Project: Analysis of South Australian Household Housing Stress Data
VerifiedAdded on 2022/08/26
|18
|1025
|11
Project
AI Summary
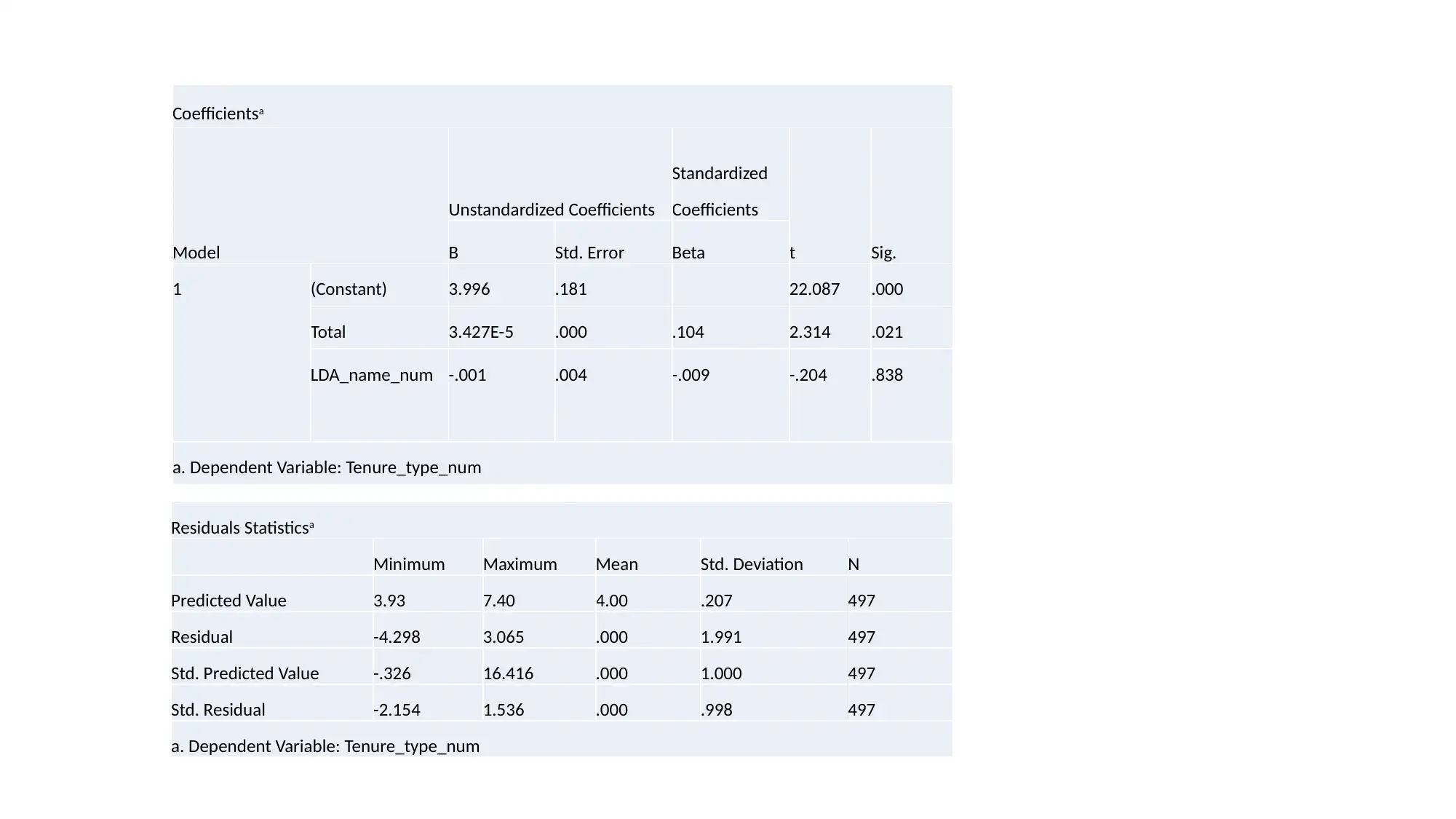
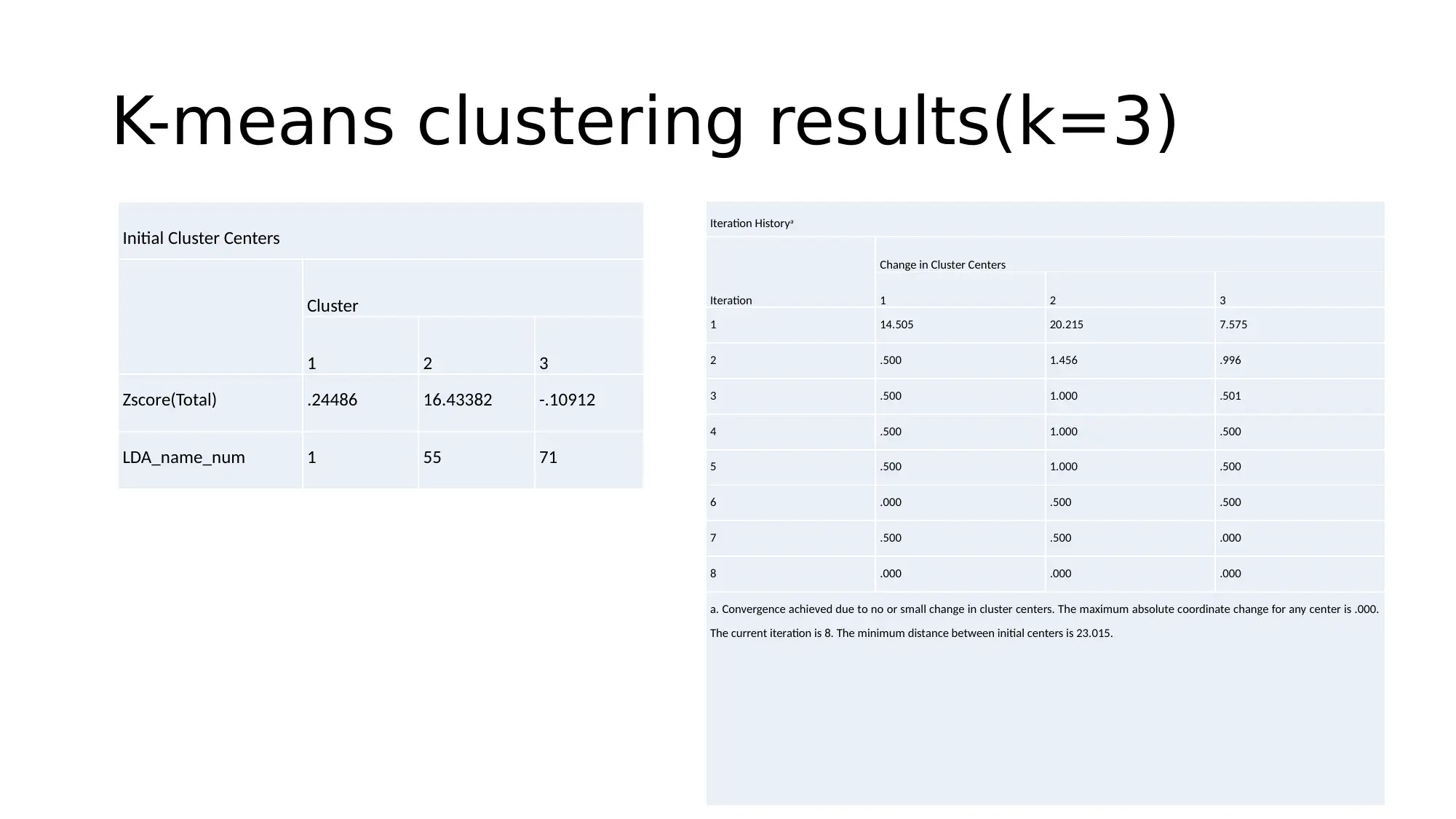
This project analyzes a dataset of South Australian households experiencing housing stress in 2018. The analysis focuses on three key variables: LGA names, tenure type, and the total number of households paying over 30% of their income on housing. The project employs both descriptive statistics and inferential methods, including linear regression and k-means clustering, to explore the relationships between these variables. The regression analysis investigates the dependency of tenure type on LGA names and total households, while the clustering approach groups tenure types based on the selected variables. The results suggest that tenure type has limited dependency on LGA names and that clustering provides a better prediction method for this dataset compared to linear regression. The project concludes with recommendations based on the statistical findings and suggests potential areas for further investigation.










1 out of 18

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.