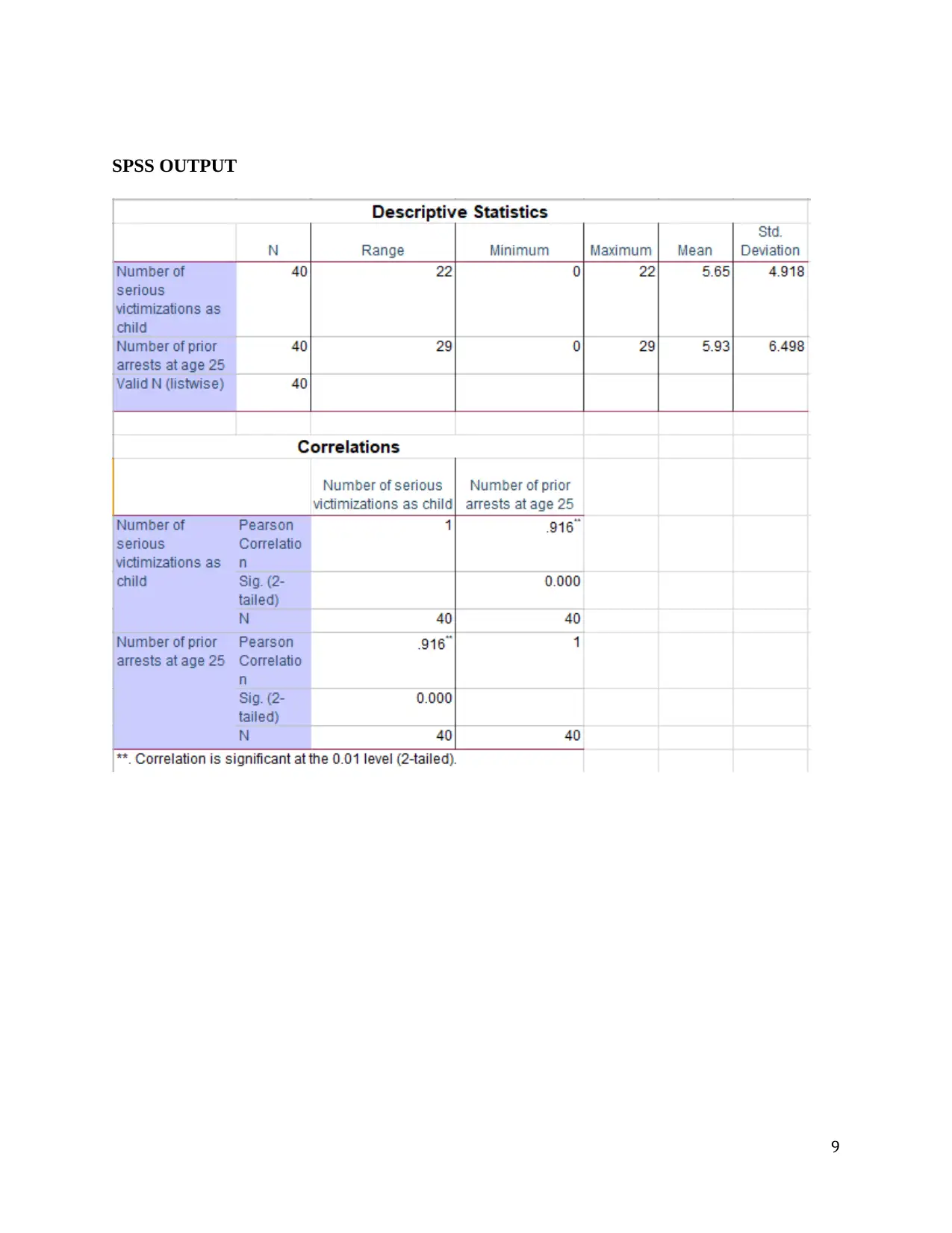
This document presents a comprehensive solution to a statistical analysis assignment (SOC 302), addressing multiple problems using various statistical methods. The solutions include paired t-tests to compare housing prices before and after a recession, Pearson's correlation to analyze relationships between variables like income and age, multiple regression to predict household income, independent t-tests to compare disciplinary problems in schools, two-way ANOVA to analyze the impact of prior arrests and community on sentence length, one-way ANOVA to compare hotel rates, and chi-square tests to examine the association between political affiliation and geographic regions. Each solution includes null and alternative hypotheses, the rationale for choosing the appropriate statistical test, descriptive statistics, SPSS output, and a final conclusion with statistical notation. The assignment covers a range of statistical concepts and their practical applications, providing a detailed analysis of each problem and its solution.








1 out of 30
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.