Data Classification Project: University Name, Subject Code Analysis
VerifiedAdded on 2022/09/02
|10
|1469
|24
Project
AI Summary
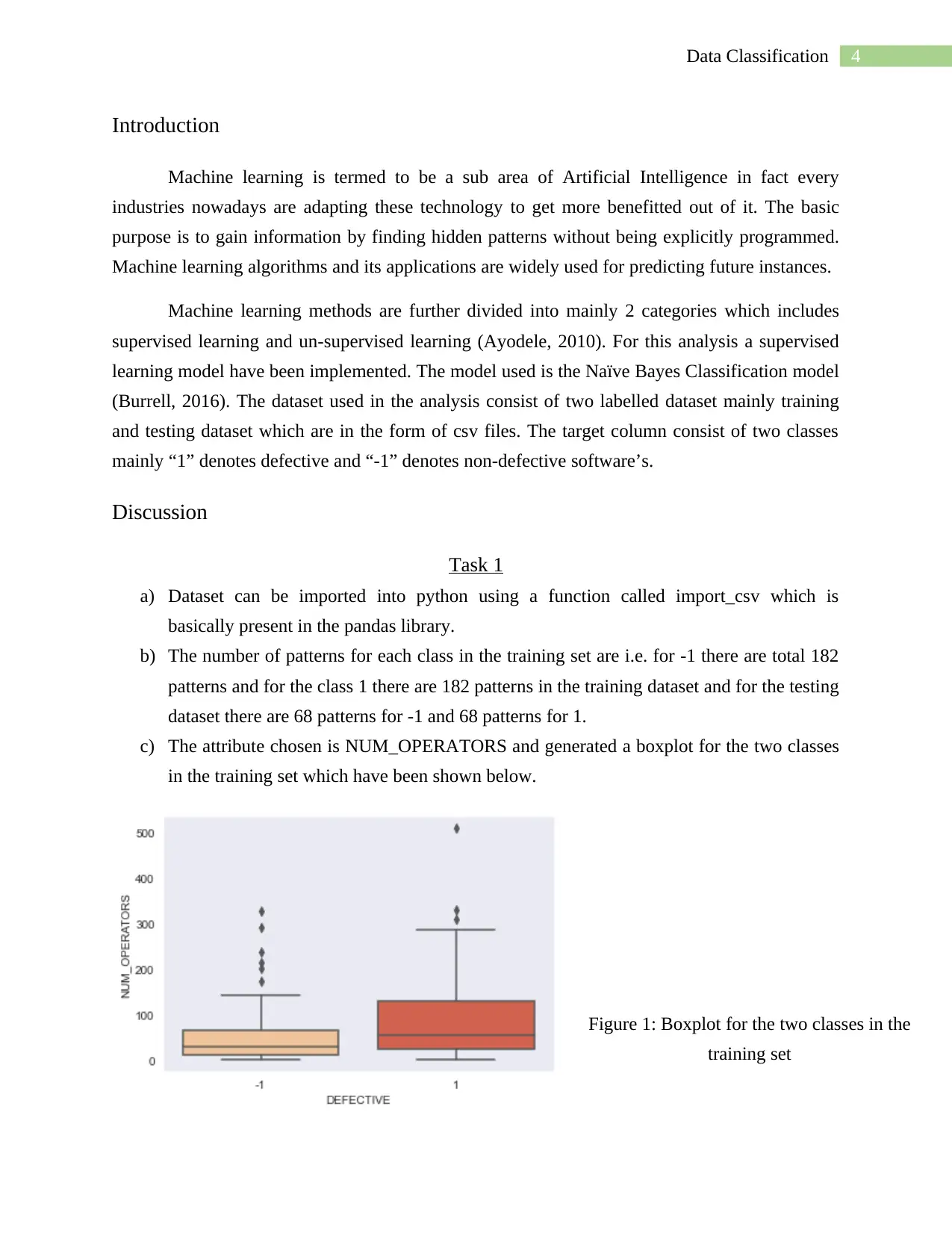
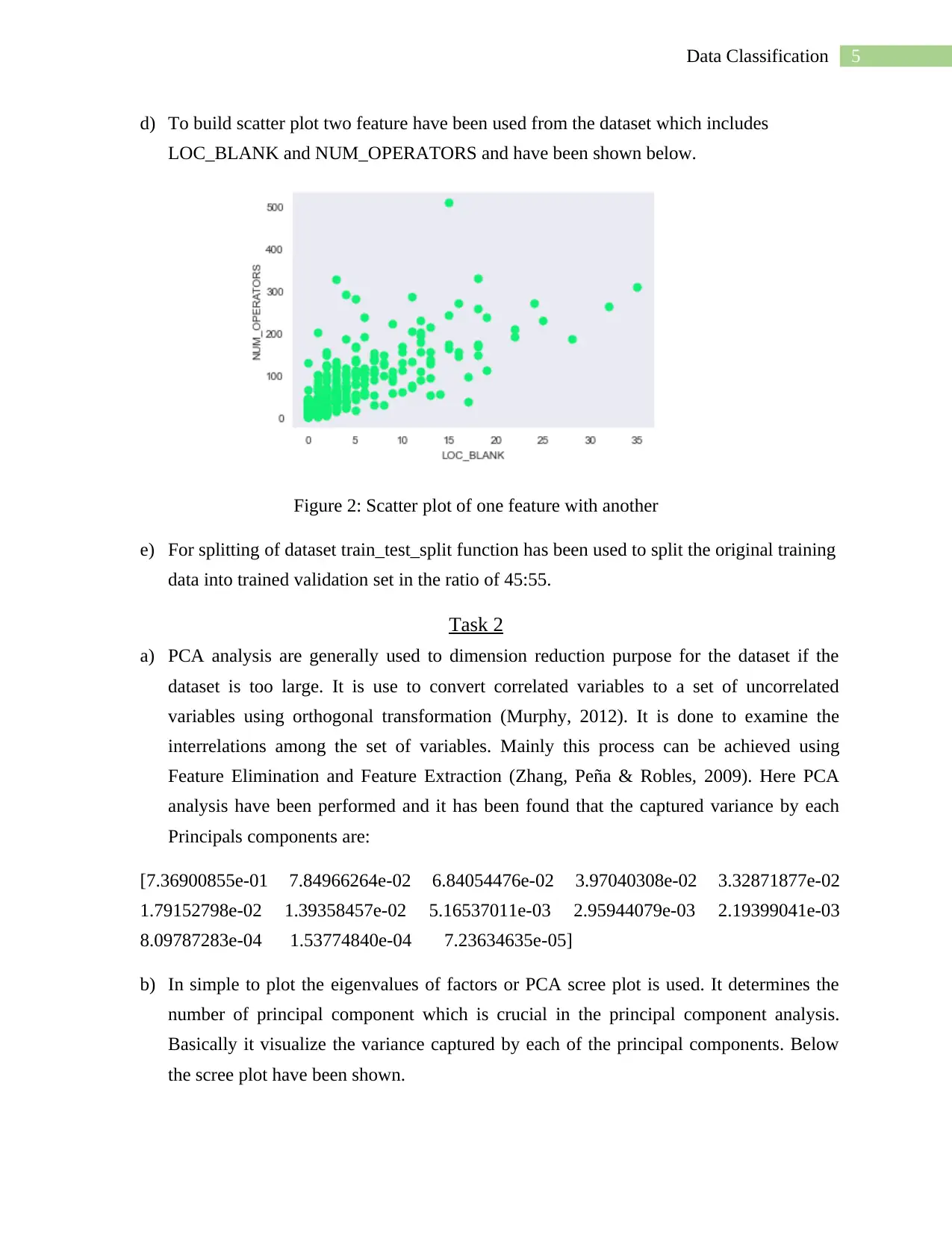
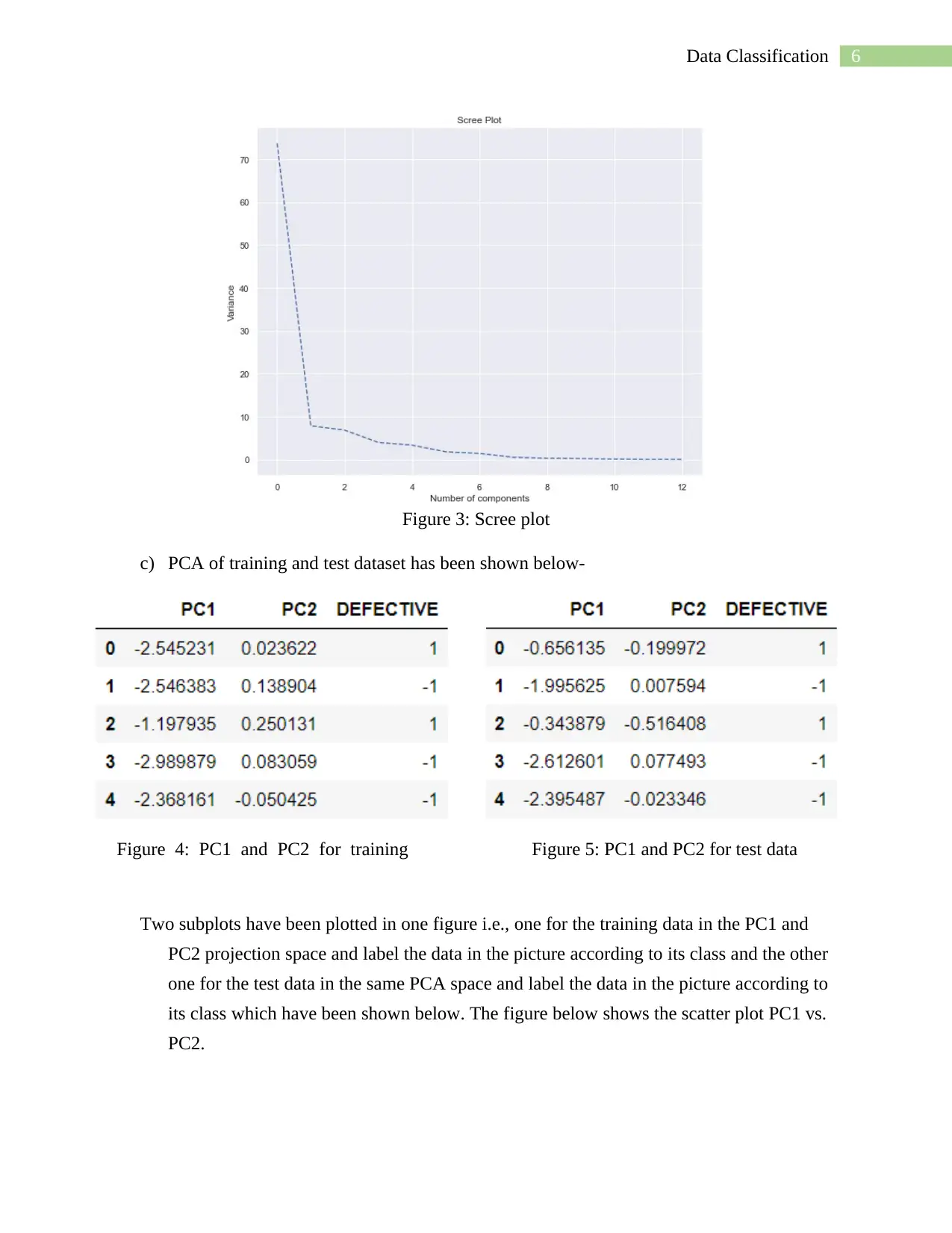
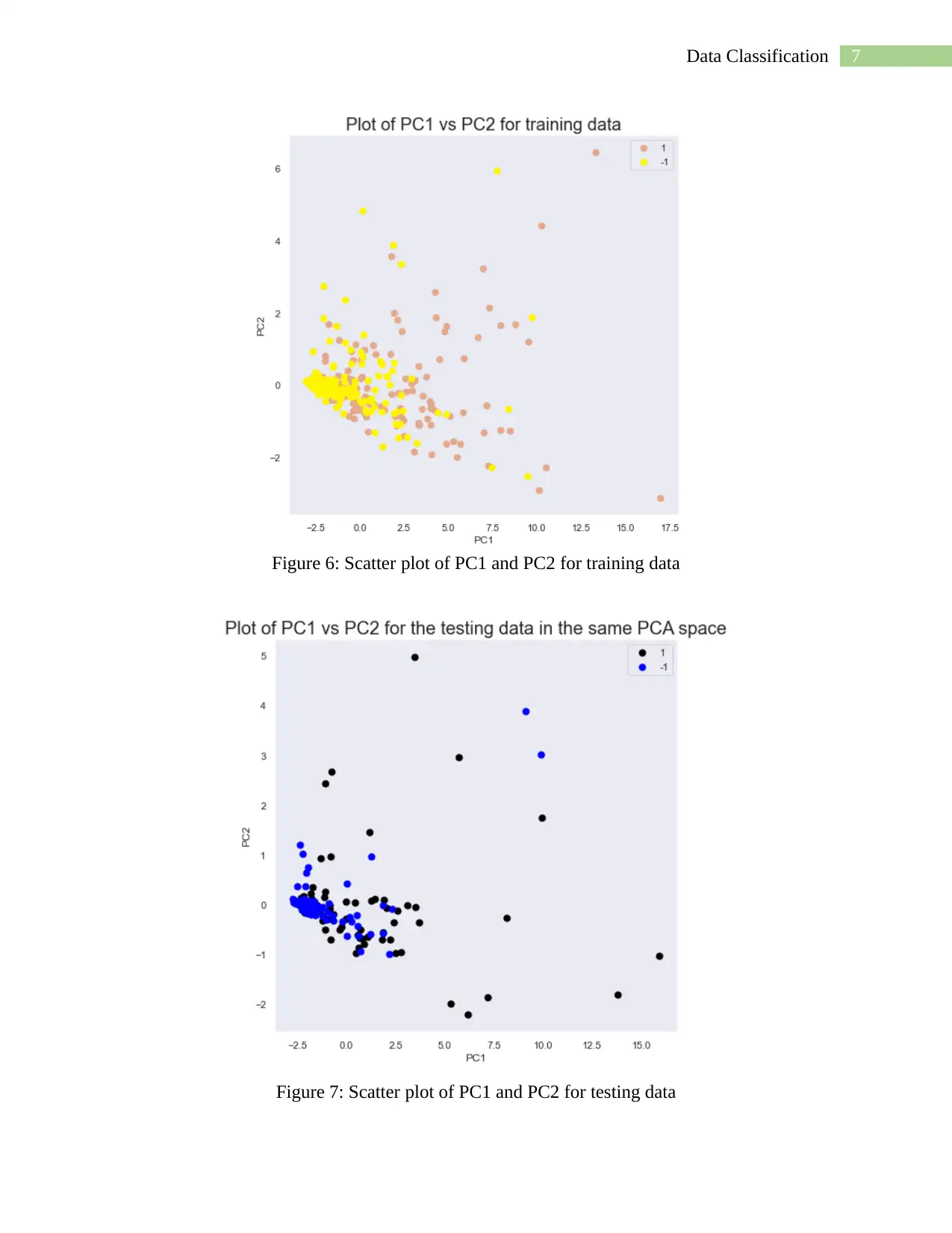
This project presents a comprehensive analysis of software defect prediction using machine learning techniques. The student implemented a Naive Bayes classification model to analyze a dataset containing static code metrics. The project includes data preprocessing, exploratory data analysis (EDA) with visualizations like boxplots and scatter plots, and dimensionality reduction using Principal Component Analysis (PCA). The analysis involved splitting the data into training and testing sets, building and evaluating the Naive Bayes model, and assessing its performance using accuracy, classification reports, and confusion matrices. The project also explored the impact of different features on model accuracy. The conclusion highlights the model's performance, the presence of outliers, and the importance of PCA for feature selection, along with suggestions for future improvements, such as employing other machine learning models and data preprocessing techniques to enhance the prediction accuracy. The project is a practical application of machine learning for software quality assessment.





1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.